 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePadhraic Smyth
Dynamic Conditional Optimal Transport through Simulation-Free Flows
Apr 05, 2024
We study the geometry of conditional optimal transport (COT) and prove a dynamical formulation which generalizes the Benamou-Brenier Theorem. With these tools, we propose a simulation-free flow-based method for conditional generative modeling. Our method couples an arbitrary source distribution to a specified target distribution through a triangular COT plan. We build on the framework of flow matching to train a conditional generative model by approximating the geodesic path of measures induced by this COT plan. Our theory and methods are applicable in the infinite-dimensional setting, making them well suited for inverse problems. Empirically, we demonstrate our proposed method on two image-to-image translation tasks and an infinite-dimensional Bayesian inverse problem.
The Calibration Gap between Model and Human Confidence in Large Language Models
Jan 24, 2024For large language models (LLMs) to be trusted by humans they need to be well-calibrated in the sense that they can accurately assess and communicate how likely it is that their predictions are correct. Recent work has focused on the quality of internal LLM confidence assessments, but the question remains of how well LLMs can communicate this internal model confidence to human users. This paper explores the disparity between external human confidence in an LLM's responses and the internal confidence of the model. Through experiments involving multiple-choice questions, we systematically examine human users' ability to discern the reliability of LLM outputs. Our study focuses on two key areas: (1) assessing users' perception of true LLM confidence and (2) investigating the impact of tailored explanations on this perception. The research highlights that default explanations from LLMs often lead to user overestimation of both the model's confidence and its' accuracy. By modifying the explanations to more accurately reflect the LLM's internal confidence, we observe a significant shift in user perception, aligning it more closely with the model's actual confidence levels. This adjustment in explanatory approach demonstrates potential for enhancing user trust and accuracy in assessing LLM outputs. The findings underscore the importance of transparent communication of confidence levels in LLMs, particularly in high-stakes applications where understanding the reliability of AI-generated information is essential.
Probabilistic Modeling for Sequences of Sets in Continuous-Time
Jan 04, 2024Neural marked temporal point processes have been a valuable addition to the existing toolbox of statistical parametric models for continuous-time event data. These models are useful for sequences where each event is associated with a single item (a single type of event or a "mark") -- but such models are not suited for the practical situation where each event is associated with a set of items. In this work, we develop a general framework for modeling set-valued data in continuous-time, compatible with any intensity-based recurrent neural point process model. In addition, we develop inference methods that can use such models to answer probabilistic queries such as "the probability of item $A$ being observed before item $B$," conditioned on sequence history. Computing exact answers for such queries is generally intractable for neural models due to both the continuous-time nature of the problem setting and the combinatorially-large space of potential outcomes for each event. To address this, we develop a class of importance sampling methods for querying with set-based sequences and demonstrate orders-of-magnitude improvements in efficiency over direct sampling via systematic experiments with four real-world datasets. We also illustrate how to use this framework to perform model selection using likelihoods that do not involve one-step-ahead prediction.
Bayesian Online Learning for Consensus Prediction
Dec 12, 2023Given a pre-trained classifier and multiple human experts, we investigate the task of online classification where model predictions are provided for free but querying humans incurs a cost. In this practical but under-explored setting, oracle ground truth is not available. Instead, the prediction target is defined as the consensus vote of all experts. Given that querying full consensus can be costly, we propose a general framework for online Bayesian consensus estimation, leveraging properties of the multivariate hypergeometric distribution. Based on this framework, we propose a family of methods that dynamically estimate expert consensus from partial feedback by producing a posterior over expert and model beliefs. Analyzing this posterior induces an interpretable trade-off between querying cost and classification performance. We demonstrate the efficacy of our framework against a variety of baselines on CIFAR-10H and ImageNet-16H, two large-scale crowdsourced datasets.
