 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeetak P. Mitra
Learning to forecast diagnostic parameters using pre-trained weather embedding
Dec 01, 2023
Data-driven weather prediction (DDWP) models are increasingly becoming popular for weather forecasting. However, while operational weather forecasts predict a wide variety of weather variables, DDWPs currently forecast a specific set of key prognostic variables. Non-prognostic ("diagnostic") variables are sometimes modeled separately as dependent variables of the prognostic variables (c.f. FourCastNet), or by including the diagnostic variable as a target in the DDWP. However, the cost of training and deploying bespoke models for each diagnostic variable can increase dramatically with more diagnostic variables, and limit the operational use of such models. Likewise, retraining an entire DDWP each time a new diagnostic variable is added is also cost-prohibitive. We present an two-stage approach that allows new diagnostic variables to be added to an end-to-end DDWP model without the expensive retraining. In the first stage, we train an autoencoder that learns to embed prognostic variables into a latent space. In the second stage, the autoencoder is frozen and "downstream" models are trained to predict diagnostic variables using only the latent representations of prognostic variables as input. Our experiments indicate that models trained using the two-stage approach offer accuracy comparable to training bespoke models, while leading to significant reduction in resource utilization during training and inference. This approach allows for new "downstream" models to be developed as needed, without affecting existing models and thus reducing the friction in operationalizing new models.
Verification against in-situ observations for Data-Driven Weather Prediction
Apr 28, 2023
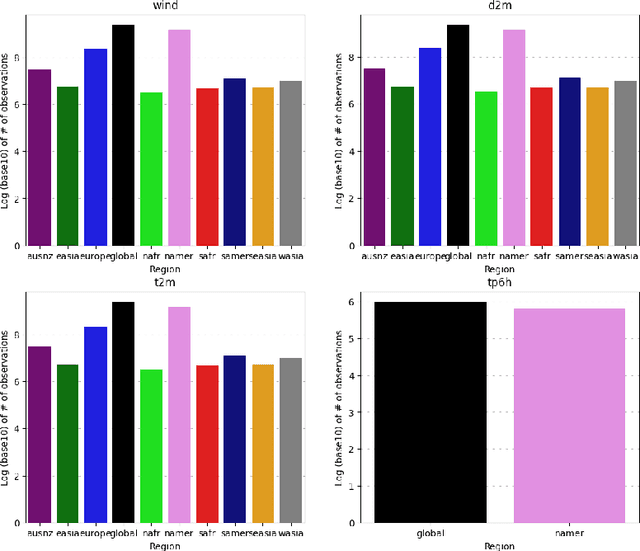
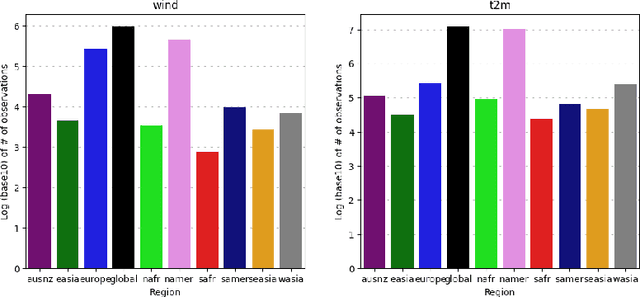
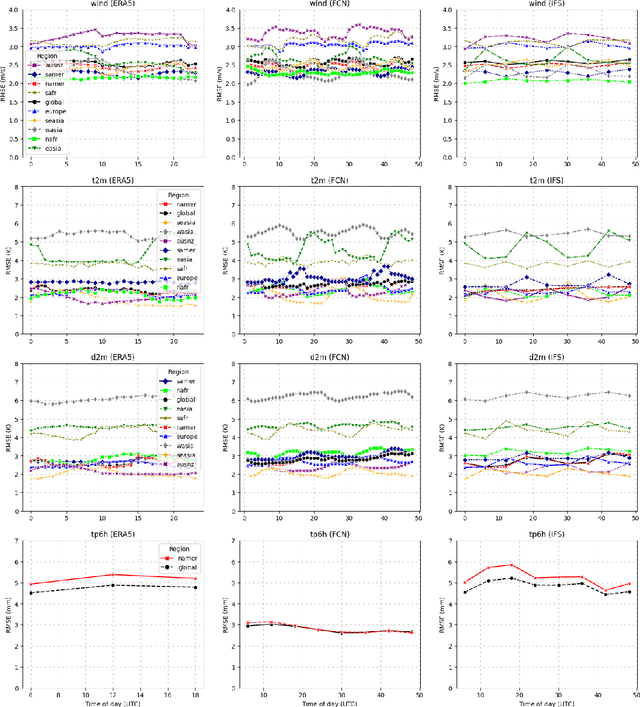
Data-driven weather prediction models (DDWPs) have made rapid strides in recent years, demonstrating an ability to approximate Numerical Weather Prediction (NWP) models to a high degree of accuracy. The fast, accurate, and low-cost DDWP forecasts make their use in operational forecasting an attractive proposition, however, there remains work to be done in rigorously evaluating DDWPs in a true operational setting. Typically trained and evaluated using ERA5 reanalysis data, DDWPs have been tested only in a simulation, which cannot represent the real world with complete accuracy even if it is of a very high quality. The safe use of DDWPs in operational forecasting requires more thorough "real-world" verification, as well as a careful examination of how DDWPs are currently trained and evaluated. It is worth asking, for instance, how well do the reanalysis datasets, used for training, simulate the real world? With an eye towards climate justice and the uneven availability of weather data: is the simulation equally good for all regions of the world, and would DDWPs exacerbate biases present in the training data? Does a good performance in simulation correspond to good performance in operational settings? In addition to approximating the physics of NWP models, how can ML be uniquely deployed to provide more accurate weather forecasts? As a first step towards answering such questions, we present a robust dataset of in-situ observations derived from the NOAA MADIS program to serve as a benchmark to validate DDWPs in an operational setting. By providing a large corpus of quality-controlled, in-situ observations, this dataset provides a meaningful real-world task that all NWPs and DDWPs can be tested against. We hope that this data can be used not only to rigorously and fairly compare operational weather models but also to spur future research in new directions.