 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatrick Gallinari
ML4PhySim : Machine Learning for Physical Simulations Challenge (The airfoil design)
Mar 03, 2024



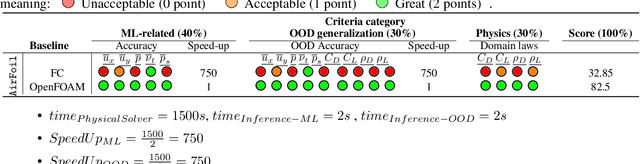
The use of machine learning (ML) techniques to solve complex physical problems has been considered recently as a promising approach. However, the evaluation of such learned physical models remains an important issue for industrial use. The aim of this competition is to encourage the development of new ML techniques to solve physical problems using a unified evaluation framework proposed recently, called Learning Industrial Physical Simulations (LIPS). We propose learning a task representing a well-known physical use case: the airfoil design simulation, using a dataset called AirfRANS. The global score calculated for each submitted solution is based on three main categories of criteria covering different aspects, namely: ML-related, Out-Of-Distribution, and physical compliance criteria. To the best of our knowledge, this is the first competition addressing the use of ML-based surrogate approaches to improve the trade-off computational cost/accuracy of physical simulation.The competition is hosted by the Codabench platform with online training and evaluation of all submitted solutions.
LOCOST: State-Space Models for Long Document Abstractive Summarization
Jan 31, 2024State-space models are a low-complexity alternative to transformers for encoding long sequences and capturing long-term dependencies. We propose LOCOST: an encoder-decoder architecture based on state-space models for conditional text generation with long context inputs. With a computational complexity of $O(L \log L)$, this architecture can handle significantly longer sequences than state-of-the-art models that are based on sparse attention patterns. We evaluate our model on a series of long document abstractive summarization tasks. The model reaches a performance level that is 93-96% comparable to the top-performing sparse transformers of the same size while saving up to 50% memory during training and up to 87% during inference. Additionally, LOCOST effectively handles input texts exceeding 600K tokens at inference time, setting new state-of-the-art results on full-book summarization and opening new perspectives for long input processing.
Module-wise Training of Neural Networks via the Minimizing Movement Scheme
Oct 05, 2023Greedy layer-wise or module-wise training of neural networks is compelling in constrained and on-device settings where memory is limited, as it circumvents a number of problems of end-to-end back-propagation. However, it suffers from a stagnation problem, whereby early layers overfit and deeper layers stop increasing the test accuracy after a certain depth. We propose to solve this issue by introducing a module-wise regularization inspired by the minimizing movement scheme for gradient flows in distribution space. We call the method TRGL for Transport Regularized Greedy Learning and study it theoretically, proving that it leads to greedy modules that are regular and that progressively solve the task. Experimentally, we show improved accuracy of module-wise training of various architectures such as ResNets, Transformers and VGG, when our regularization is added, superior to that of other module-wise training methods and often to end-to-end training, with as much as 60% less memory usage.
INFINITY: Neural Field Modeling for Reynolds-Averaged Navier-Stokes Equations
Jul 25, 2023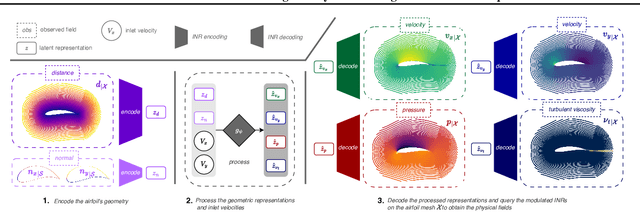
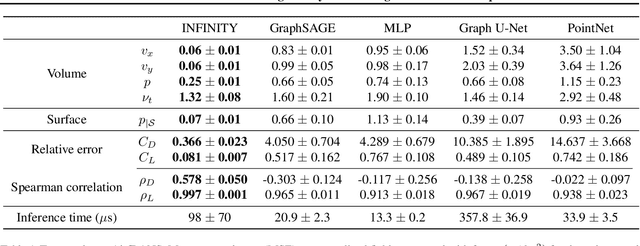
For numerical design, the development of efficient and accurate surrogate models is paramount. They allow us to approximate complex physical phenomena, thereby reducing the computational burden of direct numerical simulations. We propose INFINITY, a deep learning model that utilizes implicit neural representations (INRs) to address this challenge. Our framework encodes geometric information and physical fields into compact representations and learns a mapping between them to infer the physical fields. We use an airfoil design optimization problem as an example task and we evaluate our approach on the challenging AirfRANS dataset, which closely resembles real-world industrial use-cases. The experimental results demonstrate that our framework achieves state-of-the-art performance by accurately inferring physical fields throughout the volume and surface. Additionally we demonstrate its applicability in contexts such as design exploration and shape optimization: our model can correctly predict drag and lift coefficients while adhering to the equations.