Functional Flow Matching
May 26, 2023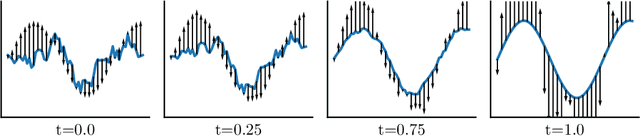

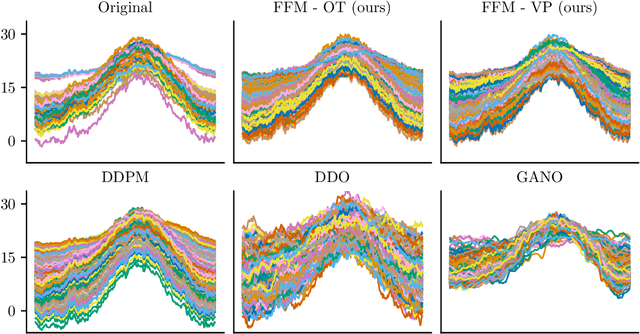
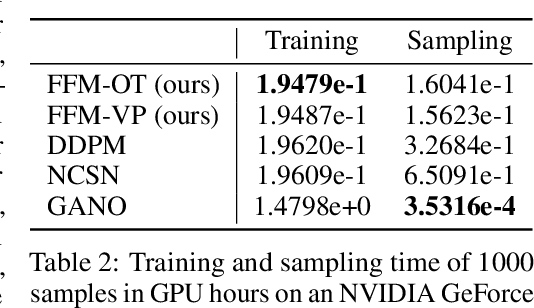
In this work, we propose Functional Flow Matching (FFM), a function-space generative model that generalizes the recently-introduced Flow Matching model to operate directly in infinite-dimensional spaces. Our approach works by first defining a path of probability measures that interpolates between a fixed Gaussian measure and the data distribution, followed by learning a vector field on the underlying space of functions that generates this path of measures. Our method does not rely on likelihoods or simulations, making it well-suited to the function space setting. We provide both a theoretical framework for building such models and an empirical evaluation of our techniques. We demonstrate through experiments on synthetic and real-world benchmarks that our proposed FFM method outperforms several recently proposed function-space generative models.
Capturing Humans' Mental Models of AI: An Item Response Theory Approach
May 15, 2023


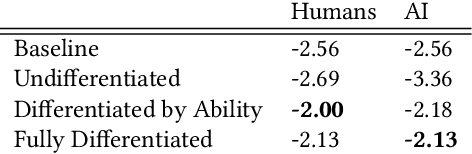
Improving our understanding of how humans perceive AI teammates is an important foundation for our general understanding of human-AI teams. Extending relevant work from cognitive science, we propose a framework based on item response theory for modeling these perceptions. We apply this framework to real-world experiments, in which each participant works alongside another person or an AI agent in a question-answering setting, repeatedly assessing their teammate's performance. Using this experimental data, we demonstrate the use of our framework for testing research questions about people's perceptions of both AI agents and other people. We contrast mental models of AI teammates with those of human teammates as we characterize the dimensionality of these mental models, their development over time, and the influence of the participants' own self-perception. Our results indicate that people expect AI agents' performance to be significantly better on average than the performance of other humans, with less variation across different types of problems. We conclude with a discussion of the implications of these findings for human-AI interaction.
