 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeiyao Guo
Transformer-based Image Compression
Nov 12, 2021
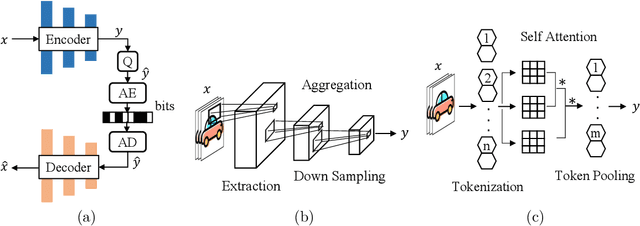
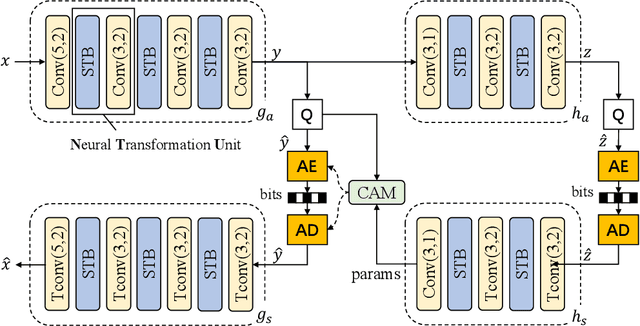
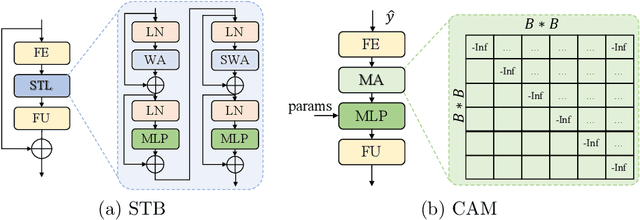
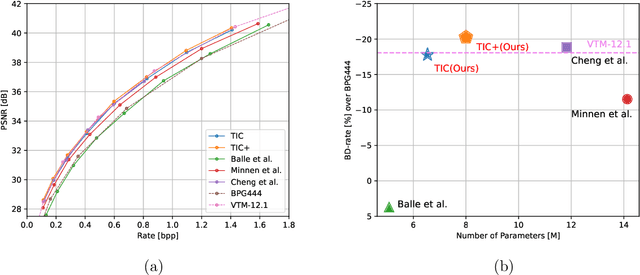
A Transformer-based Image Compression (TIC) approach is developed which reuses the canonical variational autoencoder (VAE) architecture with paired main and hyper encoder-decoders. Both main and hyper encoders are comprised of a sequence of neural transformation units (NTUs) to analyse and aggregate important information for more compact representation of input image, while the decoders mirror the encoder-side operations to generate pixel-domain image reconstruction from the compressed bitstream. Each NTU is consist of a Swin Transformer Block (STB) and a convolutional layer (Conv) to best embed both long-range and short-range information; In the meantime, a casual attention module (CAM) is devised for adaptive context modeling of latent features to utilize both hyper and autoregressive priors. The TIC rivals with state-of-the-art approaches including deep convolutional neural networks (CNNs) based learnt image coding (LIC) methods and handcrafted rules-based intra profile of recently-approved Versatile Video Coding (VVC) standard, and requires much less model parameters, e.g., up to 45% reduction to leading-performance LIC.
Non-local Attention Optimized Deep Image Compression
Apr 22, 2019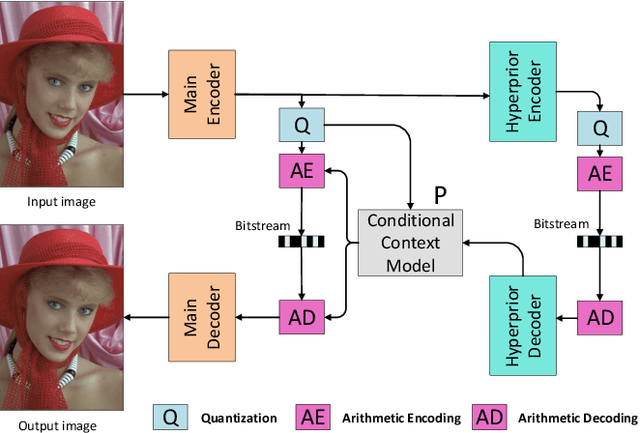

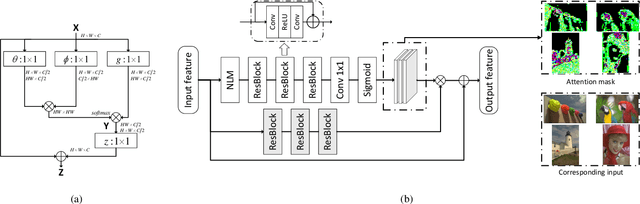
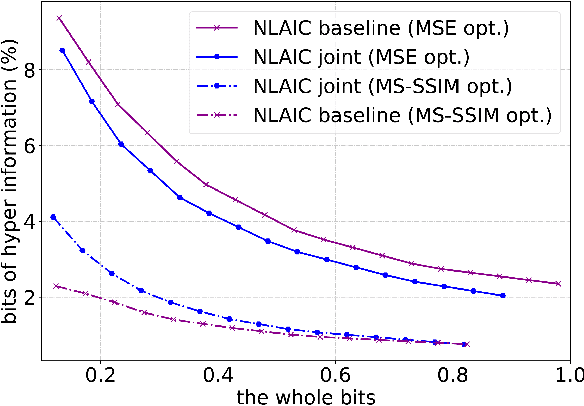
This paper proposes a novel Non-Local Attention Optimized Deep Image Compression (NLAIC) framework, which is built on top of the popular variational auto-encoder (VAE) structure. Our NLAIC framework embeds non-local operations in the encoders and decoders for both image and latent feature probability information (known as hyperprior) to capture both local and global correlations, and apply attention mechanism to generate masks that are used to weigh the features for the image and hyperprior, which implicitly adapt bit allocation for different features based on their importance. Furthermore, both hyperpriors and spatial-channel neighbors of the latent features are used to improve entropy coding. The proposed model outperforms the existing methods on Kodak dataset, including learned (e.g., Balle2019, Balle2018) and conventional (e.g., BPG, JPEG2000, JPEG) image compression methods, for both PSNR and MS-SSIM distortion metrics.