 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeihao Chen
3D-VLA: A 3D Vision-Language-Action Generative World Model
Mar 14, 2024
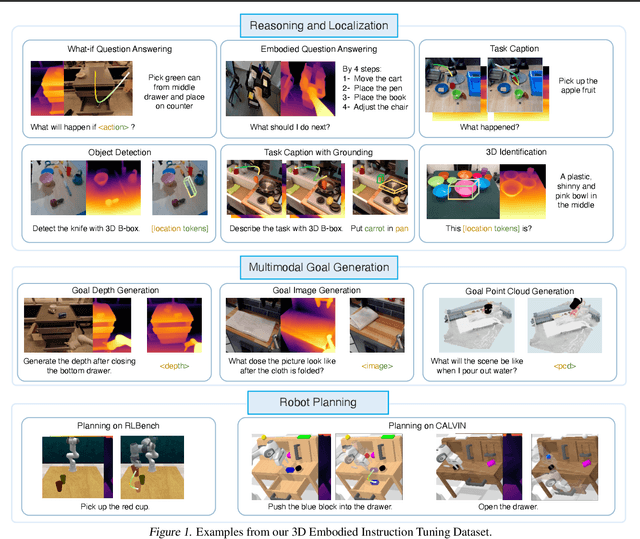
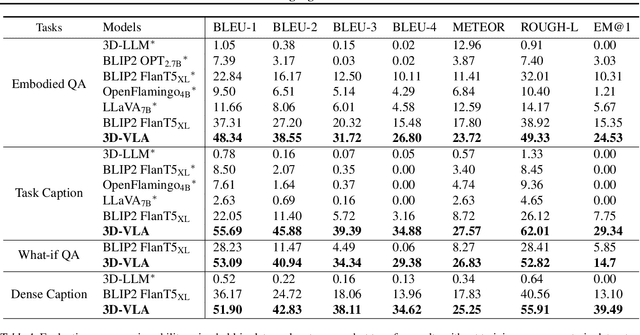
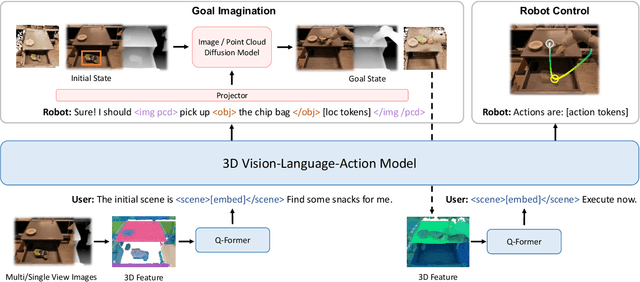
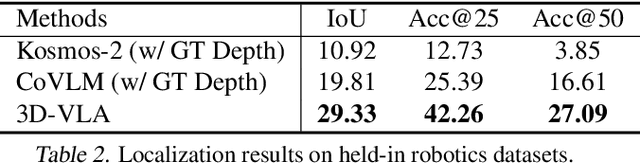
Recent vision-language-action (VLA) models rely on 2D inputs, lacking integration with the broader realm of the 3D physical world. Furthermore, they perform action prediction by learning a direct mapping from perception to action, neglecting the vast dynamics of the world and the relations between actions and dynamics. In contrast, human beings are endowed with world models that depict imagination about future scenarios to plan actions accordingly. To this end, we propose 3D-VLA by introducing a new family of embodied foundation models that seamlessly link 3D perception, reasoning, and action through a generative world model. Specifically, 3D-VLA is built on top of a 3D-based large language model (LLM), and a set of interaction tokens is introduced to engage with the embodied environment. Furthermore, to inject generation abilities into the model, we train a series of embodied diffusion models and align them into the LLM for predicting the goal images and point clouds. To train our 3D-VLA, we curate a large-scale 3D embodied instruction dataset by extracting vast 3D-related information from existing robotics datasets. Our experiments on held-in datasets demonstrate that 3D-VLA significantly improves the reasoning, multimodal generation, and planning capabilities in embodied environments, showcasing its potential in real-world applications.
