 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanwen Hu
Towards Balanced RGB-TSDF Fusion for Consistent Semantic Scene Completion by 3D RGB Feature Completion and a Classwise Entropy Loss Function
Mar 25, 2024
Semantic Scene Completion (SSC) aims to jointly infer semantics and occupancies of 3D scenes. Truncated Signed Distance Function (TSDF), a 3D encoding of depth, has been a common input for SSC. Furthermore, RGB-TSDF fusion, seems promising since these two modalities provide color and geometry information, respectively. Nevertheless, RGB-TSDF fusion has been considered nontrivial and commonly-used naive addition will result in inconsistent results. We argue that the inconsistency comes from the sparsity of RGB features upon projecting into 3D space, while TSDF features are dense, leading to imbalanced feature maps when summed up. To address this RGB-TSDF distribution difference, we propose a two-stage network with a 3D RGB feature completion module that completes RGB features with meaningful values for occluded areas. Moreover, we propose an effective classwise entropy loss function to punish inconsistency. Extensive experiments on public datasets verify that our method achieves state-of-the-art performance among methods that do not adopt extra data.
DreamVideo: High-Fidelity Image-to-Video Generation with Image Retention and Text Guidance
Dec 05, 2023Image-to-video generation, which aims to generate a video starting from a given reference image, has drawn great attention. Existing methods try to extend pre-trained text-guided image diffusion models to image-guided video generation models. Nevertheless, these methods often result in either low fidelity or flickering over time due to their limitation to shallow image guidance and poor temporal consistency. To tackle these problems, we propose a high-fidelity image-to-video generation method by devising a frame retention branch on the basis of a pre-trained video diffusion model, named DreamVideo. Instead of integrating the reference image into the diffusion process in a semantic level, our DreamVideo perceives the reference image via convolution layers and concatenate the features with the noisy latents as model input. By this means, the details of the reference image can be preserved to the greatest extent. In addition, by incorporating double-condition classifier-free guidance, a single image can be directed to videos of different actions by providing varying prompt texts. This has significant implications for controllable video generation and holds broad application prospects. We conduct comprehensive experiments on the public dataset, both quantitative and qualitative results indicate that our method outperforms the state-of-the-art method. Especially for fidelity, our model has powerful image retention ability and result in high FVD in UCF101 compared to other image-to-video models. Also, precise control can be achieved by giving different text prompts. Further details and comprehensive results of our model will be presented in https://anonymous0769.github.io/DreamVideo/.
Concentrated Multi-Grained Multi-Attention Network for Video Based Person Re-Identification
Sep 28, 2020


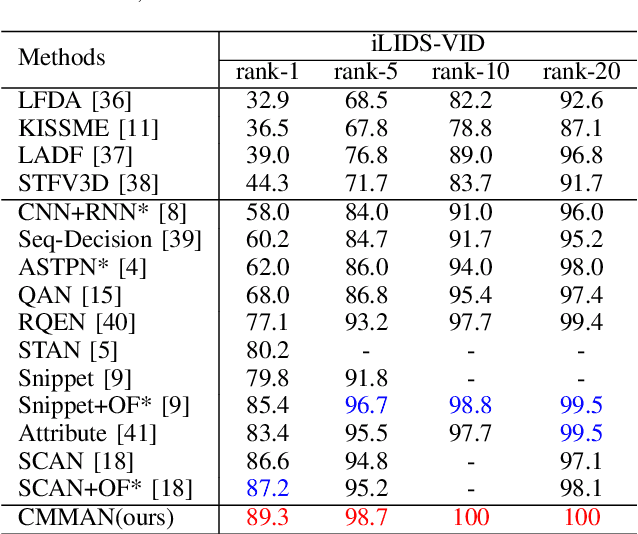
Occlusion is still a severe problem in the video-based Re-IDentification (Re-ID) task, which has a great impact on the success rate. The attention mechanism has been proved to be helpful in solving the occlusion problem by a large number of existing methods. However, their attention mechanisms still lack the capability to extract sufficient discriminative information into the final representations from the videos. The single attention module scheme employed by existing methods cannot exploit multi-scale spatial cues, and the attention of the single module will be dispersed by multiple salient parts of the person. In this paper, we propose a Concentrated Multi-grained Multi-Attention Network (CMMANet) where two multi-attention modules are designed to extract multi-grained information through processing multi-scale intermediate features. Furthermore, multiple attention submodules in each multi-attention module can automatically discover multiple discriminative regions of the video frames. To achieve this goal, we introduce a diversity loss to diversify the submodules in each multi-attention module, and a concentration loss to integrate their attention responses so that each submodule can strongly focus on a specific meaningful part. The experimental results show that the proposed approach outperforms the state-of-the-art methods by large margins on multiple public datasets.
