 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePengfei Zhou
DiffHarmony: Latent Diffusion Model Meets Image Harmonization
Apr 09, 2024
Image harmonization, which involves adjusting the foreground of a composite image to attain a unified visual consistency with the background, can be conceptualized as an image-to-image translation task. Diffusion models have recently promoted the rapid development of image-to-image translation tasks . However, training diffusion models from scratch is computationally intensive. Fine-tuning pre-trained latent diffusion models entails dealing with the reconstruction error induced by the image compression autoencoder, making it unsuitable for image generation tasks that involve pixel-level evaluation metrics. To deal with these issues, in this paper, we first adapt a pre-trained latent diffusion model to the image harmonization task to generate the harmonious but potentially blurry initial images. Then we implement two strategies: utilizing higher-resolution images during inference and incorporating an additional refinement stage, to further enhance the clarity of the initially harmonized images. Extensive experiments on iHarmony4 datasets demonstrate the superiority of our proposed method. The code and model will be made publicly available at https://github.com/nicecv/DiffHarmony .
Synthesizing Knowledge-enhanced Features for Real-world Zero-shot Food Detection
Feb 14, 2024Food computing brings various perspectives to computer vision like vision-based food analysis for nutrition and health. As a fundamental task in food computing, food detection needs Zero-Shot Detection (ZSD) on novel unseen food objects to support real-world scenarios, such as intelligent kitchens and smart restaurants. Therefore, we first benchmark the task of Zero-Shot Food Detection (ZSFD) by introducing FOWA dataset with rich attribute annotations. Unlike ZSD, fine-grained problems in ZSFD like inter-class similarity make synthesized features inseparable. The complexity of food semantic attributes further makes it more difficult for current ZSD methods to distinguish various food categories. To address these problems, we propose a novel framework ZSFDet to tackle fine-grained problems by exploiting the interaction between complex attributes. Specifically, we model the correlation between food categories and attributes in ZSFDet by multi-source graphs to provide prior knowledge for distinguishing fine-grained features. Within ZSFDet, Knowledge-Enhanced Feature Synthesizer (KEFS) learns knowledge representation from multiple sources (e.g., ingredients correlation from knowledge graph) via the multi-source graph fusion. Conditioned on the fusion of semantic knowledge representation, the region feature diffusion model in KEFS can generate fine-grained features for training the effective zero-shot detector. Extensive evaluations demonstrate the superior performance of our method ZSFDet on FOWA and the widely-used food dataset UECFOOD-256, with significant improvements by 1.8% and 3.7% ZSD mAP compared with the strong baseline RRFS. Further experiments on PASCAL VOC and MS COCO prove that enhancement of the semantic knowledge can also improve the performance on general ZSD. Code and dataset are available at https://github.com/LanceZPF/KEFS.
CMMU: A Benchmark for Chinese Multi-modal Multi-type Question Understanding and Reasoning
Jan 26, 2024Multi-modal large language models(MLLMs) have achieved remarkable progress and demonstrated powerful knowledge comprehension and reasoning abilities. However, the mastery of domain-specific knowledge, which is essential for evaluating the intelligence of MLLMs, continues to be a challenge. Current multi-modal benchmarks for domain-specific knowledge concentrate on multiple-choice questions and are predominantly available in English, which imposes limitations on the comprehensiveness of the evaluation. To this end, we introduce CMMU, a novel benchmark for multi-modal and multi-type question understanding and reasoning in Chinese. CMMU consists of 3,603 questions in 7 subjects, covering knowledge from primary to high school. The questions can be categorized into 3 types: multiple-choice, multiple-response, and fill-in-the-blank, bringing greater challenges to MLLMs. In addition, we propose a rigorous evaluation strategy called ShiftCheck for assessing multiple-choice questions. The strategy aims to reduce position bias, minimize the influence of randomness on correctness, and perform a quantitative analysis of position bias. We evaluate seven open-source MLLMs along with GPT4-V, Gemini-Pro, and Qwen-VL-Plus. The results demonstrate that CMMU poses a significant challenge to the recent MLLMs.
