 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmar Khattab
Backtracing: Retrieving the Cause of the Query
Mar 06, 2024
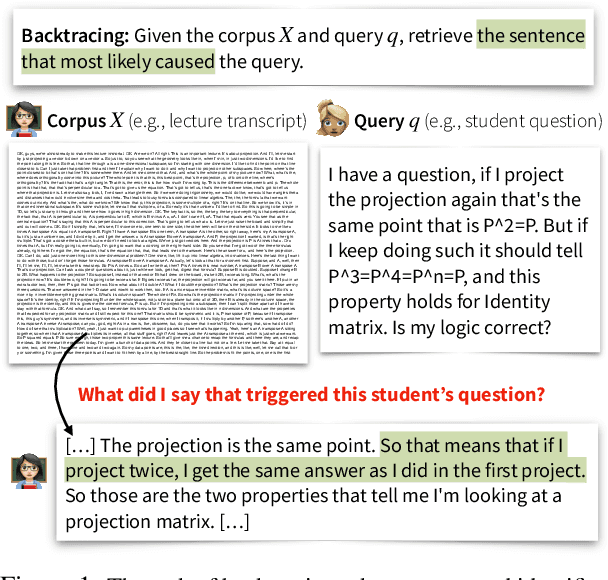
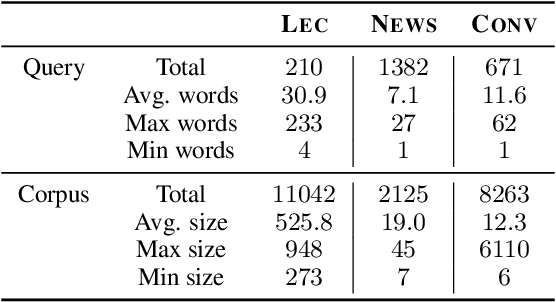

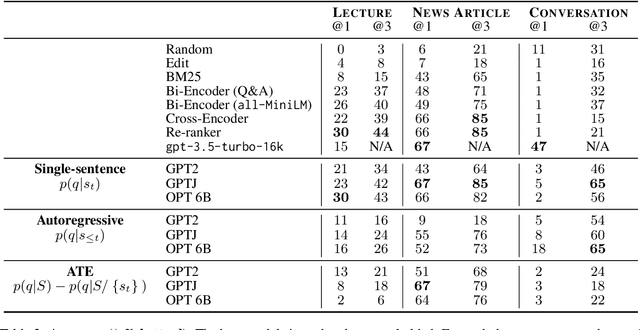
Many online content portals allow users to ask questions to supplement their understanding (e.g., of lectures). While information retrieval (IR) systems may provide answers for such user queries, they do not directly assist content creators -- such as lecturers who want to improve their content -- identify segments that _caused_ a user to ask those questions. We introduce the task of backtracing, in which systems retrieve the text segment that most likely caused a user query. We formalize three real-world domains for which backtracing is important in improving content delivery and communication: understanding the cause of (a) student confusion in the Lecture domain, (b) reader curiosity in the News Article domain, and (c) user emotion in the Conversation domain. We evaluate the zero-shot performance of popular information retrieval methods and language modeling methods, including bi-encoder, re-ranking and likelihood-based methods and ChatGPT. While traditional IR systems retrieve semantically relevant information (e.g., details on "projection matrices" for a query "does projecting multiple times still lead to the same point?"), they often miss the causally relevant context (e.g., the lecturer states "projecting twice gets me the same answer as one projection"). Our results show that there is room for improvement on backtracing and it requires new retrieval approaches. We hope our benchmark serves to improve future retrieval systems for backtracing, spawning systems that refine content generation and identify linguistic triggers influencing user queries. Our code and data are open-sourced: https://github.com/rosewang2008/backtracing.
Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models
Feb 22, 2024We study how to apply large language models to write grounded and organized long-form articles from scratch, with comparable breadth and depth to Wikipedia pages. This underexplored problem poses new challenges at the pre-writing stage, including how to research the topic and prepare an outline prior to writing. We propose STORM, a writing system for the Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking. STORM models the pre-writing stage by (1) discovering diverse perspectives in researching the given topic, (2) simulating conversations where writers carrying different perspectives pose questions to a topic expert grounded on trusted Internet sources, (3) curating the collected information to create an outline. For evaluation, we curate FreshWiki, a dataset of recent high-quality Wikipedia articles, and formulate outline assessments to evaluate the pre-writing stage. We further gather feedback from experienced Wikipedia editors. Compared to articles generated by an outline-driven retrieval-augmented baseline, more of STORM's articles are deemed to be organized (by a 25% absolute increase) and broad in coverage (by 10%). The expert feedback also helps identify new challenges for generating grounded long articles, such as source bias transfer and over-association of unrelated facts.