Zero-Shot Anomaly Detection without Foundation Models
Feb 15, 2023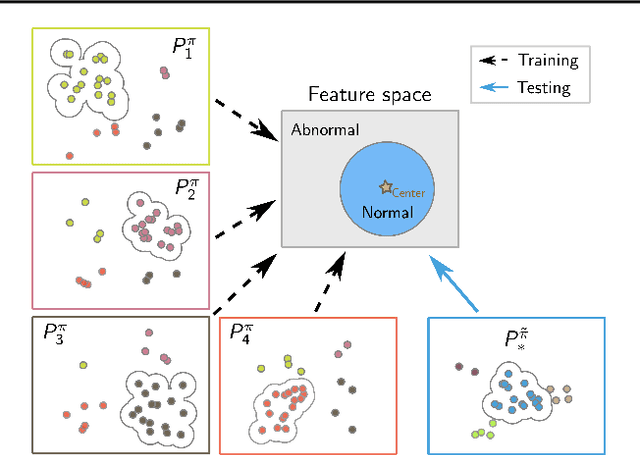
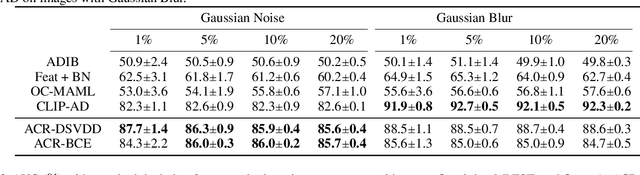
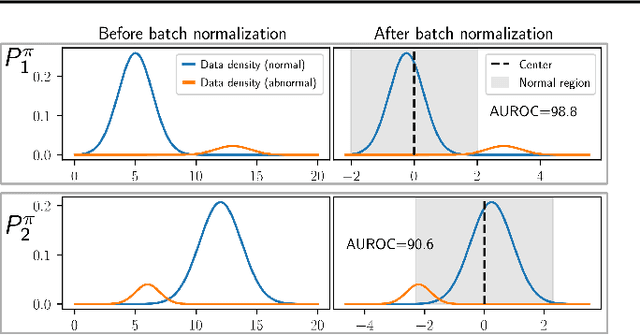
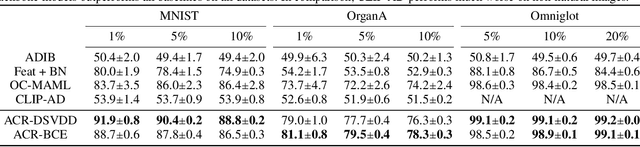
Anomaly detection (AD) tries to identify data instances that deviate from the norm in a given data set. Since data distributions are subject to distribution shifts, our concept of ``normality" may also drift, raising the need for zero-shot adaptation approaches for anomaly detection. However, the fact that current zero-shot AD methods rely on foundation models that are restricted in their domain (natural language and natural images), are costly, and oftentimes proprietary, asks for alternative approaches. In this paper, we propose a simple and highly effective zero-shot AD approach compatible with a variety of established AD methods. Our solution relies on training an off-the-shelf anomaly detector (such as a deep SVDD) on a set of inter-related data distributions in combination with batch normalization. This simple recipe--batch normalization plus meta-training--is a highly effective and versatile tool. Our results demonstrate the first zero-shot anomaly detection results for tabular data and SOTA zero-shot AD results for image data from specialized domains.
Deep Anomaly Detection under Labeling Budget Constraints
Feb 15, 2023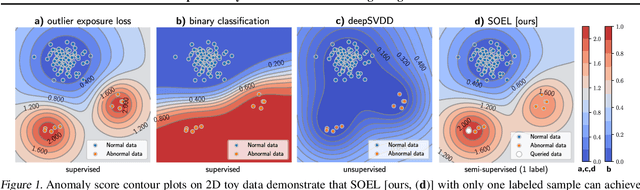

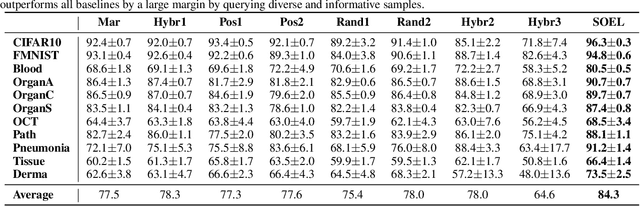
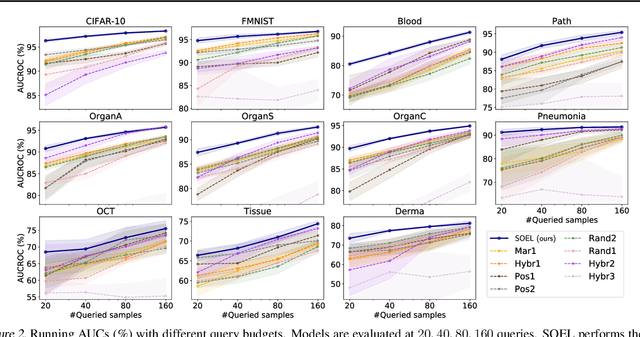
Selecting informative data points for expert feedback can significantly improve the performance of anomaly detection (AD) in various contexts, such as medical diagnostics or fraud detection. In this paper, we determine a set of theoretical conditions under which anomaly scores generalize from labeled queries to unlabeled data. Motivated by these results, we propose a data labeling strategy with optimal data coverage under labeling budget constraints. In addition, we propose a new learning framework for semi-supervised AD. Extensive experiments on image, tabular, and video data sets show that our approach results in state-of-the-art semi-supervised AD performance under labeling budget constraints.
