 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeiye Zhuang
AToM: Amortized Text-to-Mesh using 2D Diffusion
Feb 01, 2024
We introduce Amortized Text-to-Mesh (AToM), a feed-forward text-to-mesh framework optimized across multiple text prompts simultaneously. In contrast to existing text-to-3D methods that often entail time-consuming per-prompt optimization and commonly output representations other than polygonal meshes, AToM directly generates high-quality textured meshes in less than 1 second with around 10 times reduction in the training cost, and generalizes to unseen prompts. Our key idea is a novel triplane-based text-to-mesh architecture with a two-stage amortized optimization strategy that ensures stable training and enables scalability. Through extensive experiments on various prompt benchmarks, AToM significantly outperforms state-of-the-art amortized approaches with over 4 times higher accuracy (in DF415 dataset) and produces more distinguishable and higher-quality 3D outputs. AToM demonstrates strong generalizability, offering finegrained 3D assets for unseen interpolated prompts without further optimization during inference, unlike per-prompt solutions.
Diffusion Priors for Dynamic View Synthesis from Monocular Videos
Jan 10, 2024Dynamic novel view synthesis aims to capture the temporal evolution of visual content within videos. Existing methods struggle to distinguishing between motion and structure, particularly in scenarios where camera poses are either unknown or constrained compared to object motion. Furthermore, with information solely from reference images, it is extremely challenging to hallucinate unseen regions that are occluded or partially observed in the given videos. To address these issues, we first finetune a pretrained RGB-D diffusion model on the video frames using a customization technique. Subsequently, we distill the knowledge from the finetuned model to a 4D representations encompassing both dynamic and static Neural Radiance Fields (NeRF) components. The proposed pipeline achieves geometric consistency while preserving the scene identity. We perform thorough experiments to evaluate the efficacy of the proposed method qualitatively and quantitatively. Our results demonstrate the robustness and utility of our approach in challenging cases, further advancing dynamic novel view synthesis.
SceneWiz3D: Towards Text-guided 3D Scene Composition
Dec 13, 2023We are witnessing significant breakthroughs in the technology for generating 3D objects from text. Existing approaches either leverage large text-to-image models to optimize a 3D representation or train 3D generators on object-centric datasets. Generating entire scenes, however, remains very challenging as a scene contains multiple 3D objects, diverse and scattered. In this work, we introduce SceneWiz3D, a novel approach to synthesize high-fidelity 3D scenes from text. We marry the locality of objects with globality of scenes by introducing a hybrid 3D representation: explicit for objects and implicit for scenes. Remarkably, an object, being represented explicitly, can be either generated from text using conventional text-to-3D approaches, or provided by users. To configure the layout of the scene and automatically place objects, we apply the Particle Swarm Optimization technique during the optimization process. Furthermore, it is difficult for certain parts of the scene (e.g., corners, occlusion) to receive multi-view supervision, leading to inferior geometry. We incorporate an RGBD panorama diffusion model to mitigate it, resulting in high-quality geometry. Extensive evaluation supports that our approach achieves superior quality over previous approaches, enabling the generation of detailed and view-consistent 3D scenes.
HiFA: High-fidelity Text-to-3D with Advanced Diffusion Guidance
May 31, 2023



Automatic text-to-3D synthesis has achieved remarkable advancements through the optimization of 3D models. Existing methods commonly rely on pre-trained text-to-image generative models, such as diffusion models, providing scores for 2D renderings of Neural Radiance Fields (NeRFs) and being utilized for optimizing NeRFs. However, these methods often encounter artifacts and inconsistencies across multiple views due to their limited understanding of 3D geometry. To address these limitations, we propose a reformulation of the optimization loss using the diffusion prior. Furthermore, we introduce a novel training approach that unlocks the potential of the diffusion prior. To improve 3D geometry representation, we apply auxiliary depth supervision for NeRF-rendered images and regularize the density field of NeRFs. Extensive experiments demonstrate the superiority of our method over prior works, resulting in advanced photo-realism and improved multi-view consistency.