In-Context Learning for Extreme Multi-Label Classification
Jan 22, 2024Multi-label classification problems with thousands of classes are hard to solve with in-context learning alone, as language models (LMs) might lack prior knowledge about the precise classes or how to assign them, and it is generally infeasible to demonstrate every class in a prompt. We propose a general program, $\texttt{Infer--Retrieve--Rank}$, that defines multi-step interactions between LMs and retrievers to efficiently tackle such problems. We implement this program using the $\texttt{DSPy}$ programming model, which specifies in-context systems in a declarative manner, and use $\texttt{DSPy}$ optimizers to tune it towards specific datasets by bootstrapping only tens of few-shot examples. Our primary extreme classification program, optimized separately for each task, attains state-of-the-art results across three benchmarks (HOUSE, TECH, TECHWOLF). We apply the same program to a benchmark with vastly different characteristics and attain competitive performance as well (BioDEX). Unlike prior work, our proposed solution requires no finetuning, is easily applicable to new tasks, alleviates prompt engineering, and requires only tens of labeled examples. Our code is public at https://github.com/KarelDO/xmc.dspy.
Building Efficient and Effective OpenQA Systems for Low-Resource Languages
Jan 07, 2024Question answering (QA) is the task of answering questions posed in natural language with free-form natural language answers extracted from a given passage. In the OpenQA variant, only a question text is given, and the system must retrieve relevant passages from an unstructured knowledge source and use them to provide answers, which is the case in the mainstream QA systems on the Web. QA systems currently are mostly limited to the English language due to the lack of large-scale labeled QA datasets in non-English languages. In this paper, we show that effective, low-cost OpenQA systems can be developed for low-resource languages. The key ingredients are (1) weak supervision using machine-translated labeled datasets and (2) a relevant unstructured knowledge source in the target language. Furthermore, we show that only a few hundred gold assessment examples are needed to reliably evaluate these systems. We apply our method to Turkish as a challenging case study, since English and Turkish are typologically very distinct. We present SQuAD-TR, a machine translation of SQuAD2.0, and we build our OpenQA system by adapting ColBERT-QA for Turkish. We obtain a performance improvement of 9-34% in the EM score and 13-33% in the F1 score compared to the BM25-based and DPR-based baseline QA reader models by using two versions of Wikipedia dumps spanning two years. Our results show that SQuAD-TR makes OpenQA feasible for Turkish, which we hope encourages researchers to build OpenQA systems in other low-resource languages. We make all the code, models, and the dataset publicly available.
DSPy Assertions: Computational Constraints for Self-Refining Language Model Pipelines
Dec 20, 2023Chaining language model (LM) calls as composable modules is fueling a new powerful way of programming. However, ensuring that LMs adhere to important constraints remains a key challenge, one often addressed with heuristic "prompt engineering". We introduce LM Assertions, a new programming construct for expressing computational constraints that LMs should satisfy. We integrate our constructs into the recent DSPy programming model for LMs, and present new strategies that allow DSPy to compile programs with arbitrary LM Assertions into systems that are more reliable and more accurate. In DSPy, LM Assertions can be integrated at compile time, via automatic prompt optimization, and/or at inference time, via automatic selfrefinement and backtracking. We report on two early case studies for complex question answering (QA), in which the LM program must iteratively retrieve information in multiple hops and synthesize a long-form answer with citations. We find that LM Assertions improve not only compliance with imposed rules and guidelines but also enhance downstream task performance, delivering intrinsic and extrinsic gains up to 35.7% and 13.3%, respectively. Our reference implementation of LM Assertions is integrated into DSPy at https://github.com/stanfordnlp/dspy
Image and Data Mining in Reticular Chemistry Using GPT-4V
Dec 09, 2023The integration of artificial intelligence into scientific research has reached a new pinnacle with GPT-4V, a large language model featuring enhanced vision capabilities, accessible through ChatGPT or an API. This study demonstrates the remarkable ability of GPT-4V to navigate and obtain complex data for metal-organic frameworks, especially from graphical sources. Our approach involved an automated process of converting 346 scholarly articles into 6240 images, which represents a benchmark dataset in this task, followed by deploying GPT-4V to categorize and analyze these images using natural language prompts. This methodology enabled GPT-4V to accurately identify and interpret key plots integral to MOF characterization, such as nitrogen isotherms, PXRD patterns, and TGA curves, among others, with accuracy and recall above 93%. The model's proficiency in extracting critical information from these plots not only underscores its capability in data mining but also highlights its potential in aiding the creation of comprehensive digital databases for reticular chemistry. In addition, the extracted nitrogen isotherm data from the selected literature allowed for a comparison between theoretical and experimental porosity values for over 200 compounds, highlighting certain discrepancies and underscoring the importance of integrating computational and experimental data. This work highlights the potential of AI in accelerating scientific discovery and innovation, bridging the gap between computational tools and experimental research, and paving the way for more efficient, inclusive, and comprehensive scientific inquiry.