MultiPLY: A Multisensory Object-Centric Embodied Large Language Model in 3D World
Jan 16, 2024Human beings possess the capability to multiply a melange of multisensory cues while actively exploring and interacting with the 3D world. Current multi-modal large language models, however, passively absorb sensory data as inputs, lacking the capacity to actively interact with the objects in the 3D environment and dynamically collect their multisensory information. To usher in the study of this area, we propose MultiPLY, a multisensory embodied large language model that could incorporate multisensory interactive data, including visual, audio, tactile, and thermal information into large language models, thereby establishing the correlation among words, actions, and percepts. To this end, we first collect Multisensory Universe, a large-scale multisensory interaction dataset comprising 500k data by deploying an LLM-powered embodied agent to engage with the 3D environment. To perform instruction tuning with pre-trained LLM on such generated data, we first encode the 3D scene as abstracted object-centric representations and then introduce action tokens denoting that the embodied agent takes certain actions within the environment, as well as state tokens that represent the multisensory state observations of the agent at each time step. In the inference time, MultiPLY could generate action tokens, instructing the agent to take the action in the environment and obtain the next multisensory state observation. The observation is then appended back to the LLM via state tokens to generate subsequent text or action tokens. We demonstrate that MultiPLY outperforms baselines by a large margin through a diverse set of embodied tasks involving object retrieval, tool use, multisensory captioning, and task decomposition.
A Simple Knowledge Distillation Framework for Open-world Object Detection
Dec 14, 2023Open World Object Detection (OWOD) is a novel computer vision task with a considerable challenge, bridging the gap between classic object detection (OD) benchmarks and real-world object detection. In addition to detecting and classifying seen/known objects, OWOD algorithms are expected to localize all potential unseen/unknown objects and incrementally learn them. The large pre-trained vision-language grounding models (VLM,eg, GLIP) have rich knowledge about the open world, but are limited by text prompts and cannot localize indescribable objects. However, there are many detection scenarios which pre-defined language descriptions are unavailable during inference. In this paper, we attempt to specialize the VLM model for OWOD task by distilling its open-world knowledge into a language-agnostic detector. Surprisingly, we observe that the combination of a simple knowledge distillation approach and the automatic pseudo-labeling mechanism in OWOD can achieve better performance for unknown object detection, even with a small amount of data. Unfortunately, knowledge distillation for unknown objects severely affects the learning of detectors with conventional structures for known objects, leading to catastrophic forgetting. To alleviate these problems, we propose the down-weight loss function for knowledge distillation from vision-language to single vision modality. Meanwhile, we decouple the learning of localization and recognition to reduce the impact of category interactions of known and unknown objects on the localization learning process. Comprehensive experiments performed on MS-COCO and PASCAL VOC demonstrate the effectiveness of our methods.
