 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeizhong Ju
Non-asymptotic Convergence of Discrete-time Diffusion Models: New Approach and Improved Rate
Feb 21, 2024
The denoising diffusion model emerges recently as a powerful generative technique that converts noise into data. Theoretical convergence guarantee has been mainly studied for continuous-time diffusion models, and has been obtained for discrete-time diffusion models only for distributions with bounded support in the literature. In this paper, we establish the convergence guarantee for substantially larger classes of distributions under discrete-time diffusion models and further improve the convergence rate for distributions with bounded support. In particular, we first establish the convergence rates for both smooth and general (possibly non-smooth) distributions having finite second moment. We then specialize our results to a number of interesting classes of distributions with explicit parameter dependencies, including distributions with Lipschitz scores, Gaussian mixture distributions, and distributions with bounded support. We further propose a novel accelerated sampler and show that it improves the convergence rates of the corresponding regular sampler by orders of magnitude with respect to all system parameters. For distributions with bounded support, our result improves the dimensional dependence of the previous convergence rate by orders of magnitude. Our study features a novel analysis technique that constructs tilting factor representation of the convergence error and exploits Tweedie's formula for handling Taylor expansion power terms.
Achieving Sample and Computational Efficient Reinforcement Learning by Action Space Reduction via Grouping
Jun 22, 2023


Reinforcement learning often needs to deal with the exponential growth of states and actions when exploring optimal control in high-dimensional spaces (often known as the curse of dimensionality). In this work, we address this issue by learning the inherent structure of action-wise similar MDP to appropriately balance the performance degradation versus sample/computational complexity. In particular, we partition the action spaces into multiple groups based on the similarity in transition distribution and reward function, and build a linear decomposition model to capture the difference between the intra-group transition kernel and the intra-group rewards. Both our theoretical analysis and experiments reveal a \emph{surprising and counter-intuitive result}: while a more refined grouping strategy can reduce the approximation error caused by treating actions in the same group as identical, it also leads to increased estimation error when the size of samples or the computation resources is limited. This finding highlights the grouping strategy as a new degree of freedom that can be optimized to minimize the overall performance loss. To address this issue, we formulate a general optimization problem for determining the optimal grouping strategy, which strikes a balance between performance loss and sample/computational complexity. We further propose a computationally efficient method for selecting a nearly-optimal grouping strategy, which maintains its computational complexity independent of the size of the action space.
Generalization Performance of Transfer Learning: Overparameterized and Underparameterized Regimes
Jun 09, 2023


Transfer learning is a useful technique for achieving improved performance and reducing training costs by leveraging the knowledge gained from source tasks and applying it to target tasks. Assessing the effectiveness of transfer learning relies on understanding the similarity between the ground truth of the source and target tasks. In real-world applications, tasks often exhibit partial similarity, where certain aspects are similar while others are different or irrelevant. To investigate the impact of partial similarity on transfer learning performance, we focus on a linear regression model with two distinct sets of features: a common part shared across tasks and a task-specific part. Our study explores various types of transfer learning, encompassing two options for parameter transfer. By establishing a theoretical characterization on the error of the learned model, we compare these transfer learning options, particularly examining how generalization performance changes with the number of features/parameters in both underparameterized and overparameterized regimes. Furthermore, we provide practical guidelines for determining the number of features in the common and task-specific parts for improved generalization performance. For example, when the total number of features in the source task's learning model is fixed, we show that it is more advantageous to allocate a greater number of redundant features to the task-specific part rather than the common part. Moreover, in specific scenarios, particularly those characterized by high noise levels and small true parameters, sacrificing certain true features in the common part in favor of employing more redundant features in the task-specific part can yield notable benefits.
Achieving Fairness in Multi-Agent Markov Decision Processes Using Reinforcement Learning
Jun 01, 2023

Fairness plays a crucial role in various multi-agent systems (e.g., communication networks, financial markets, etc.). Many multi-agent dynamical interactions can be cast as Markov Decision Processes (MDPs). While existing research has focused on studying fairness in known environments, the exploration of fairness in such systems for unknown environments remains open. In this paper, we propose a Reinforcement Learning (RL) approach to achieve fairness in multi-agent finite-horizon episodic MDPs. Instead of maximizing the sum of individual agents' value functions, we introduce a fairness function that ensures equitable rewards across agents. Since the classical Bellman's equation does not hold when the sum of individual value functions is not maximized, we cannot use traditional approaches. Instead, in order to explore, we maintain a confidence bound of the unknown environment and then propose an online convex optimization based approach to obtain a policy constrained to this confidence region. We show that such an approach achieves sub-linear regret in terms of the number of episodes. Additionally, we provide a probably approximately correct (PAC) guarantee based on the obtained regret bound. We also propose an offline RL algorithm and bound the optimality gap with respect to the optimal fair solution. To mitigate computational complexity, we introduce a policy-gradient type method for the fair objective. Simulation experiments also demonstrate the efficacy of our approach.
Theoretical Characterization of the Generalization Performance of Overfitted Meta-Learning
Apr 09, 2023