Diffusion Probabilistic Fields
Mar 01, 2023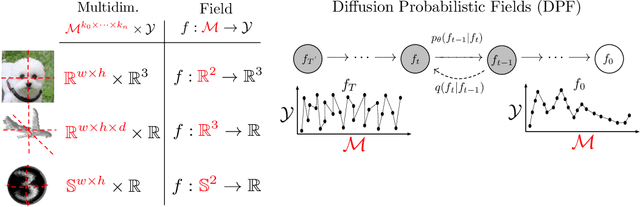
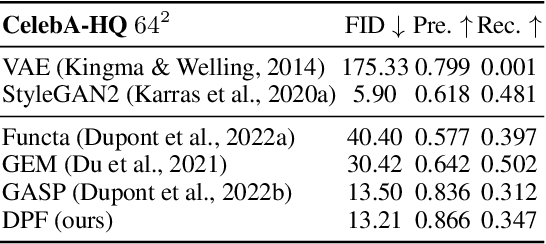
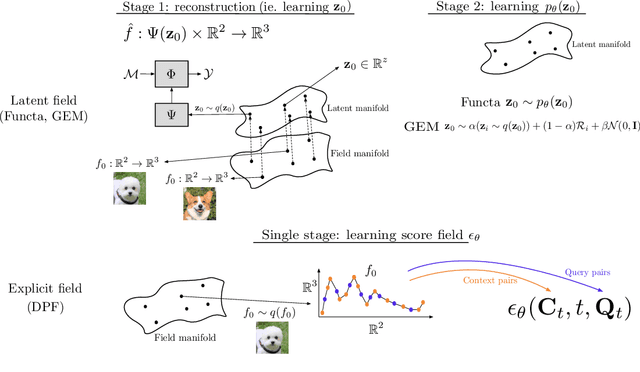

Diffusion probabilistic models have quickly become a major approach for generative modeling of images, 3D geometry, video and other domains. However, to adapt diffusion generative modeling to these domains the denoising network needs to be carefully designed for each domain independently, oftentimes under the assumption that data lives in a Euclidean grid. In this paper we introduce Diffusion Probabilistic Fields (DPF), a diffusion model that can learn distributions over continuous functions defined over metric spaces, commonly known as fields. We extend the formulation of diffusion probabilistic models to deal with this field parametrization in an explicit way, enabling us to define an end-to-end learning algorithm that side-steps the requirement of representing fields with latent vectors as in previous approaches (Dupont et al., 2022a; Du et al., 2021). We empirically show that, while using the same denoising network, DPF effectively deals with different modalities like 2D images and 3D geometry, in addition to modeling distributions over fields defined on non-Euclidean metric spaces.
Synthetic Power Analyses: Empirical Evaluation and Application to Cognitive Neuroimaging
Oct 11, 2022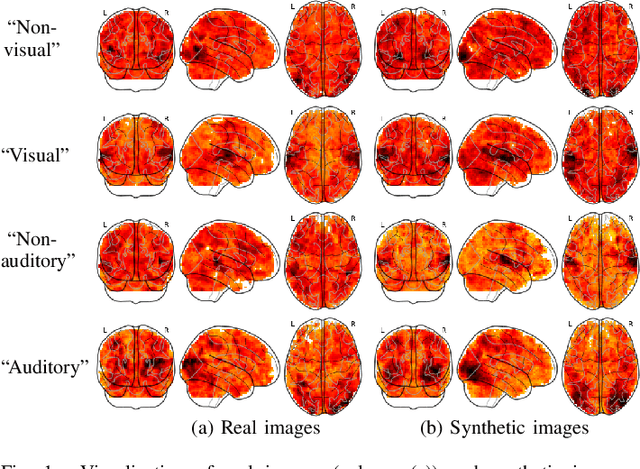
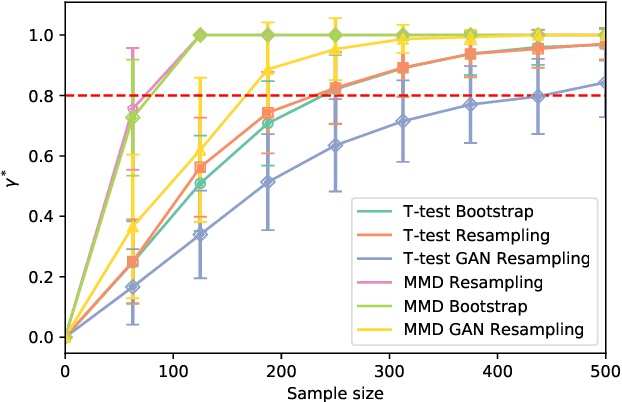
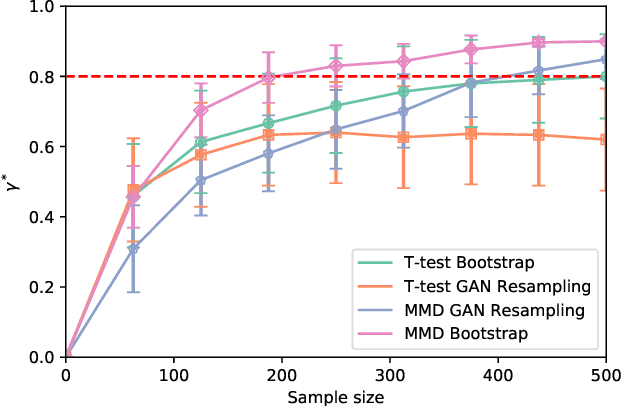
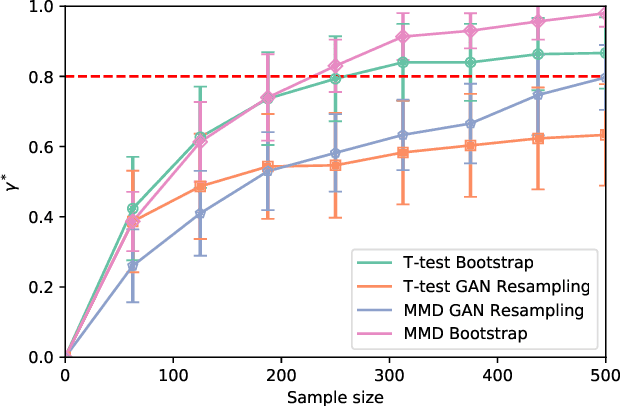