SeeDS: Semantic Separable Diffusion Synthesizer for Zero-shot Food Detection
Oct 07, 2023
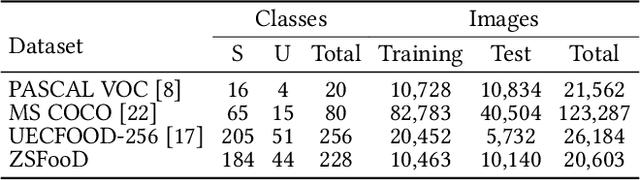
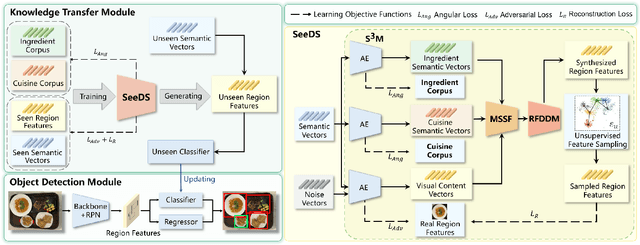
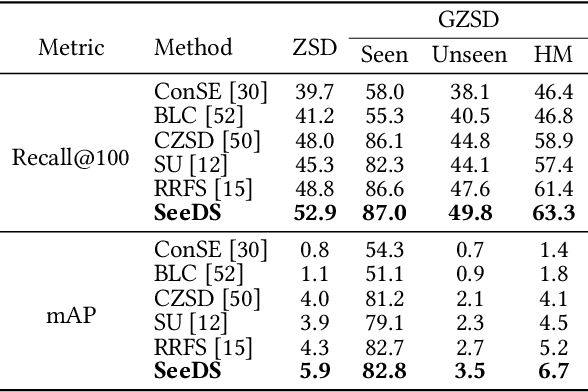
Food detection is becoming a fundamental task in food computing that supports various multimedia applications, including food recommendation and dietary monitoring. To deal with real-world scenarios, food detection needs to localize and recognize novel food objects that are not seen during training, demanding Zero-Shot Detection (ZSD). However, the complexity of semantic attributes and intra-class feature diversity poses challenges for ZSD methods in distinguishing fine-grained food classes. To tackle this, we propose the Semantic Separable Diffusion Synthesizer (SeeDS) framework for Zero-Shot Food Detection (ZSFD). SeeDS consists of two modules: a Semantic Separable Synthesizing Module (S$^3$M) and a Region Feature Denoising Diffusion Model (RFDDM). The S$^3$M learns the disentangled semantic representation for complex food attributes from ingredients and cuisines, and synthesizes discriminative food features via enhanced semantic information. The RFDDM utilizes a novel diffusion model to generate diversified region features and enhances ZSFD via fine-grained synthesized features. Extensive experiments show the state-of-the-art ZSFD performance of our proposed method on two food datasets, ZSFooD and UECFOOD-256. Moreover, SeeDS also maintains effectiveness on general ZSD datasets, PASCAL VOC and MS COCO. The code and dataset can be found at https://github.com/LanceZPF/SeeDS.
ISDA: Position-Aware Instance Segmentation with Deformable Attention
Feb 23, 2022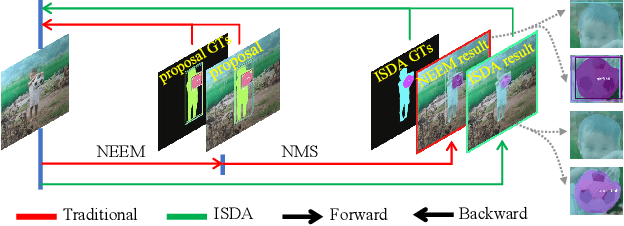
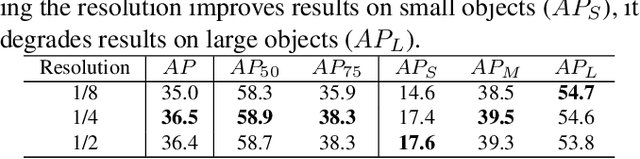
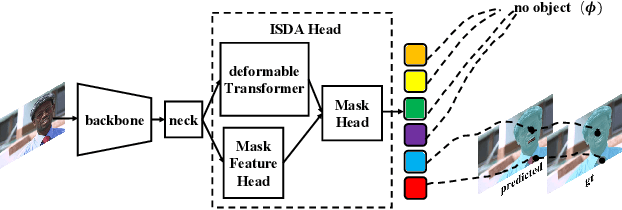
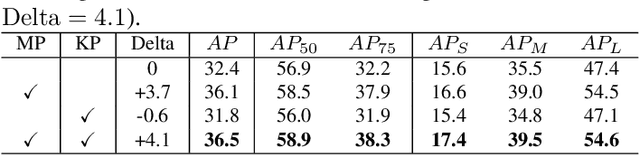
Most instance segmentation models are not end-to-end trainable due to either the incorporation of proposal estimation (RPN) as a pre-processing or non-maximum suppression (NMS) as a post-processing. Here we propose a novel end-to-end instance segmentation method termed ISDA. It reshapes the task into predicting a set of object masks, which are generated via traditional convolution operation with learned position-aware kernels and features of objects. Such kernels and features are learned by leveraging a deformable attention network with multi-scale representation. Thanks to the introduced set-prediction mechanism, the proposed method is NMS-free. Empirically, ISDA outperforms Mask R-CNN (the strong baseline) by 2.6 points on MS-COCO, and achieves leading performance compared with recent models. Code will be available soon.