* ICML 2023 Workshop on Synergy of Scientific and Machine Learning Modeling
Operator Learning with Neural Fields: Tackling PDEs on General Geometries
Jun 12, 2023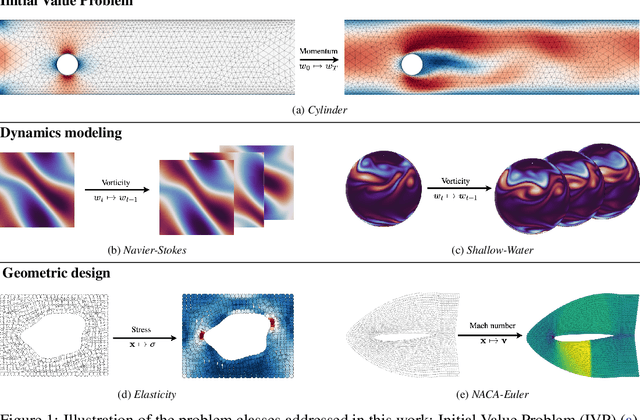
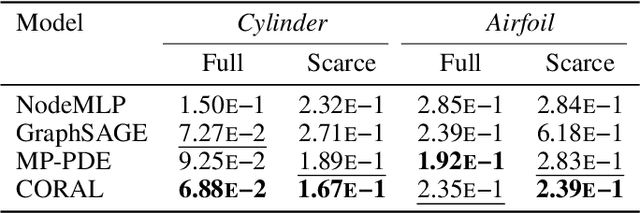
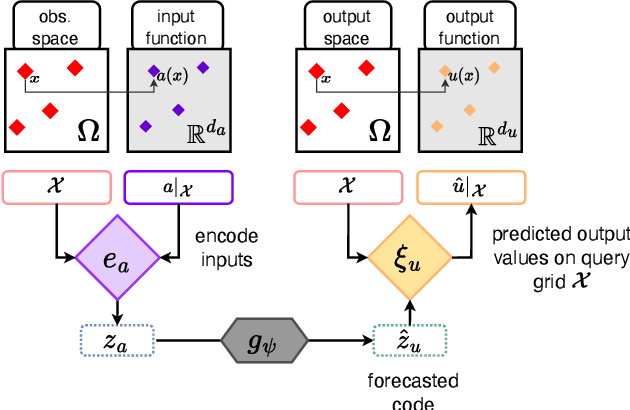
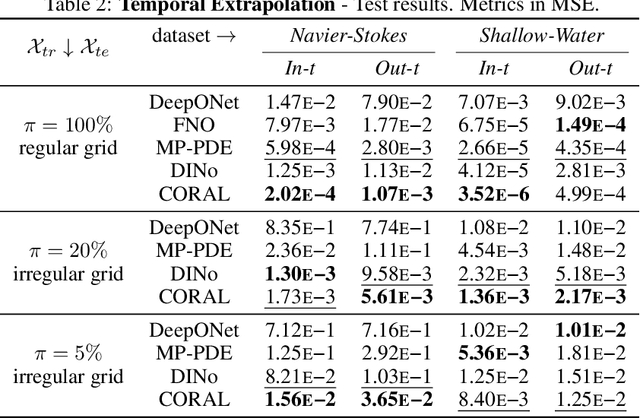
Machine learning approaches for solving partial differential equations require learning mappings between function spaces. While convolutional or graph neural networks are constrained to discretized functions, neural operators present a promising milestone toward mapping functions directly. Despite impressive results they still face challenges with respect to the domain geometry and typically rely on some form of discretization. In order to alleviate such limitations, we present CORAL, a new method that leverages coordinate-based networks for solving PDEs on general geometries. CORAL is designed to remove constraints on the input mesh, making it applicable to any spatial sampling and geometry. Its ability extends to diverse problem domains, including PDE solving, spatio-temporal forecasting, and inverse problems like geometric design. CORAL demonstrates robust performance across multiple resolutions and performs well in both convex and non-convex domains, surpassing or performing on par with state-of-the-art models.