In the experimental sciences, statistical power analyses are often used before data collection to determine the required sample size. However, traditional power analyses can be costly when data are difficult or expensive to collect. We propose synthetic power analyses; a framework for estimating statistical power at various sample sizes, and empirically explore the performance of synthetic power analysis for sample size selection in cognitive neuroscience experiments. To this end, brain imaging data is synthesized using an implicit generative model conditioned on observed cognitive processes. Further, we propose a simple procedure to modify the statistical tests which result in conservative statistics. Our empirical results suggest that synthetic power analysis could be a low-cost alternative to pilot data collection when the proposed experiments share cognitive processes with previously conducted experiments.
AMICO: Amodal Instance Composition
Oct 11, 2022
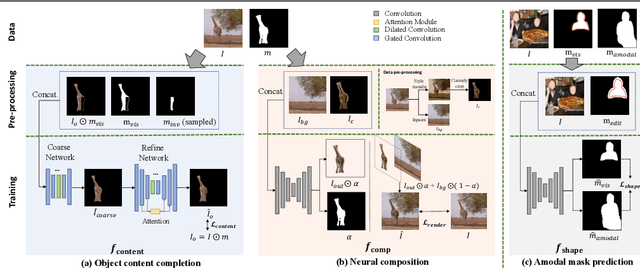


Image composition aims to blend multiple objects to form a harmonized image. Existing approaches often assume precisely segmented and intact objects. Such assumptions, however, are hard to satisfy in unconstrained scenarios. We present Amodal Instance Composition for compositing imperfect -- potentially incomplete and/or coarsely segmented -- objects onto a target image. We first develop object shape prediction and content completion modules to synthesize the amodal contents. We then propose a neural composition model to blend the objects seamlessly. Our primary technical novelty lies in using separate foreground/background representations and blending mask prediction to alleviate segmentation errors. Our results show state-of-the-art performance on public COCOA and KINS benchmarks and attain favorable visual results across diverse scenes. We demonstrate various image composition applications such as object insertion and de-occlusion.