Boltzmann machines as two-dimensional tensor networks
May 10, 2021
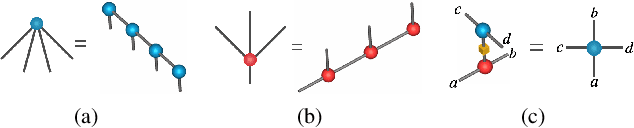
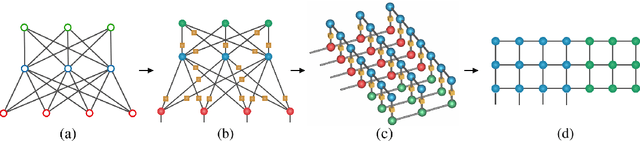
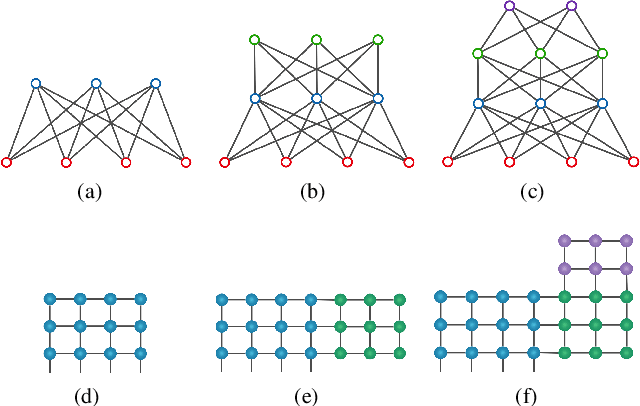
Restricted Boltzmann machines (RBM) and deep Boltzmann machines (DBM) are important models in machine learning, and recently found numerous applications in quantum many-body physics. We show that there are fundamental connections between them and tensor networks. In particular, we demonstrate that any RBM and DBM can be exactly represented as a two-dimensional tensor network. This representation gives an understanding of the expressive power of RBM and DBM using entanglement structures of the tensor networks, also provides an efficient tensor network contraction algorithm for the computing partition function of RBM and DBM. Using numerical experiments, we demonstrate that the proposed algorithm is much more accurate than the state-of-the-art machine learning methods in estimating the partition function of restricted Boltzmann machines and deep Boltzmann machines, and have potential applications in training deep Boltzmann machines for general machine learning tasks.