Meta-learning has arisen as a successful method for improving training performance by training over many similar tasks, especially with deep neural networks (DNNs). However, the theoretical understanding of when and why overparameterized models such as DNNs can generalize well in meta-learning is still limited. As an initial step towards addressing this challenge, this paper studies the generalization performance of overfitted meta-learning under a linear regression model with Gaussian features. In contrast to a few recent studies along the same line, our framework allows the number of model parameters to be arbitrarily larger than the number of features in the ground truth signal, and hence naturally captures the overparameterized regime in practical deep meta-learning. We show that the overfitted min $\ell_2$-norm solution of model-agnostic meta-learning (MAML) can be beneficial, which is similar to the recent remarkable findings on ``benign overfitting'' and ``double descent'' phenomenon in the classical (single-task) linear regression. However, due to the uniqueness of meta-learning such as task-specific gradient descent inner training and the diversity/fluctuation of the ground-truth signals among training tasks, we find new and interesting properties that do not exist in single-task linear regression. We first provide a high-probability upper bound (under reasonable tightness) on the generalization error, where certain terms decrease when the number of features increases. Our analysis suggests that benign overfitting is more significant and easier to observe when the noise and the diversity/fluctuation of the ground truth of each training task are large. Under this circumstance, we show that the overfitted min $\ell_2$-norm solution can achieve an even lower generalization error than the underparameterized solution.
Theory on Forgetting and Generalization of Continual Learning
Feb 12, 2023
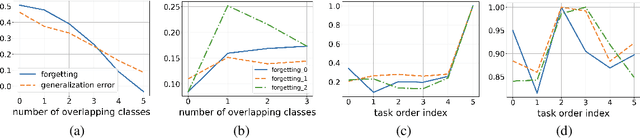
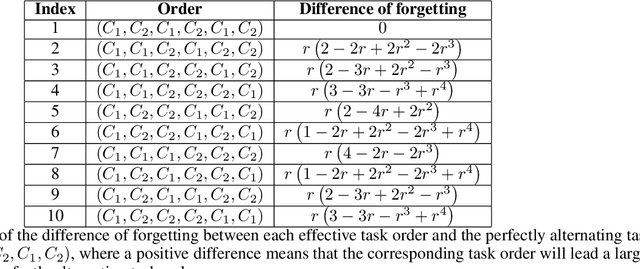
Continual learning (CL), which aims to learn a sequence of tasks, has attracted significant recent attention. However, most work has focused on the experimental performance of CL, and theoretical studies of CL are still limited. In particular, there is a lack of understanding on what factors are important and how they affect "catastrophic forgetting" and generalization performance. To fill this gap, our theoretical analysis, under overparameterized linear models, provides the first-known explicit form of the expected forgetting and generalization error. Further analysis of such a key result yields a number of theoretical explanations about how overparameterization, task similarity, and task ordering affect both forgetting and generalization error of CL. More interestingly, by conducting experiments on real datasets using deep neural networks (DNNs), we show that some of these insights even go beyond the linear models and can be carried over to practical setups. In particular, we use concrete examples to show that our results not only explain some interesting empirical observations in recent studies, but also motivate better practical algorithm designs of CL.
On the Generalization Power of the Overfitted Three-Layer Neural Tangent Kernel Model
Jun 04, 2022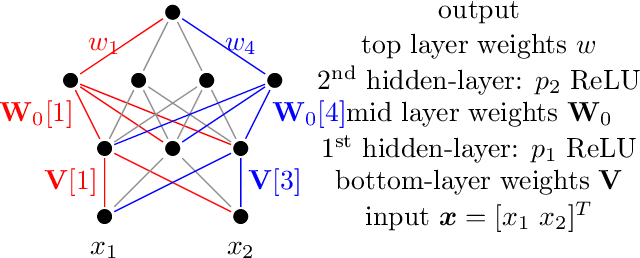



