 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePer-Arne Andersen
Contracting Tsetlin Machine with Absorbing Automata
Oct 17, 2023
In this paper, we introduce a sparse Tsetlin Machine (TM) with absorbing Tsetlin Automata (TA) states. In brief, the TA of each clause literal has both an absorbing Exclude- and an absorbing Include state, making the learning scheme absorbing instead of ergodic. When a TA reaches an absorbing state, it will never leave that state again. If the absorbing state is an Exclude state, both the automaton and the literal can be removed from further consideration. The literal will as a result never participates in that clause. If the absorbing state is an Include state, on the other hand, the literal is stored as a permanent part of the clause while the TA is discarded. A novel sparse data structure supports these updates by means of three action lists: Absorbed Include, Include, and Exclude. By updating these lists, the TM gets smaller and smaller as the literals and their TA withdraw. In this manner, the computation accelerates during learning, leading to faster learning and less energy consumption.
Generalized Convergence Analysis of Tsetlin Machines: A Probabilistic Approach to Concept Learning
Oct 03, 2023Tsetlin Machines (TMs) have garnered increasing interest for their ability to learn concepts via propositional formulas and their proven efficiency across various application domains. Despite this, the convergence proof for the TMs, particularly for the AND operator (\emph{conjunction} of literals), in the generalized case (inputs greater than two bits) remains an open problem. This paper aims to fill this gap by presenting a comprehensive convergence analysis of Tsetlin automaton-based Machine Learning algorithms. We introduce a novel framework, referred to as Probabilistic Concept Learning (PCL), which simplifies the TM structure while incorporating dedicated feedback mechanisms and dedicated inclusion/exclusion probabilities for literals. Given $n$ features, PCL aims to learn a set of conjunction clauses $C_i$ each associated with a distinct inclusion probability $p_i$. Most importantly, we establish a theoretical proof confirming that, for any clause $C_k$, PCL converges to a conjunction of literals when $0.5<p_k<1$. This result serves as a stepping stone for future research on the convergence properties of Tsetlin automaton-based learning algorithms. Our findings not only contribute to the theoretical understanding of Tsetlin Machines but also have implications for their practical application, potentially leading to more robust and interpretable machine learning models.
Learning Minimalistic Tsetlin Machine Clauses with Markov Boundary-Guided Pruning
Sep 12, 2023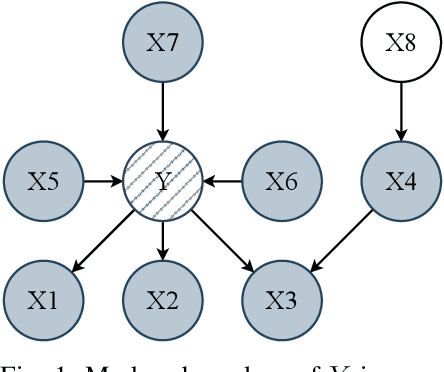


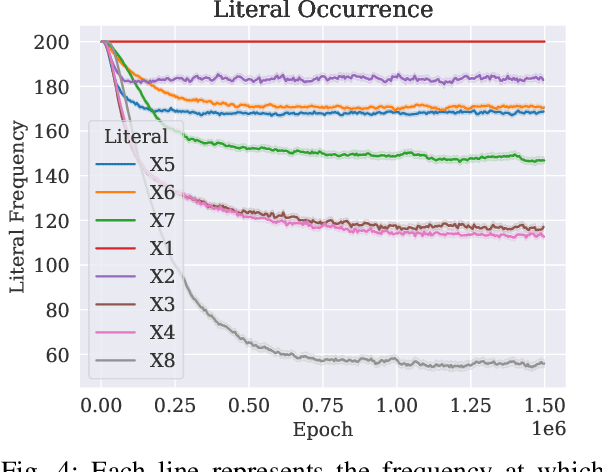
A set of variables is the Markov blanket of a random variable if it contains all the information needed for predicting the variable. If the blanket cannot be reduced without losing useful information, it is called a Markov boundary. Identifying the Markov boundary of a random variable is advantageous because all variables outside the boundary are superfluous. Hence, the Markov boundary provides an optimal feature set. However, learning the Markov boundary from data is challenging for two reasons. If one or more variables are removed from the Markov boundary, variables outside the boundary may start providing information. Conversely, variables within the boundary may stop providing information. The true role of each candidate variable is only manifesting when the Markov boundary has been identified. In this paper, we propose a new Tsetlin Machine (TM) feedback scheme that supplements Type I and Type II feedback. The scheme introduces a novel Finite State Automaton - a Context-Specific Independence Automaton. The automaton learns which features are outside the Markov boundary of the target, allowing them to be pruned from the TM during learning. We investigate the new scheme empirically, showing how it is capable of exploiting context-specific independence to find Markov boundaries. Further, we provide a theoretical analysis of convergence. Our approach thus connects the field of Bayesian networks (BN) with TMs, potentially opening up for synergies when it comes to inference and learning, including TM-produced Bayesian knowledge bases and TM-based Bayesian inference.