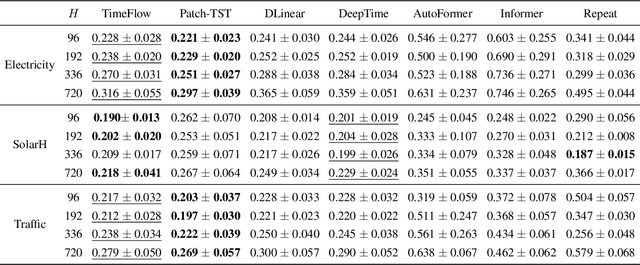
Time Series Continuous Modeling for Imputation and Forecasting with Implicit Neural Representations
Jun 12, 2023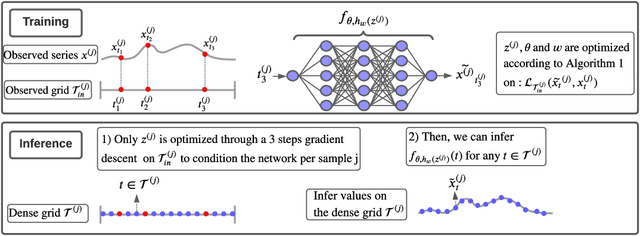
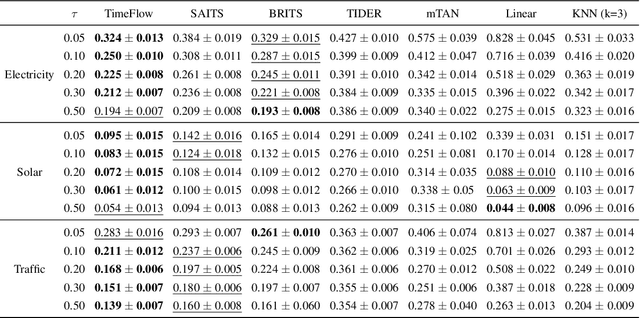
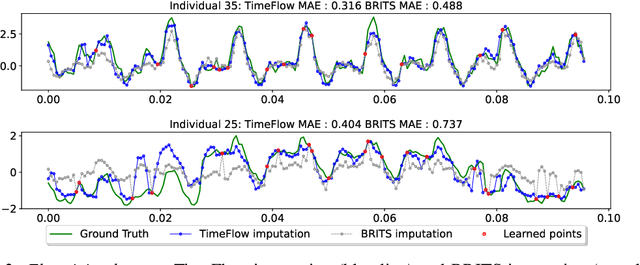
Although widely explored, time series modeling continues to encounter significant challenges when confronted with real-world data. We propose a novel modeling approach leveraging Implicit Neural Representations (INR). This approach enables us to effectively capture the continuous aspect of time series and provides a natural solution to recurring modeling issues such as handling missing data, dealing with irregular sampling, or unaligned observations from multiple sensors. By introducing conditional modulation of INR parameters and leveraging meta-learning techniques, we address the issue of generalization to both unseen samples and time window shifts. Through extensive experimentation, our model demonstrates state-of-the-art performance in forecasting and imputation tasks, while exhibiting flexibility in handling a wide range of challenging scenarios that competing models cannot.