DCIR: Dynamic Consistency Intrinsic Reward for Multi-Agent Reinforcement Learning
Dec 10, 2023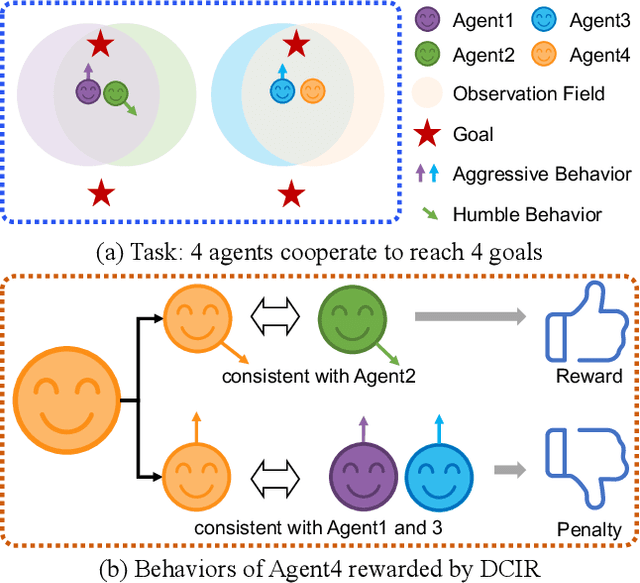
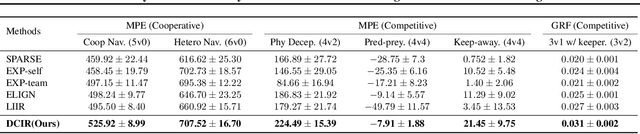
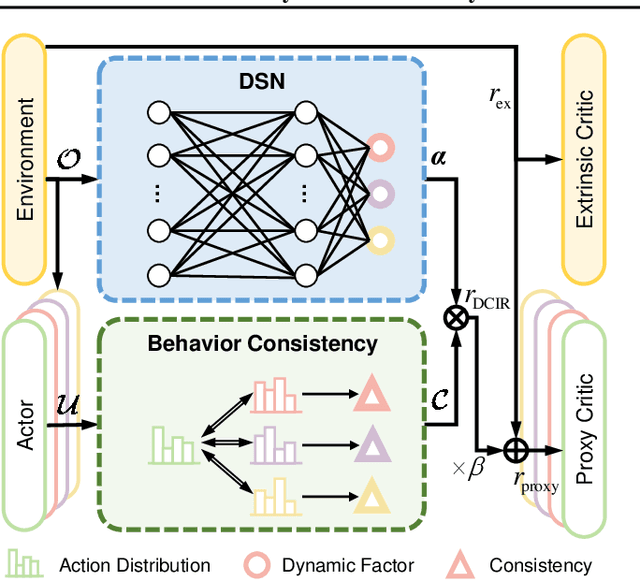
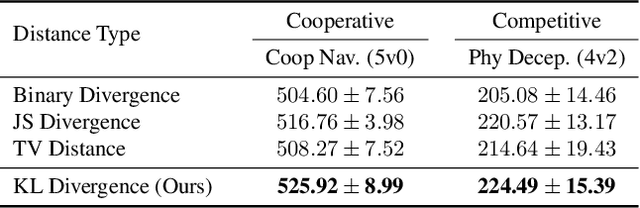
Learning optimal behavior policy for each agent in multi-agent systems is an essential yet difficult problem. Despite fruitful progress in multi-agent reinforcement learning, the challenge of addressing the dynamics of whether two agents should exhibit consistent behaviors is still under-explored. In this paper, we propose a new approach that enables agents to learn whether their behaviors should be consistent with that of other agents by utilizing intrinsic rewards to learn the optimal policy for each agent. We begin by defining behavior consistency as the divergence in output actions between two agents when provided with the same observation. Subsequently, we introduce dynamic consistency intrinsic reward (DCIR) to stimulate agents to be aware of others' behaviors and determine whether to be consistent with them. Lastly, we devise a dynamic scale network (DSN) that provides learnable scale factors for the agent at every time step to dynamically ascertain whether to award consistent behavior and the magnitude of rewards. We evaluate DCIR in multiple environments including Multi-agent Particle, Google Research Football and StarCraft II Micromanagement, demonstrating its efficacy.
CoVLM: Composing Visual Entities and Relationships in Large Language Models Via Communicative Decoding
Nov 06, 2023A remarkable ability of human beings resides in compositional reasoning, i.e., the capacity to make "infinite use of finite means". However, current large vision-language foundation models (VLMs) fall short of such compositional abilities due to their "bag-of-words" behaviors and inability to construct words that correctly represent visual entities and the relations among the entities. To this end, we propose CoVLM, which can guide the LLM to explicitly compose visual entities and relationships among the text and dynamically communicate with the vision encoder and detection network to achieve vision-language communicative decoding. Specifically, we first devise a set of novel communication tokens for the LLM, for dynamic communication between the visual detection system and the language system. A communication token is generated by the LLM following a visual entity or a relation, to inform the detection network to propose regions that are relevant to the sentence generated so far. The proposed regions-of-interests (ROIs) are then fed back into the LLM for better language generation contingent on the relevant regions. The LLM is thus able to compose the visual entities and relationships through the communication tokens. The vision-to-language and language-to-vision communication are iteratively performed until the entire sentence is generated. Our framework seamlessly bridges the gap between visual perception and LLMs and outperforms previous VLMs by a large margin on compositional reasoning benchmarks (e.g., ~20% in HICO-DET mAP, ~14% in Cola top-1 accuracy, and ~3% on ARO top-1 accuracy). We also achieve state-of-the-art performances on traditional vision-language tasks such as referring expression comprehension and visual question answering.