How Effectively Can Indoor Wireless Positioning Relieve Visual Tracking Pains: A Camera-Rao Bound Viewpoint
Mar 09, 2019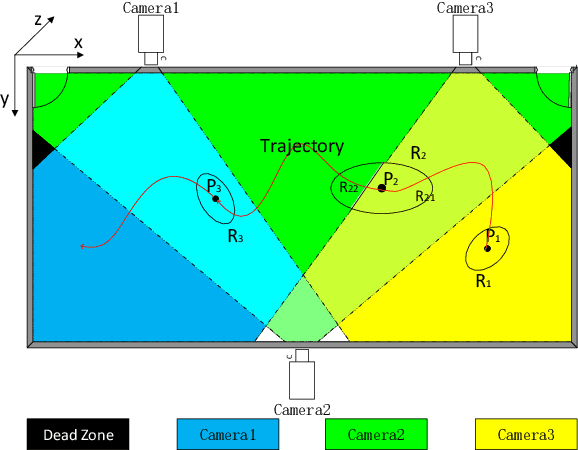


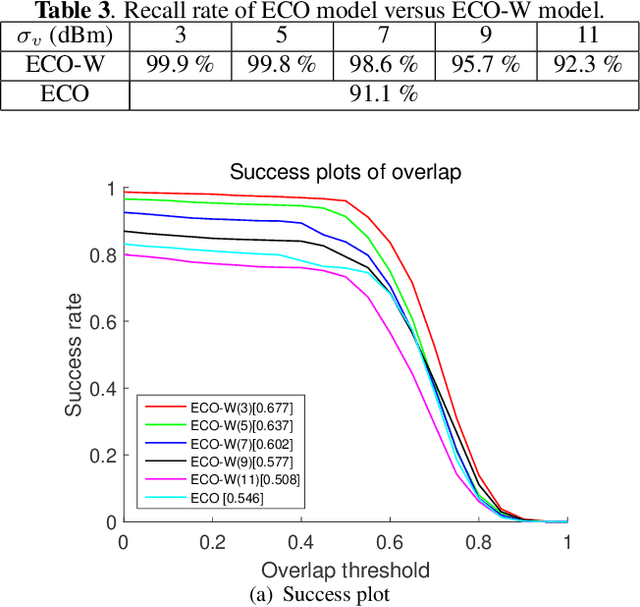
Visual tracking is fragile in some difficult scenarios, for instance, appearance ambiguity and variation, occlusion can easily degrade most of visual trackers to some extent. In this paper, visual tracking is empowered with wireless positioning to achieve high accuracy while maintaining robustness. Fundamentally different from the previous works, this study does not involve any specific wireless positioning algorithms. Instead, we use the confidence region derived from the wireless positioning Cramer-Rao bound (CRB) as the search region of visual trackers. The proposed framework is low-cost and very simple to implement, yet readily leads to enhanced and robustified visual tracking performance in difficult scenarios as corroborated by our experimental results. Most importantly, it is utmost valuable for the practioners to pre-evaluate how effectively can the wireless resources available at hand alleviate the visual tracking pains.