 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmar Peracha
JS Fake Chorales: a Synthetic Dataset of Polyphonic Music with Human Annotation
Aug 10, 2021
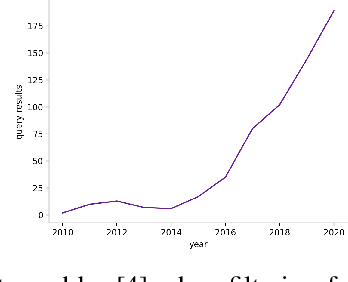
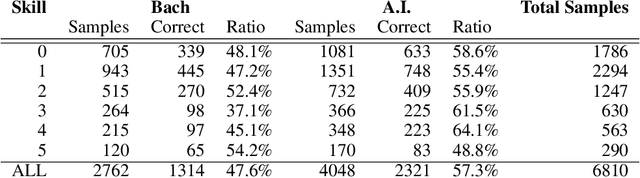
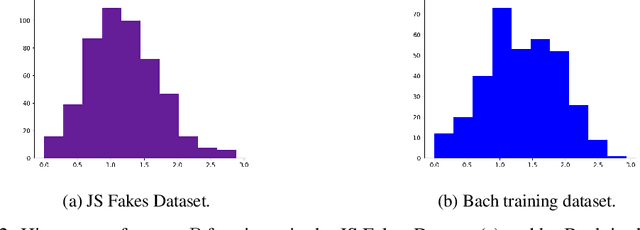
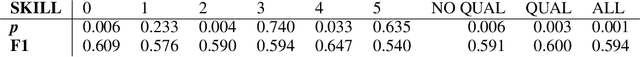
High quality datasets for learning-based modelling of polyphonic symbolic music remain less readily-accessible at scale than in other domains, such as language modelling or image classification. In particular, datasets which contain information revealing insights about human responses to the given music samples are rare. The issue of scale persists as a general hindrance towards breakthroughs in the field, while the lack of listener evaluation is especially relevant to the generative modelling problem-space, where clear objective metrics correlating strongly with qualitative success remain elusive. We propose the JS Fake Chorales, a dataset of 500 pieces generated by a new learning-based algorithm, provided in MIDI form. We take consecutive outputs from the algorithm and avoid cherry-picking in order to validate the potential to further scale this dataset on-demand. We conduct an online experiment for human evaluation, designed to be as fair to the listener as possible, and find that respondents were on average only 7% better than random guessing at distinguishing JS Fake Chorales from real chorales composed by JS Bach. Furthermore, we make anonymised data collected from experiments available along with the MIDI samples, such as the respondents' musical experience and how long they took to submit their response for each sample. Finally, we conduct ablation studies to demonstrate the effectiveness of using the synthetic pieces for research in polyphonic music modelling, and find that we can improve on state-of-the-art validation set loss for the canonical JSB Chorales dataset, using a known algorithm, by simply augmenting the training set with the JS Fake Chorales.
Improving Polyphonic Music Models with Feature-Rich Encoding
Nov 26, 2019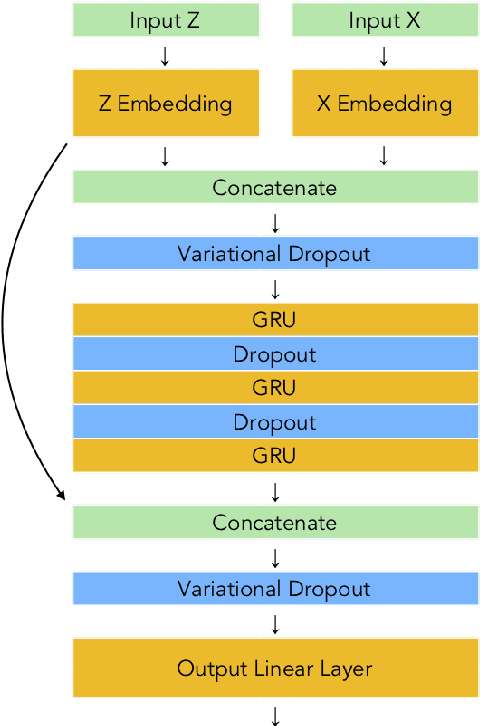
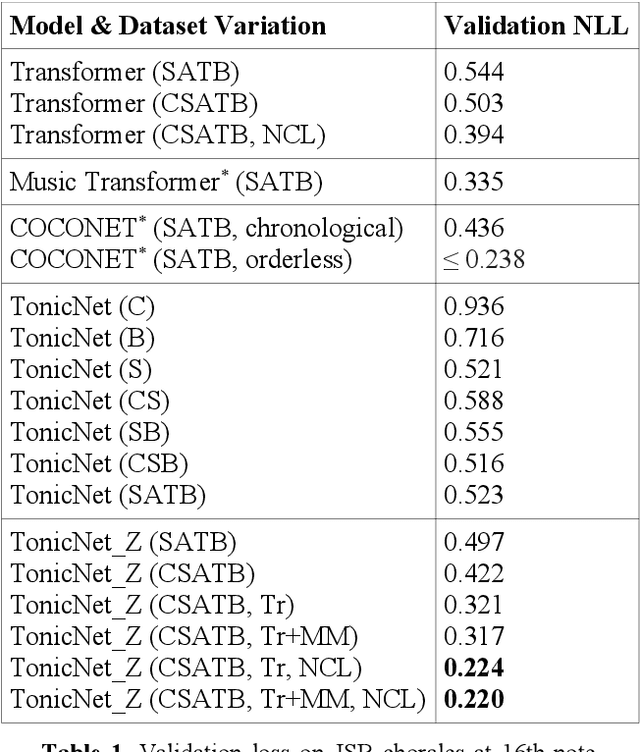
This paper explores sequential modeling of polyphonic music with deep neural networks. While recent breakthroughs have focussed on network architecture, we demonstrate that the representation of the sequence can make an equally significant contribution to the performance of the model as measured by validation set loss. By extracting salient features inherent to the dataset, the model can either be conditioned on these features or trained to predict said features as extra components of the sequences being modeled. We show that training a neural network to predict a seemingly more complex sequence, with extra features included in the series being modeled, can improve overall model performance significantly. We first introduce TonicNet, a GRU-based model trained to initially predict the chord at a given time-step before then predicting the notes of each voice at that time-step, in contrast with the typical approach of predicting only the notes. We then evaluate TonicNet on the canonical JSB Chorales dataset and obtain state-of-the-art results.
GANkyoku: a Generative Adversarial Network for Shakuhachi Music
Nov 22, 2019
A common approach to generating symbolic music using neural networks involves repeated sampling of an autoregressive model until the full output sequence is obtained. While such approaches have shown some promise in generating short sequences of music, this typically has not extended to cases where the final target sequence is significantly longer, for example an entire piece of music. In this work we propose a network trained in an adversarial process to generate entire pieces of solo shakuhachi music, in the form of symbolic notation. The pieces are intended to refer clearly to traditional shakuhachi music, maintaining idiomaticity and key aesthetic qualities, while also adding novel features, ultimately creating worthy additions to the contemporary shakuhachi repertoire. A key subproblem is also addressed, namely the lack of relevant training data readily available, in two steps: firstly, we introduce the PH_Shaku dataset for symbolic traditional shakuhachi music; secondly, we build on previous work using conditioning in generative adversarial networks to introduce a technique for data augmentation.