Stability of implicit neural networks for long-term forecasting in dynamical systems
Jun 08, 2023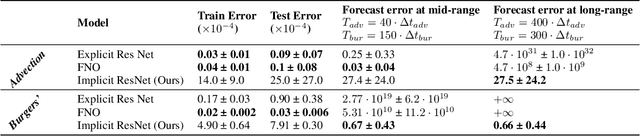
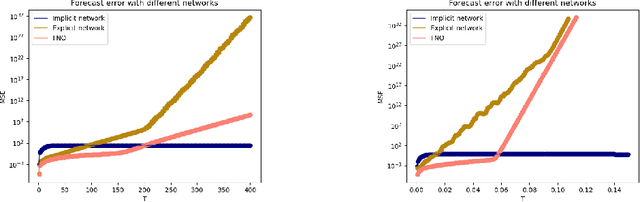
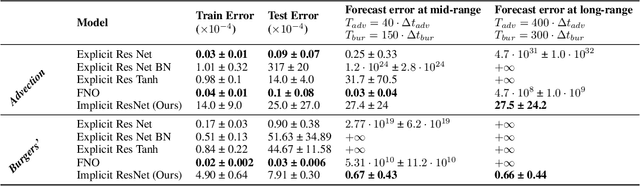
Forecasting physical signals in long time range is among the most challenging tasks in Partial Differential Equations (PDEs) research. To circumvent limitations of traditional solvers, many different Deep Learning methods have been proposed. They are all based on auto-regressive methods and exhibit stability issues. Drawing inspiration from the stability property of implicit numerical schemes, we introduce a stable auto-regressive implicit neural network. We develop a theory based on the stability definition of schemes to ensure the stability in forecasting of this network. It leads us to introduce hard constraints on its weights and propagate the dynamics in the latent space. Our experimental results validate our stability property, and show improved results at long-term forecasting for two transports PDEs.
Adversarial Sample Detection Through Neural Network Transport Dynamics
Jun 08, 2023

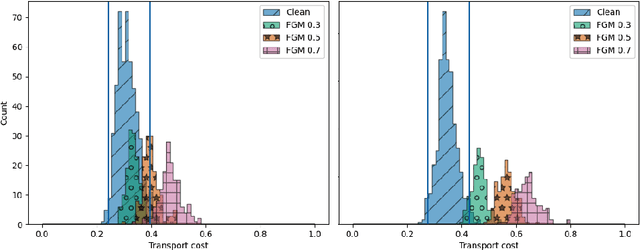
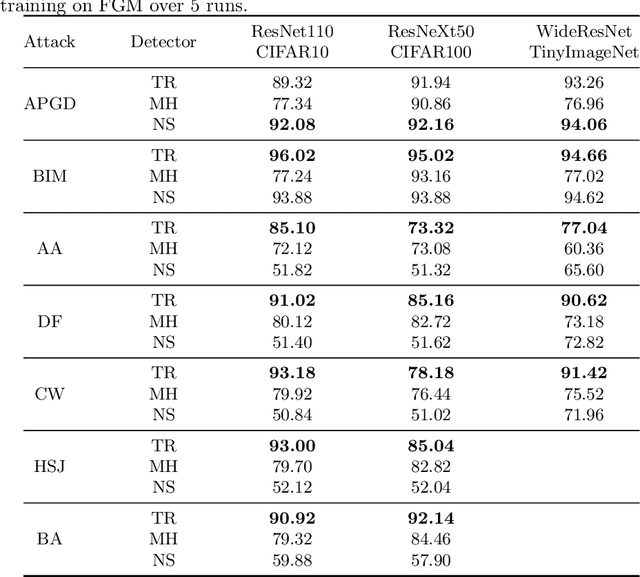
We propose a detector of adversarial samples that is based on the view of neural networks as discrete dynamic systems. The detector tells clean inputs from abnormal ones by comparing the discrete vector fields they follow through the layers. We also show that regularizing this vector field during training makes the network more regular on the data distribution's support, thus making the activations of clean inputs more distinguishable from those of abnormal ones. Experimentally, we compare our detector favorably to other detectors on seen and unseen attacks, and show that the regularization of the network's dynamics improves the performance of adversarial detectors that use the internal embeddings as inputs, while also improving test accuracy.