FGPrompt: Fine-grained Goal Prompting for Image-goal Navigation
Oct 11, 2023Learning to navigate to an image-specified goal is an important but challenging task for autonomous systems. The agent is required to reason the goal location from where a picture is shot. Existing methods try to solve this problem by learning a navigation policy, which captures semantic features of the goal image and observation image independently and lastly fuses them for predicting a sequence of navigation actions. However, these methods suffer from two major limitations. 1) They may miss detailed information in the goal image, and thus fail to reason the goal location. 2) More critically, it is hard to focus on the goal-relevant regions in the observation image, because they attempt to understand observation without goal conditioning. In this paper, we aim to overcome these limitations by designing a Fine-grained Goal Prompting (FGPrompt) method for image-goal navigation. In particular, we leverage fine-grained and high-resolution feature maps in the goal image as prompts to perform conditioned embedding, which preserves detailed information in the goal image and guides the observation encoder to pay attention to goal-relevant regions. Compared with existing methods on the image-goal navigation benchmark, our method brings significant performance improvement on 3 benchmark datasets (i.e., Gibson, MP3D, and HM3D). Especially on Gibson, we surpass the state-of-the-art success rate by 8% with only 1/50 model size. Project page: https://xinyusun.github.io/fgprompt-pages
$A^2$Nav: Action-Aware Zero-Shot Robot Navigation by Exploiting Vision-and-Language Ability of Foundation Models
Aug 15, 2023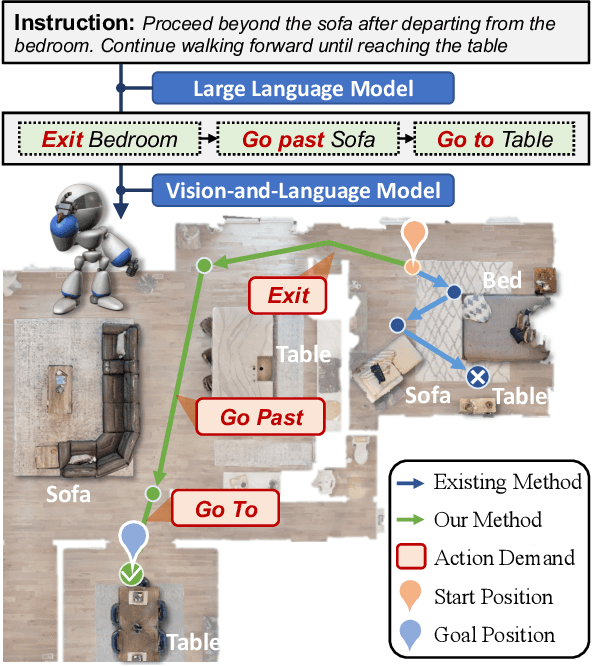
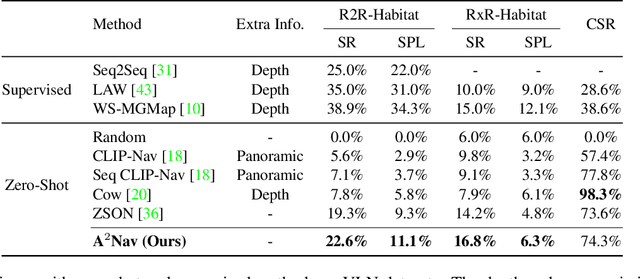
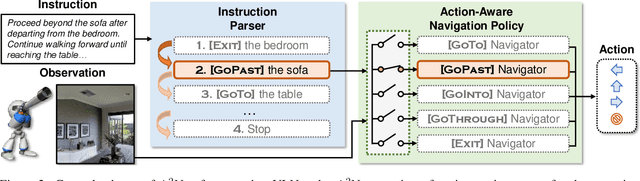
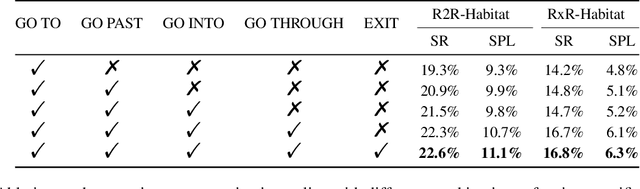
We study the task of zero-shot vision-and-language navigation (ZS-VLN), a practical yet challenging problem in which an agent learns to navigate following a path described by language instructions without requiring any path-instruction annotation data. Normally, the instructions have complex grammatical structures and often contain various action descriptions (e.g., "proceed beyond", "depart from"). How to correctly understand and execute these action demands is a critical problem, and the absence of annotated data makes it even more challenging. Note that a well-educated human being can easily understand path instructions without the need for any special training. In this paper, we propose an action-aware zero-shot VLN method ($A^2$Nav) by exploiting the