DeNISE: Deep Networks for Improved Segmentation Edges
Sep 05, 2023This paper presents Deep Networks for Improved Segmentation Edges (DeNISE), a novel data enhancement technique using edge detection and segmentation models to improve the boundary quality of segmentation masks. DeNISE utilizes the inherent differences in two sequential deep neural architectures to improve the accuracy of the predicted segmentation edge. DeNISE applies to all types of neural networks and is not trained end-to-end, allowing rapid experiments to discover which models complement each other. We test and apply DeNISE for building segmentation in aerial images. Aerial images are known for difficult conditions as they have a low resolution with optical noise, such as reflections, shadows, and visual obstructions. Overall the paper demonstrates the potential for DeNISE. Using the technique, we improve the baseline results with a building IoU of 78.9%.
Loss and Reward Weighing for increased learning in Distributed Reinforcement Learning
Apr 25, 2023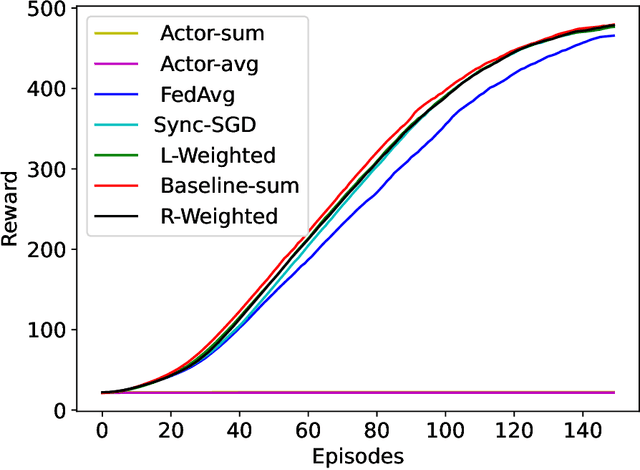

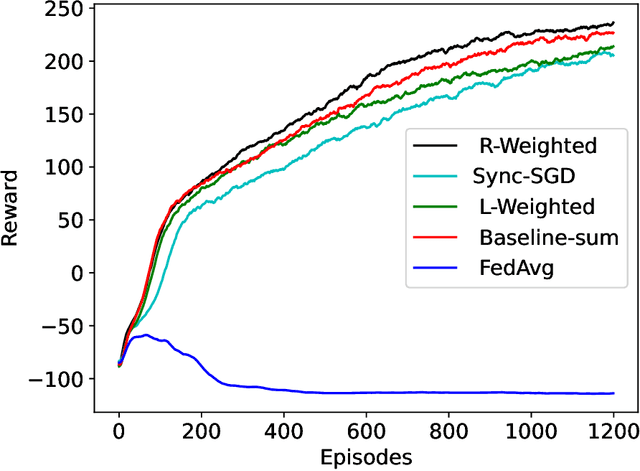
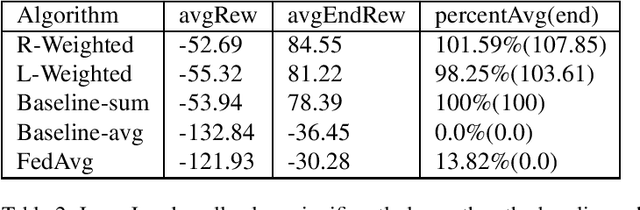
This paper introduces two learning schemes for distributed agents in Reinforcement Learning (RL) environments, namely Reward-Weighted (R-Weighted) and Loss-Weighted (L-Weighted) gradient merger. The R/L weighted methods replace standard practices for training multiple agents, such as summing or averaging the gradients. The core of our methods is to scale the gradient of each actor based on how high the reward (for R-Weighted) or the loss (for L-Weighted) is compared to the other actors. During training, each agent operates in differently initialized versions of the same environment, which gives different gradients from different actors. In essence, the R-Weights and L-Weights of each agent inform the other agents of its potential, which again reports which environment should be prioritized for learning. This approach of distributed learning is possible because environments that yield higher rewards, or low losses, have more critical information than environments that yield lower rewards or higher losses. We empirically demonstrate that the R-Weighted methods work superior to the state-of-the-art in multiple RL environments.