In this paper, we study the generalization performance of overparameterized 3-layer NTK models. We show that, for a specific set of ground-truth functions (which we refer to as the "learnable set"), the test error of the overfitted 3-layer NTK is upper bounded by an expression that decreases with the number of neurons of the two hidden layers. Different from 2-layer NTK where there exists only one hidden-layer, the 3-layer NTK involves interactions between two hidden-layers. Our upper bound reveals that, between the two hidden-layers, the test error descends faster with respect to the number of neurons in the second hidden-layer (the one closer to the output) than with respect to that in the first hidden-layer (the one closer to the input). We also show that the learnable set of 3-layer NTK without bias is no smaller than that of 2-layer NTK models with various choices of bias in the neurons. However, in terms of the actual generalization performance, our results suggest that 3-layer NTK is much less sensitive to the choices of bias than 2-layer NTK, especially when the input dimension is large.
On the Generalization Power of Overfitted Two-Layer Neural Tangent Kernel Models
Mar 09, 2021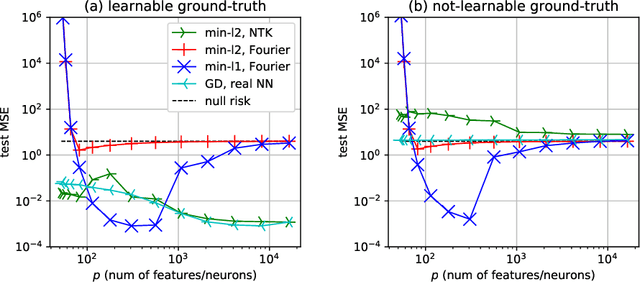
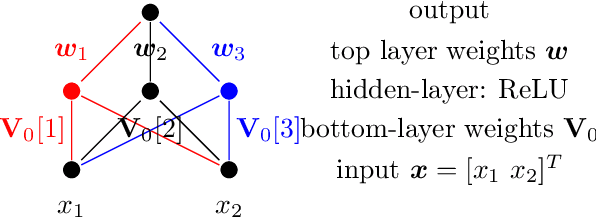
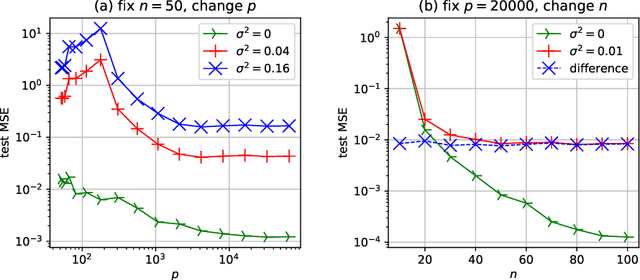
In this paper, we study the generalization performance of min $\ell_2$-norm overfitting solutions for the neural tangent kernel (NTK) model of a two-layer neural network. We show that, depending on the ground-truth function, the test error of overfitted NTK models exhibits characteristics that are different from the "double-descent" of other overparameterized linear models with simple Fourier or Gaussian features. Specifically, for a class of learnable functions, we provide a new upper bound of the generalization error that approaches a small limiting value, even when the number of neurons $p$ approaches infinity. This limiting value further decreases with the number of training samples $n$. For functions outside of this class, we provide a lower bound on the generalization error that does not diminish to zero even when $n$ and $p$ are both large.
Overfitting Can Be Harmless for Basis Pursuit: Only to a Degree
Feb 02, 2020

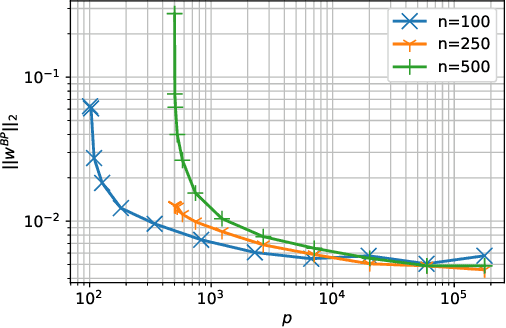
Recently, there have been significant interests in studying the generalization power of linear regression models in the overparameterized regime, with the hope that such analysis may provide the first step towards understanding why overparameterized deep neural networks generalize well even when they overfit the training data. Studies on min $\ell_2$-norm solutions that overfit the training data have suggested that such solutions exhibit the "double-descent" behavior, i.e., the test error decreases with the number of features $p$ in the overparameterized regime when $p$ is larger than the number of samples $n$. However, for linear models with i.i.d. Gaussian features, for large $p$ the model errors of such min $\ell_2$-norm solutions approach the "null risk," i.e., the error of a trivial estimator that always outputs zero, even when the noise is very low. In contrast, we studied the overfitting solution of min $\ell_1$-norm, which is known as Basis Pursuit (BP) in the compressed sensing literature. Under a sparse true linear model with i.i.d. Gaussian features, we show that for a large range of $p$ up to a limit that grows exponentially with $n$, with high probability the model error of BP is upper bounded by a value that decreases with $p$ and is proportional to the noise level. To the best of our knowledge, this is the first result in the literature showing that, without any explicit regularization in such settings where both $p$ and the dimension of data are much larger than $n$, the test errors of a practical-to-compute overfitting solution can exhibit double-descent and approach the order of the noise level independently of the null risk. Our upper bound also reveals a descent floor for BP that is proportional to the noise level. Further, this descent floor is independent of $n$ and the null risk, but increases with the sparsity level of the true model.