ARES: An Automated Evaluation Framework for Retrieval-Augmented Generation Systems
Nov 16, 2023Evaluating retrieval-augmented generation (RAG) systems traditionally relies on hand annotations for input queries, passages to retrieve, and responses to generate. We introduce ARES, an Automated RAG Evaluation System, for evaluating RAG systems along the dimensions of context relevance, answer faithfulness, and answer relevance. Using synthetic training data, ARES finetunes lightweight LM judges to assess the quality of individual RAG components. To mitigate potential prediction errors, ARES utilizes a small set of human-annotated datapoints for prediction-powered inference (PPI). Across six different knowledge-intensive tasks in KILT and SuperGLUE, ARES accurately evaluates RAG systems while using a few hundred human annotations during evaluation. Furthermore, ARES judges remain effective across domain shifts, proving accurate even after changing the type of queries and/or documents used in the evaluated RAG systems. We make our datasets and code for replication and deployment available at https://github.com/stanford-futuredata/ARES.
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Oct 05, 2023The ML community is rapidly exploring techniques for prompting language models (LMs) and for stacking them into pipelines that solve complex tasks. Unfortunately, existing LM pipelines are typically implemented using hard-coded "prompt templates", i.e. lengthy strings discovered via trial and error. Toward a more systematic approach for developing and optimizing LM pipelines, we introduce DSPy, a programming model that abstracts LM pipelines as text transformation graphs, i.e. imperative computational graphs where LMs are invoked through declarative modules. DSPy modules are parameterized, meaning they can learn (by creating and collecting demonstrations) how to apply compositions of prompting, finetuning, augmentation, and reasoning techniques. We design a compiler that will optimize any DSPy pipeline to maximize a given metric. We conduct two case studies, showing that succinct DSPy programs can express and optimize sophisticated LM pipelines that reason about math word problems, tackle multi-hop retrieval, answer complex questions, and control agent loops. Within minutes of compiling, a few lines of DSPy allow GPT-3.5 and llama2-13b-chat to self-bootstrap pipelines that outperform standard few-shot prompting (generally by over 25% and 65%, respectively) and pipelines with expert-created demonstrations (by up to 5-46% and 16-40%, respectively). On top of that, DSPy programs compiled to open and relatively small LMs like 770M-parameter T5 and llama2-13b-chat are competitive with approaches that rely on expert-written prompt chains for proprietary GPT-3.5. DSPy is available at https://github.com/stanfordnlp/dspy