Contrastive Transformer: Contrastive Learning Scheme with Transformer innate Patches
Mar 26, 2023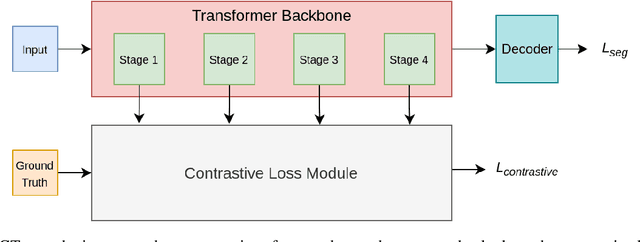
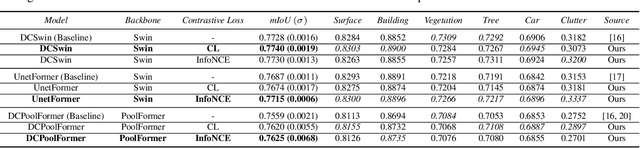
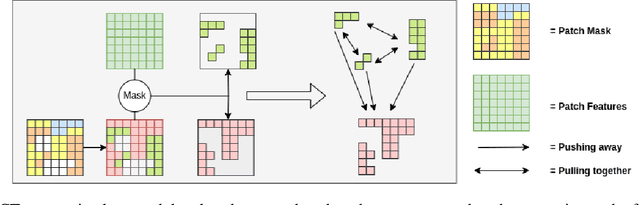
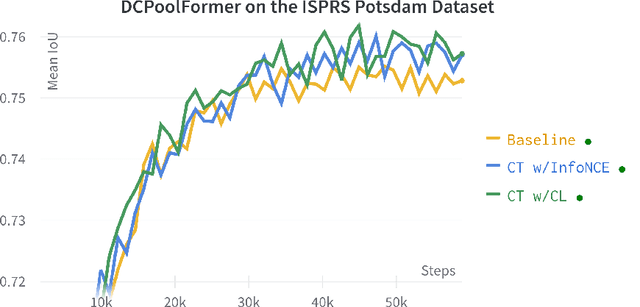
This paper presents Contrastive Transformer, a contrastive learning scheme using the Transformer innate patches. Contrastive Transformer enables existing contrastive learning techniques, often used for image classification, to benefit dense downstream prediction tasks such as semantic segmentation. The scheme performs supervised patch-level contrastive learning, selecting the patches based on the ground truth mask, subsequently used for hard-negative and hard-positive sampling. The scheme applies to all vision-transformer architectures, is easy to implement, and introduces minimal additional memory footprint. Additionally, the scheme removes the need for huge batch sizes, as each patch is treated as an image. We apply and test Contrastive Transformer for the case of aerial image segmentation, known for low-resolution data, large class imbalance, and similar semantic classes. We perform extensive experiments to show the efficacy of the Contrastive Transformer scheme on the ISPRS Potsdam aerial image segmentation dataset. Additionally, we show the generalizability of our scheme by applying it to multiple inherently different Transformer architectures. Ultimately, the results show a consistent increase in mean IoU across all classes.
CaiRL: A High-Performance Reinforcement Learning Environment Toolkit
Oct 03, 2022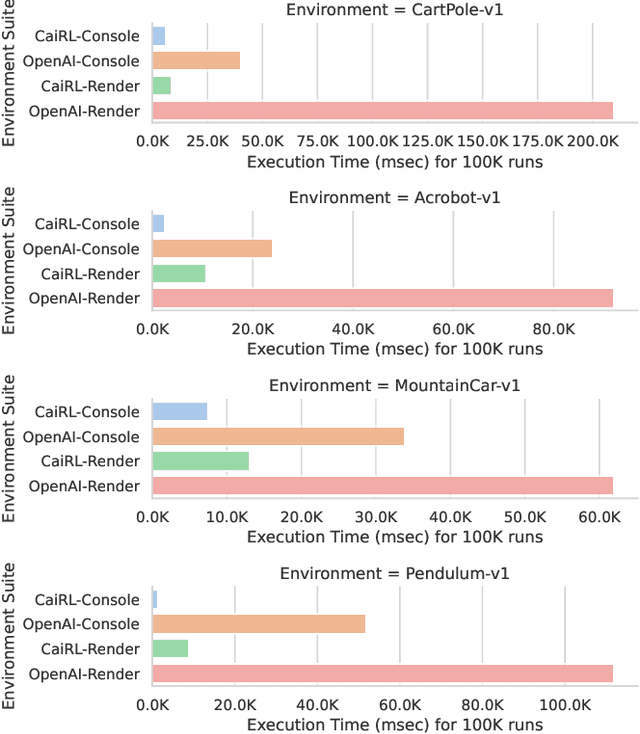
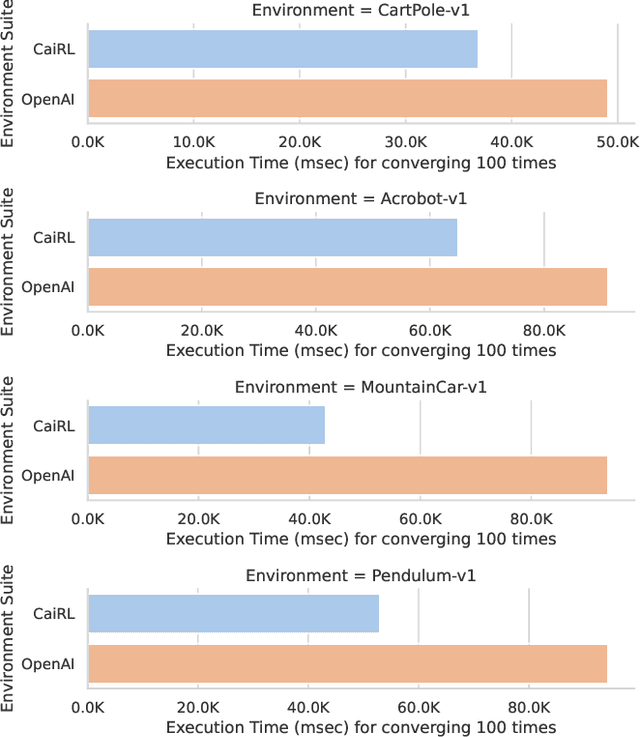
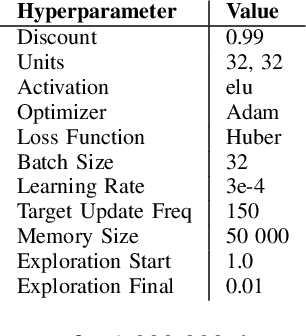
This paper addresses the dire need for a platform that efficiently provides a framework for running reinforcement learning (RL) experiments. We propose the CaiRL Environment Toolkit as an efficient, compatible, and more sustainable alternative for training learning agents and propose methods to develop more efficient environment simulations. There is an increasing focus on developing sustainable artificial intelligence. However, little effort has been made to improve the efficiency of running environment simulations. The most popular development toolkit for reinforcement learning, OpenAI Gym, is built using Python, a powerful but slow programming language. We propose a toolkit written in C++ with the same flexibility level but works orders of magnitude faster to make up for Python's inefficiency. This would drastically cut climate emissions. CaiRL also presents the first reinforcement learning toolkit with a built-in JVM and Flash support for running legacy flash games for reinforcement learning research. We demonstrate the effectiveness of CaiRL in the classic control benchmark, comparing the execution speed to OpenAI Gym. Furthermore, we illustrate that CaiRL can act as a drop-in replacement for OpenAI Gym to leverage significantly faster training speeds because of the reduced environment computation time.