Controllable Radiance Fields for Dynamic Face Synthesis
Oct 11, 2022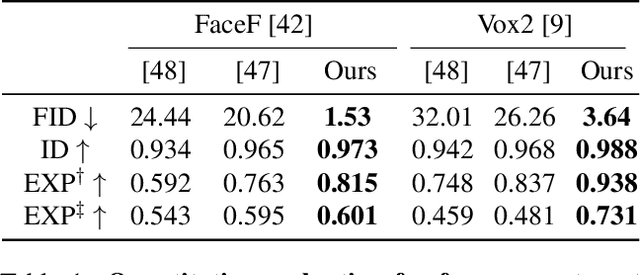
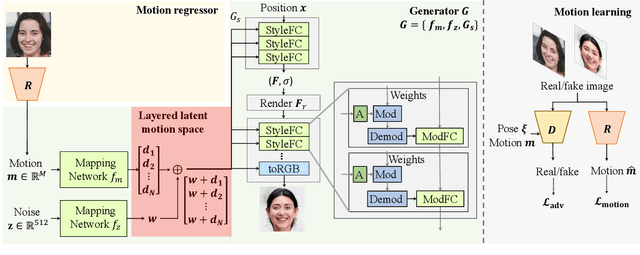

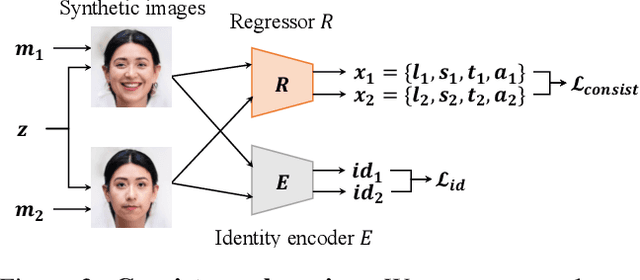
Recent work on 3D-aware image synthesis has achieved compelling results using advances in neural rendering. However, 3D-aware synthesis of face dynamics hasn't received much attention. Here, we study how to explicitly control generative model synthesis of face dynamics exhibiting non-rigid motion (e.g., facial expression change), while simultaneously ensuring 3D-awareness. For this we propose a Controllable Radiance Field (CoRF): 1) Motion control is achieved by embedding motion features within the layered latent motion space of a style-based generator; 2) To ensure consistency of background, motion features and subject-specific attributes such as lighting, texture, shapes, albedo, and identity, a face parsing net, a head regressor and an identity encoder are incorporated. On head image/video data we show that CoRFs are 3D-aware while enabling editing of identity, viewing directions, and motion.
Enjoy Your Editing: Controllable GANs for Image Editing via Latent Space Navigation
Feb 03, 2021



Controllable semantic image editing enables a user to change entire image attributes with few clicks, e.g., gradually making a summer scene look like it was taken in winter. Classic approaches for this task use a Generative Adversarial Net (GAN) to learn a latent space and suitable latent-space transformations. However, current approaches often suffer from attribute edits that are entangled, global image identity changes, and diminished photo-realism. To address these concerns, we learn multiple attribute transformations simultaneously, we integrate attribute regression into the training of transformation functions, apply a content loss and an adversarial loss that encourage the maintenance of image identity and photo-realism. We propose quantitative evaluation strategies for measuring controllable editing performance, unlike prior work which primarily focuses on qualitative evaluation. Our model permits better control for both single- and multiple-attribute editing, while also preserving image identity and realism during transformation. We provide empirical results for both real and synthetic images, highlighting that our model achieves state-of-the-art performance for targeted image manipulation.
EMIXER: End-to-end Multimodal X-ray Generation via Self-supervision
Jul 10, 2020



Deep generative models have enabled the automated synthesis of high-quality data for diverse applications. However, the most effective generative models are specialized to data from a single domain (e.g., images or text). Real-world applications such as healthcare require multi-modal data from multiple domains (e.g., both images and corresponding text), which are difficult to acquire due to limited availability and privacy concerns and are much harder to synthesize. To tackle this joint synthesis challenge, we propose an End-to-end MultImodal X-ray genERative model (EMIXER) for jointly synthesizing x-ray images and corresponding free-text reports, all conditional on diagnosis labels. EMIXER is an conditional generative adversarial model by 1) generating an image based on a label, 2) encoding the image to a hidden embedding, 3) producing the corresponding text via a hierarchical decoder from the image embedding, and 4) a joint discriminator for assessing both the image and the corresponding text. EMIXER also enables self-supervision to leverage vast amount of unlabeled data. Extensive experiments with real X-ray reports data illustrate how data augmentation using synthesized multimodal samples can improve the performance of a variety of supervised tasks including COVID-19 X-ray classification with very limited samples. The quality of generated images and reports are also confirmed by radiologists. We quantitatively show that EMIXER generated synthetic datasets can augment X-ray image classification, report generation models to achieve 5.94% and 6.9% improvement on models trained only on real data samples. Taken together, our results highlight the promise of state of generative models to advance clinical machine learning.