vision-and-language ability of foundation models. Specifically, the proposed method consists of an instruction parser and an action-aware navigation policy. The instruction parser utilizes the advanced reasoning ability of large language models (e.g., GPT-3) to decompose complex navigation instructions into a sequence of action-specific object navigation sub-tasks. Each sub-task requires the agent to localize the object and navigate to a specific goal position according to the associated action demand. To accomplish these sub-tasks, an action-aware navigation policy is learned from freely collected action-specific datasets that reveal distinct characteristics of each action demand. We use the learned navigation policy for executing sub-tasks sequentially to follow the navigation instruction. Extensive experiments show $A^2$Nav achieves promising ZS-VLN performance and even surpasses the supervised learning methods on R2R-Habitat and RxR-Habitat datasets.
3D-LLM: Injecting the 3D World into Large Language Models
Jul 24, 2023Large language models (LLMs) and Vision-Language Models (VLMs) have been proven to excel at multiple tasks, such as commonsense reasoning. Powerful as these models can be, they are not grounded in the 3D physical world, which involves richer concepts such as spatial relationships, affordances, physics, layout, and so on. In this work, we propose to inject the 3D world into large language models and introduce a whole new family of 3D-LLMs. Specifically, 3D-LLMs can take 3D point clouds and their features as input and perform a diverse set of 3D-related tasks, including captioning, dense captioning, 3D question answering, task decomposition, 3D grounding, 3D-assisted dialog, navigation, and so on. Using three types of prompting mechanisms that we design, we are able to collect over 300k 3D-language data covering these tasks. To efficiently train 3D-LLMs, we first utilize a 3D feature extractor that obtains 3D features from rendered multi- view images. Then, we use 2D VLMs as our backbones to train our 3D-LLMs. By introducing a 3D localization mechanism, 3D-LLMs can better capture 3D spatial information. Experiments on ScanQA show that our model outperforms state-of-the-art baselines by a large margin (e.g., the BLEU-1 score surpasses state-of-the-art score by 9%). Furthermore, experiments on our held-in datasets for 3D captioning, task composition, and 3D-assisted dialogue show that our model outperforms 2D VLMs. Qualitative examples also show that our model could perform more tasks beyond the scope of existing LLMs and VLMs. Project Page: : https://vis-www.cs.umass.edu/3dllm/.
