 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePavan Seshadri
Leveraging Negative Signals with Self-Attention for Sequential Music Recommendation
Sep 20, 2023

Music streaming services heavily rely on their recommendation engines to continuously provide content to their consumers. Sequential recommendation consequently has seen considerable attention in current literature, where state of the art approaches focus on self-attentive models leveraging contextual information such as long and short-term user history and item features; however, most of these studies focus on long-form content domains (retail, movie, etc.) rather than short-form, such as music. Additionally, many do not explore incorporating negative session-level feedback during training. In this study, we investigate the use of transformer-based self-attentive architectures to learn implicit session-level information for sequential music recommendation. We additionally propose a contrastive learning task to incorporate negative feedback (e.g skipped tracks) to promote positive hits and penalize negative hits. This task is formulated as a simple loss term that can be incorporated into a variety of deep learning architectures for sequential recommendation. Our experiments show that this results in consistent performance gains over the baseline architectures ignoring negative user feedback.
ASPED: An Audio Dataset for Detecting Pedestrians
Sep 12, 2023
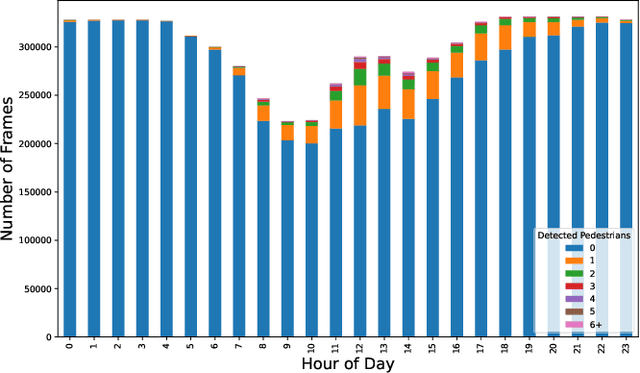
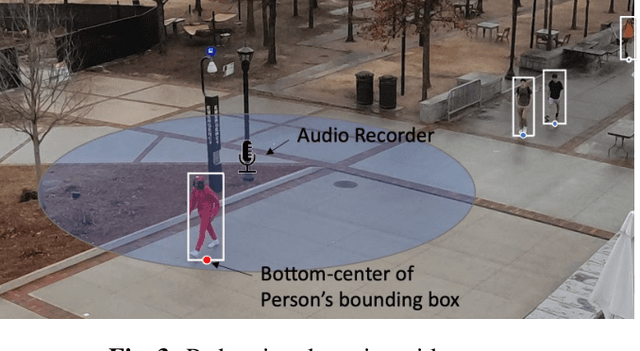
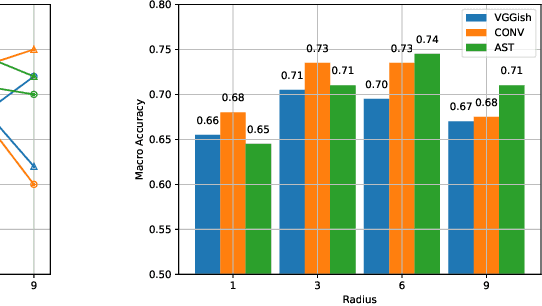
We introduce the new audio analysis task of pedestrian detection and present a new large-scale dataset for this task. While the preliminary results prove the viability of using audio approaches for pedestrian detection, they also show that this challenging task cannot be easily solved with standard approaches.
AVASpeech-SMAD: A Strongly Labelled Speech and Music Activity Detection Dataset with Label Co-Occurrence
Nov 02, 2021



We propose a dataset, AVASpeech-SMAD, to assist speech and music activity detection research. With frame-level music labels, the proposed dataset extends the existing AVASpeech dataset, which originally consists of 45 hours of audio and speech activity labels. To the best of our knowledge, the proposed AVASpeech-SMAD is the first open-source dataset that features strong polyphonic labels for both music and speech. The dataset was manually annotated and verified via an iterative cross-checking process. A simple automatic examination was also implemented to further improve the quality of the labels. Evaluation results from two state-of-the-art SMAD systems are also provided as a benchmark for future reference.
Improving Music Performance Assessment with Contrastive Learning
Aug 03, 2021



Several automatic approaches for objective music performance assessment (MPA) have been proposed in the past, however, existing systems are not yet capable of reliably predicting ratings with the same accuracy as professional judges. This study investigates contrastive learning as a potential method to improve existing MPA systems. Contrastive learning is a widely used technique in representation learning to learn a structured latent space capable of separately clustering multiple classes. It has been shown to produce state of the art results for image-based classification problems. We introduce a weighted contrastive loss suitable for regression tasks applied to a convolutional neural network and show that contrastive loss results in performance gains in regression tasks for MPA. Our results show that contrastive-based methods are able to match and exceed SoTA performance for MPA regression tasks by creating better class clusters within the latent space of the neural networks.