Diffusion Generative Models in Infinite Dimensions
Dec 01, 2022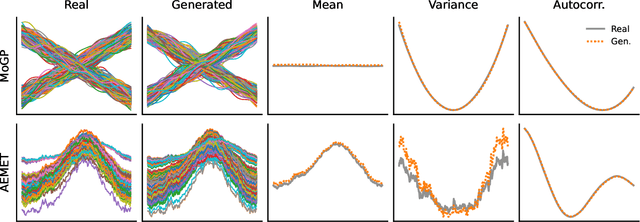

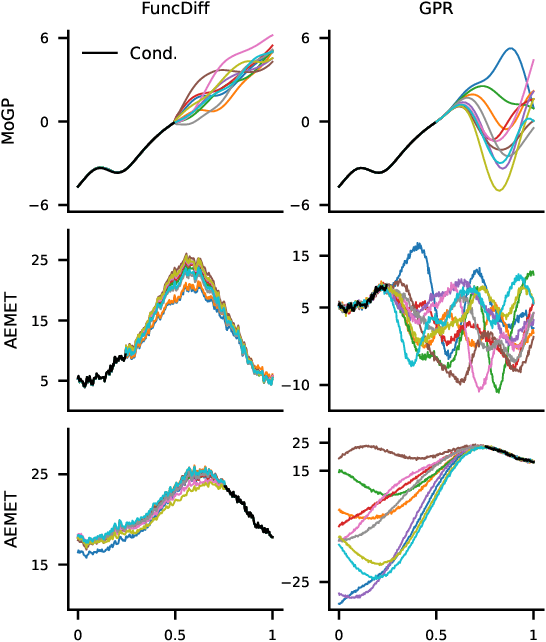
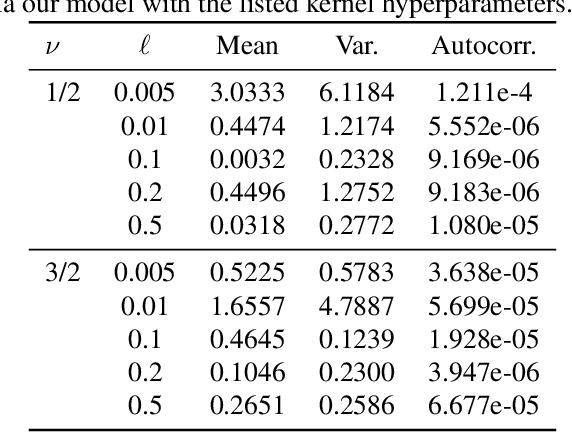
Diffusion generative models have recently been applied to domains where the available data can be seen as a discretization of an underlying function, such as audio signals or time series. However, these models operate directly on the discretized data, and there are no semantics in the modeling process that relate the observed data to the underlying functional forms. We generalize diffusion models to operate directly in function space by developing the foundational theory for such models in terms of Gaussian measures on Hilbert spaces. A significant benefit of our function space point of view is that it allows us to explicitly specify the space of functions we are working in, leading us to develop methods for diffusion generative modeling in Sobolev spaces. Our approach allows us to perform both unconditional and conditional generation of function-valued data. We demonstrate our methods on several synthetic and real-world benchmarks.
Probabilistic Querying of Continuous-Time Event Sequences
Nov 15, 2022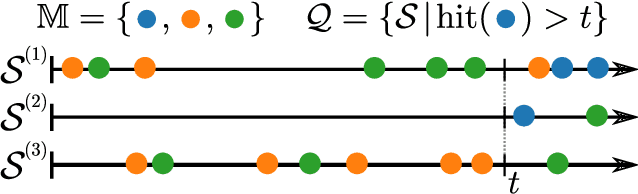


Continuous-time event sequences, i.e., sequences consisting of continuous time stamps and associated event types ("marks"), are an important type of sequential data with many applications, e.g., in clinical medicine or user behavior modeling. Since these data are typically modeled autoregressively (e.g., using neural Hawkes processes or their classical counterparts), it is natural to ask questions about future scenarios such as "what kind of event will occur next" or "will an event of type $A$ occur before one of type $B$". Unfortunately, some of these queries are notoriously hard to address since current methods are limited to naive simulation, which can be highly inefficient. This paper introduces a new typology of query types and a framework for addressing them using importance sampling. Example queries include predicting the $n^\text{th}$ event type in a sequence and the hitting time distribution of one or more event types. We also leverage these findings further to be applicable for estimating general "$A$ before $B$" type of queries. We prove theoretically that our estimation method is effectively always better than naive simulation and show empirically based on three real-world datasets that it is on average 1,000 times more efficient than existing approaches.