Learning Vision-and-Language Navigation from YouTube Videos
Jul 22, 2023



Vision-and-language navigation (VLN) requires an embodied agent to navigate in realistic 3D environments using natural language instructions. Existing VLN methods suffer from training on small-scale environments or unreasonable path-instruction datasets, limiting the generalization to unseen environments. There are massive house tour videos on YouTube, providing abundant real navigation experiences and layout information. However, these videos have not been explored for VLN before. In this paper, we propose to learn an agent from these videos by creating a large-scale dataset which comprises reasonable path-instruction pairs from house tour videos and pre-training the agent on it. To achieve this, we have to tackle the challenges of automatically constructing path-instruction pairs and exploiting real layout knowledge from raw and unlabeled videos. To address these, we first leverage an entropy-based method to construct the nodes of a path trajectory. Then, we propose an action-aware generator for generating instructions from unlabeled trajectories. Last, we devise a trajectory judgment pretext task to encourage the agent to mine the layout knowledge. Experimental results show that our method achieves state-of-the-art performance on two popular benchmarks (R2R and REVERIE). Code is available at https://github.com/JeremyLinky/YouTube-VLN
Vesper: A Compact and Effective Pretrained Model for Speech Emotion Recognition
Jul 20, 2023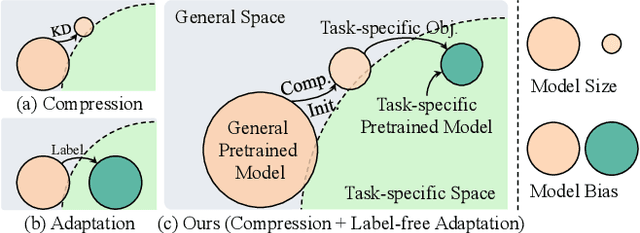
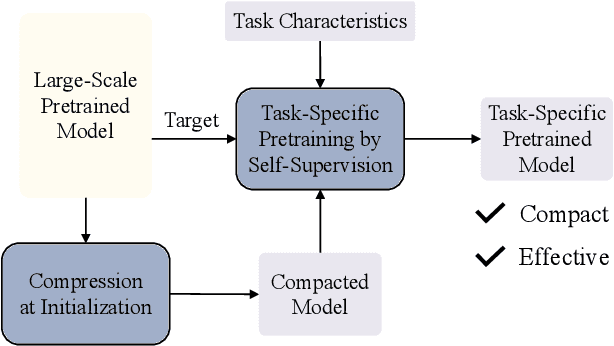

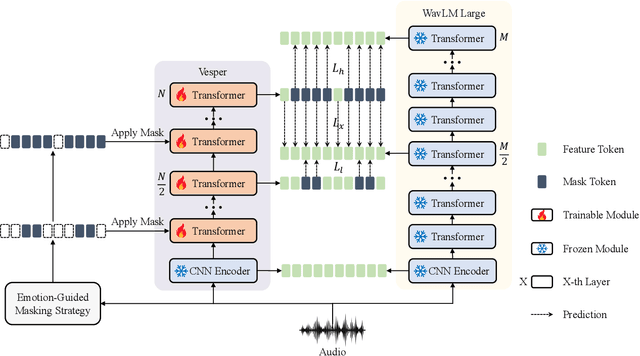
This paper presents a paradigm that adapts general large-scale pretrained models (PTMs) to speech emotion recognition task. Although PTMs shed new light on artificial general intelligence, they are constructed with general tasks in mind, and thus, their efficacy for specific tasks can be further improved. Additionally, employing PTMs in practical applications can be challenging due to their considerable size. Above limitations spawn another research direction, namely, optimizing large-scale PTMs for specific tasks to generate task-specific PTMs that are both compact and effective. In this paper, we focus on the speech emotion recognition task and propose an improved emotion-specific pretrained encoder called Vesper. Vesper is pretrained on a speech dataset based on WavLM and takes into account emotional characteristics. To enhance sensitivity to emotional information, Vesper employs an emotion-guided masking strategy to identify the regions that need masking. Subsequently, Vesper employs hierarchical and cross-layer self-supervision to improve its ability to capture acoustic and semantic representations, both of which are crucial for emotion recognition. Experimental results on the IEMOCAP, MELD, and CREMA-D datasets demonstrate that Vesper with 4 layers outperforms WavLM Base with 12 layers, and the performance of Vesper with 12 layers surpasses that of WavLM Large with 24 layers.