Dynamic Virtual Graph Significance Networks for Predicting Influenza
Feb 16, 2021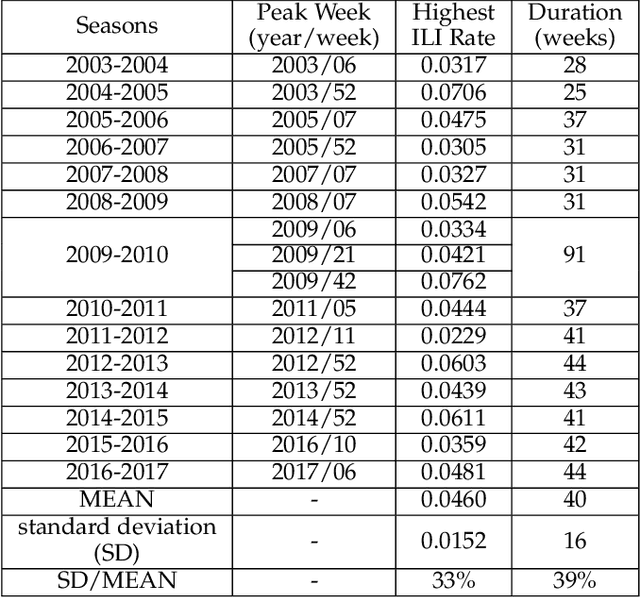
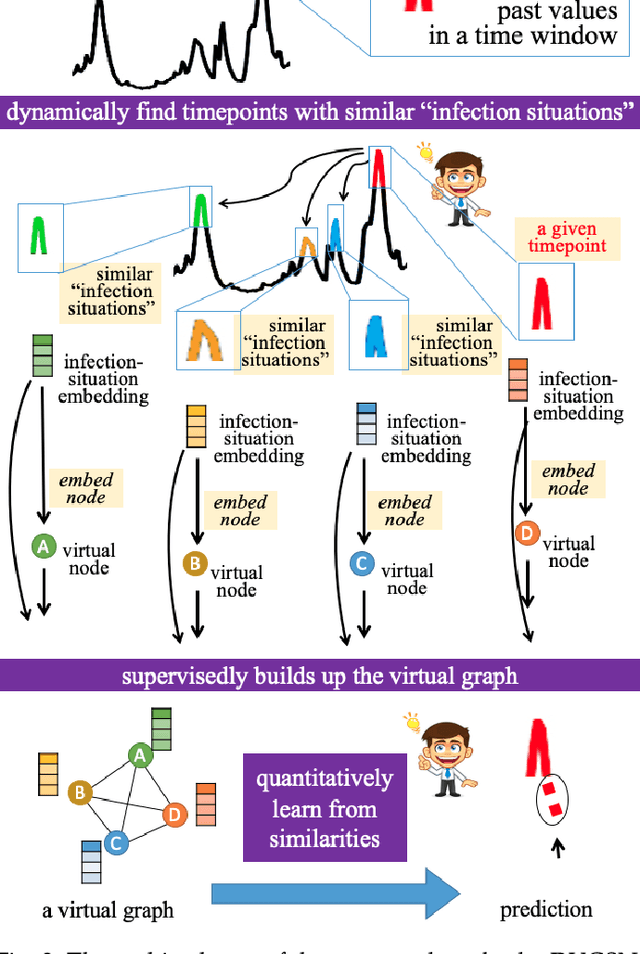

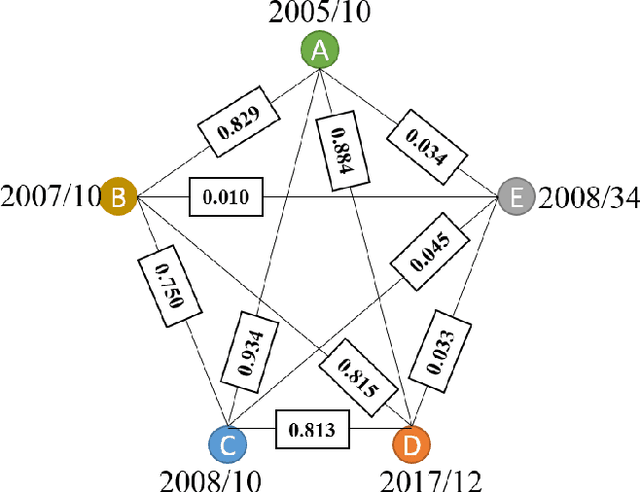
Graph-structured data and their related algorithms have attracted significant attention in many fields, such as influenza prediction in public health. However, the variable influenza seasonality, occasional pandemics, and domain knowledge pose great challenges to construct an appropriate graph, which could impair the strength of the current popular graph-based algorithms to perform data analysis. In this study, we develop a novel method, Dynamic Virtual Graph Significance Networks (DVGSN), which can supervisedly and dynamically learn from similar "infection situations" in historical timepoints. Representation learning on the dynamic virtual graph can tackle the varied seasonality and pandemics, and therefore improve the performance. The extensive experiments on real-world influenza data demonstrate that DVGSN significantly outperforms the current state-of-the-art methods. To the best of our knowledge, this is the first attempt to supervisedly learn a dynamic virtual graph for time-series prediction tasks. Moreover, the proposed method needs less domain knowledge to build a graph in advance and has rich interpretability, which makes the method more acceptable in the fields of public health, life sciences, and so on.