Learning from Multiple Sources for Data-to-Text and Text-to-Data
Feb 22, 2023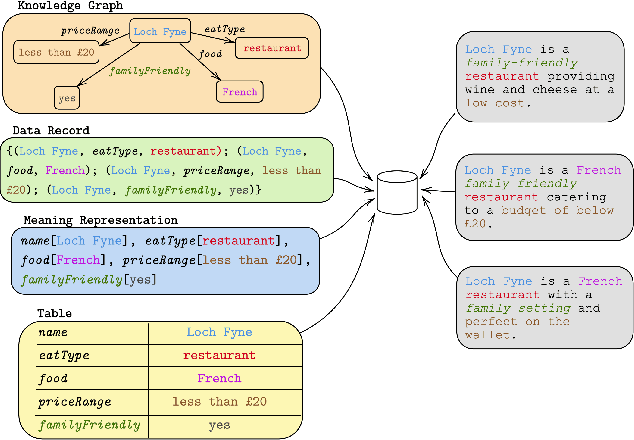
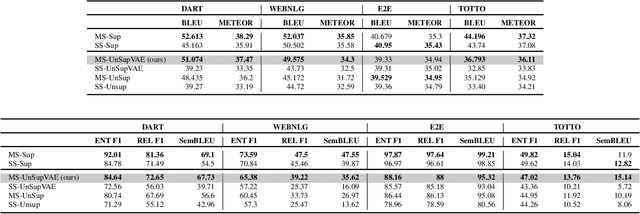
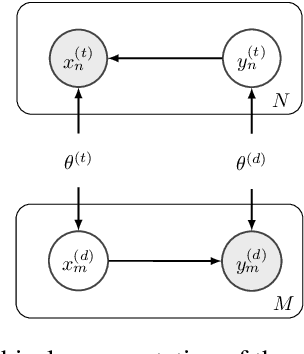
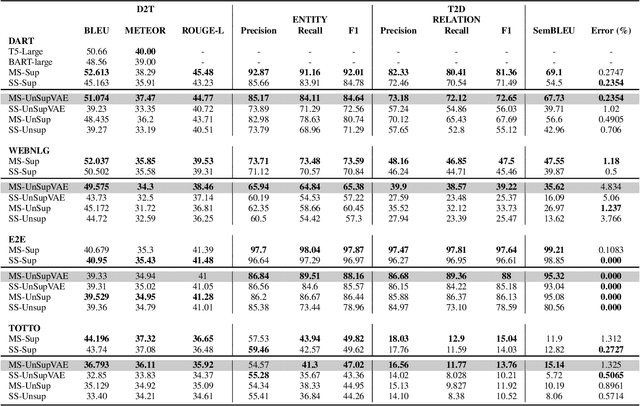
Data-to-text (D2T) and text-to-data (T2D) are dual tasks that convert structured data, such as graphs or tables into fluent text, and vice versa. These tasks are usually handled separately and use corpora extracted from a single source. Current systems leverage pre-trained language models fine-tuned on D2T or T2D tasks. This approach has two main limitations: first, a separate system has to be tuned for each task and source; second, learning is limited by the scarcity of available corpora. This paper considers a more general scenario where data are available from multiple heterogeneous sources. Each source, with its specific data format and semantic domain, provides a non-parallel corpus of text and structured data. We introduce a variational auto-encoder model with disentangled style and content variables that allows us to represent the diversity that stems from multiple sources of text and data. Our model is designed to handle the tasks of D2T and T2D jointly. We evaluate our model on several datasets, and show that by learning from multiple sources, our model closes the performance gap with its supervised single-source counterpart and outperforms it in some cases.
AirfRANS: High Fidelity Computational Fluid Dynamics Dataset for Approximating Reynolds-Averaged Navier-Stokes Solutions
Jan 06, 2023



Surrogate models are necessary to optimize meaningful quantities in physical dynamics as their recursive numerical resolutions are often prohibitively expensive. It is mainly the case for fluid dynamics and the resolution of Navier-Stokes equations. However, despite the fast-growing field of data-driven models for physical systems, reference datasets representing real-world phenomena are lacking. In this work, we develop AirfRANS, a dataset for studying the two-dimensional incompressible steady-state Reynolds-Averaged Navier-Stokes equations over airfoils at a subsonic regime and for different angles of attacks. We also introduce metrics on the stress forces at the surface of geometries and visualization of boundary layers to assess the capabilities of models to accurately predict the meaningful information of the problem. Finally, we propose deep learning baselines on four machine learning tasks to study AirfRANS under different constraints for generalization considerations: big and scarce data regime, Reynolds number, and angle of attack extrapolation.