Resources and Evaluations for Multi-Distribution Dense Information Retrieval
Jun 21, 2023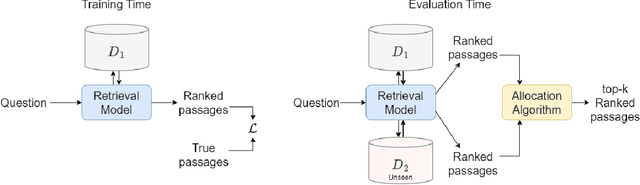

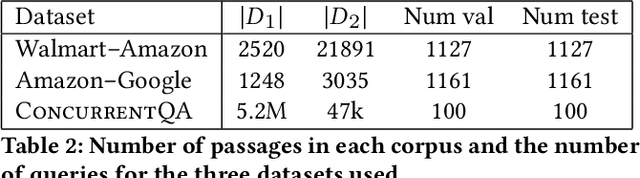
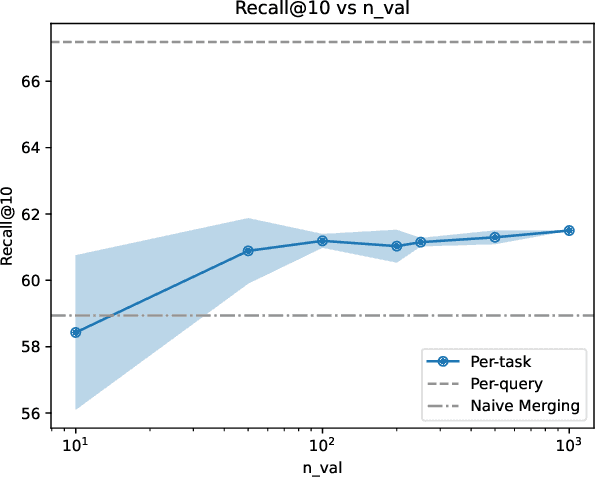
We introduce and define the novel problem of multi-distribution information retrieval (IR) where given a query, systems need to retrieve passages from within multiple collections, each drawn from a different distribution. Some of these collections and distributions might not be available at training time. To evaluate methods for multi-distribution retrieval, we design three benchmarks for this task from existing single-distribution datasets, namely, a dataset based on question answering and two based on entity matching. We propose simple methods for this task which allocate the fixed retrieval budget (top-k passages) strategically across domains to prevent the known domains from consuming most of the budget. We show that our methods lead to an average of 3.8+ and up to 8.0 points improvements in Recall@100 across the datasets and that improvements are consistent when fine-tuning different base retrieval models. Our benchmarks are made publicly available.
UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers
Mar 01, 2023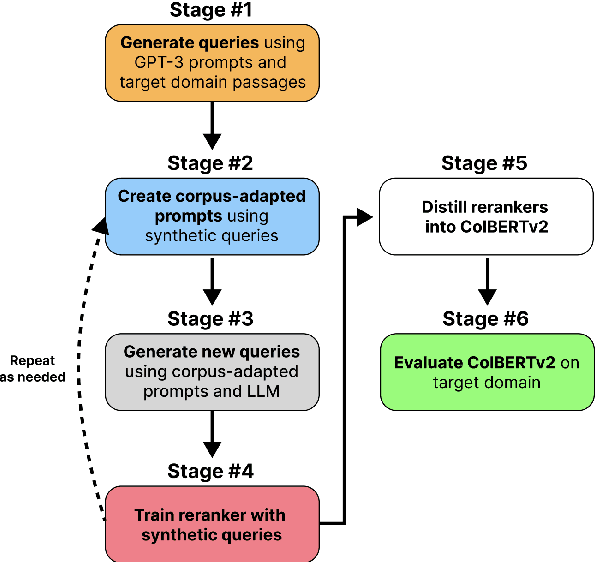
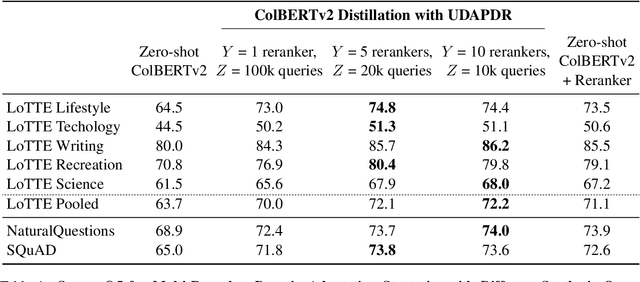


Many information retrieval tasks require large labeled datasets for fine-tuning. However, such datasets are often unavailable, and their utility for real-world applications can diminish quickly due to domain shifts. To address this challenge, we develop and motivate a method for using large language models (LLMs) to generate large numbers of synthetic queries cheaply. The method begins by generating a small number of synthetic queries using an expensive LLM. After that, a much less expensive one is used to create large numbers of synthetic queries, which are used to fine-tune a family of reranker models. These rerankers are then distilled into a single efficient retriever for use in the target domain. We show that this technique boosts zero-shot accuracy in long-tail domains, even where only 2K synthetic queries are used for fine-tuning, and that it achieves substantially lower latency than standard reranking methods. We make our end-to-end approach, including our synthetic datasets and replication code, publicly available on Github.