Phase transitions and optimal algorithms for semi-supervised classifications on graphs: from belief propagation to graph convolution network
Dec 10, 2019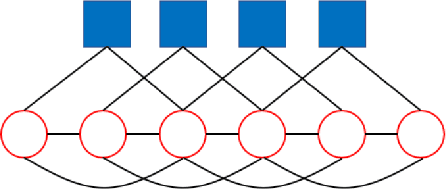
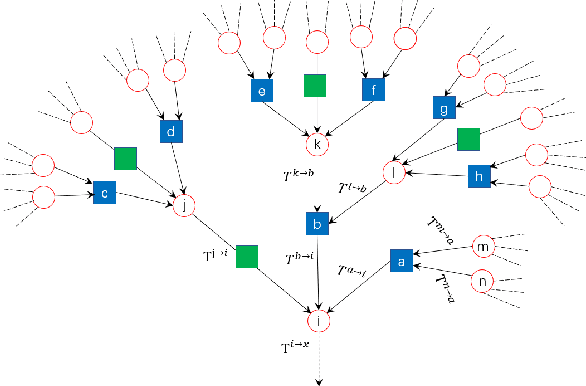
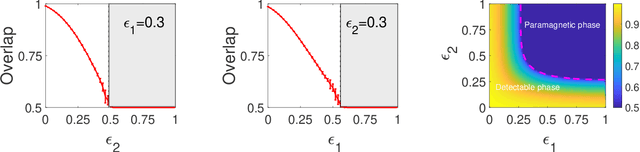
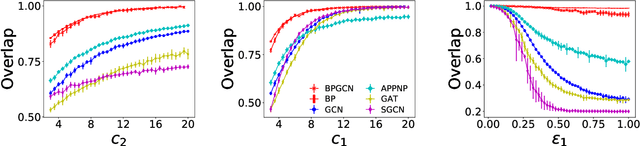
We perform theoretical and algorithmic studies for the problem of clustering and semi-supervised classification on graphs with both pairwise relational information and single-point feature information, upon a joint stochastic block model for generating synthetic graphs with both edges and node features. Asymptotically exact analysis based on the Bayesian inference of the underlying model are conducted, using the cavity method in statistical physics. Theoretically, we identify a phase transition of the generative model, which puts fundamental limits on the ability of all possible algorithms in the clustering task of the underlying model. Algorithmically, we propose a belief propagation algorithm that is asymptotically optimal on the generative model, and can be further extended to a belief propagation graph convolution neural network (BPGCN) for semi-supervised classification on graphs. For the first time, well-controlled benchmark datasets with asymptotially exact properties and optimal solutions could be produced for the evaluation of graph convolution neural networks, and for the theoretical understanding of their strengths and weaknesses. In particular, on these synthetic benchmark networks we observe that existing graph convolution neural networks are subject to an sparsity issue and an ovefitting issue in practice, both of which are successfully overcome by our BPGCN. Moreover, when combined with classic neural network methods, BPGCN yields extraordinary classification performances on some real-world datasets that have never been achieved before.
Phase transitions and optimal algorithms in the semi-supervised classfications in graphs: from belief propagation to convolution neural networks
Nov 01, 2019By analyzing Bayesian inference of generative model for random networks with both relations (edges) and node features (discrete labels), we perform an asymptotically exact analysis of the semi-supervised classfication problems on graph-structured data using the cavity method of statistical physics. We unveil detectability phase transitions which put fundamental limit on ability of classfications for all possible algorithms. Our theory naturally converts to a message passing algorithm which works all the way down to the phase transition in the underlying generative model, and can be translated to a graph convolution neural network algorithm which greatly outperforms existing algorithms including popular graph neural networks in synthetic networks. When applied to real-world datasets, our algorithm achieves comparable performance with the state-of-the art algorithms. Our approach provides benchmark datasets with continuously tunable parameters and optimal results, which can be used to evaluate performance of exiting graph neural networks, and to find and understand their strengths and limitations. In particular, we observe that popular GCNs have sparsity issue and ovefitting issue on large synthetic benchmarks, we also show how to overcome the issues by combining strengths of our approach.