 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeiyu Yang
Backdoor-based Explainable AI Benchmark for High Fidelity Evaluation of Attribution Methods
May 02, 2024
Attribution methods compute importance scores for input features to explain the output predictions of deep models. However, accurate assessment of attribution methods is challenged by the lack of benchmark fidelity for attributing model predictions. Moreover, other confounding factors in attribution estimation, including the setup choices of post-processing techniques and explained model predictions, further compromise the reliability of the evaluation. In this work, we first identify a set of fidelity criteria that reliable benchmarks for attribution methods are expected to fulfill, thereby facilitating a systematic assessment of attribution benchmarks. Next, we introduce a Backdoor-based eXplainable AI benchmark (BackX) that adheres to the desired fidelity criteria. We theoretically establish the superiority of our approach over the existing benchmarks for well-founded attribution evaluation. With extensive analysis, we also identify a setup for a consistent and fair benchmarking of attribution methods across different underlying methodologies. This setup is ultimately employed for a comprehensive comparison of existing methods using our BackX benchmark. Finally, our analysis also provides guidance for defending against backdoor attacks with the help of attribution methods.
AnoOnly: Semi-Supervised Anomaly Detection without Loss on Normal Data
May 30, 2023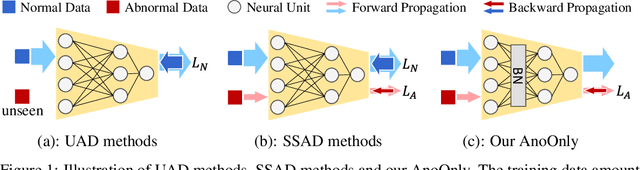
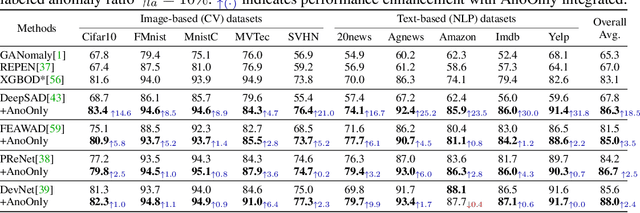

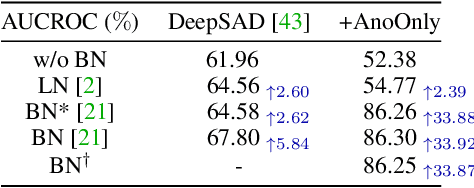
Semi-supervised anomaly detection (SSAD) methods have demonstrated their effectiveness in enhancing unsupervised anomaly detection (UAD) by leveraging few-shot but instructive abnormal instances. However, the dominance of homogeneous normal data over anomalies biases the SSAD models against effectively perceiving anomalies. To address this issue and achieve balanced supervision between heavily imbalanced normal and abnormal data, we develop a novel framework called AnoOnly (Anomaly Only). Unlike existing SSAD methods that resort to strict loss supervision, AnoOnly suspends it and introduces a form of weak supervision for normal data. This weak supervision is instantiated through the utilization of batch normalization, which implicitly performs cluster learning on normal data. When integrated into existing SSAD methods, the proposed AnoOnly demonstrates remarkable performance enhancements across various models and datasets, achieving new state-of-the-art performance. Additionally, our AnoOnly is natively robust to label noise when suffering from data contamination. Our code is publicly available at https://github.com/cool-xuan/AnoOnly.