* Published in 2022 IEEE Conference on Games (CoG)
CostNet: An End-to-End Framework for Goal-Directed Reinforcement Learning
Oct 03, 2022Reinforcement Learning (RL) is a general framework concerned with an agent that seeks to maximize rewards in an environment. The learning typically happens through trial and error using explorative methods, such as epsilon-greedy. There are two approaches, model-based and model-free reinforcement learning, that show concrete results in several disciplines. Model-based RL learns a model of the environment for learning the policy while model-free approaches are fully explorative and exploitative without considering the underlying environment dynamics. Model-free RL works conceptually well in simulated environments, and empirical evidence suggests that trial and error lead to a near-optimal behavior with enough training. On the other hand, model-based RL aims to be sample efficient, and studies show that it requires far less training in the real environment for learning a good policy. A significant challenge with RL is that it relies on a well-defined reward function to work well for complex environments and such a reward function is challenging to define. Goal-Directed RL is an alternative method that learns an intrinsic reward function with emphasis on a few explored trajectories that reveals the path to the goal state. This paper introduces a novel reinforcement learning algorithm for predicting the distance between two states in a Markov Decision Process. The learned distance function works as an intrinsic reward that fuels the agent's learning. Using the distance-metric as a reward, we show that the algorithm performs comparably to model-free RL while having significantly better sample-efficiently in several test environments.
* 14 pages, 5 figures, In Proceedings of the International Conference on Innovative Techniques and Applications of Artificial Intelligence, SGAI2020
Interpretable Option Discovery using Deep Q-Learning and Variational Autoencoders
Oct 03, 2022Deep Reinforcement Learning (RL) is unquestionably a robust framework to train autonomous agents in a wide variety of disciplines. However, traditional deep and shallow model-free RL algorithms suffer from low sample efficiency and inadequate generalization for sparse state spaces. The options framework with temporal abstractions is perhaps the most promising method to solve these problems, but it still has noticeable shortcomings. It only guarantees local convergence, and it is challenging to automate initiation and termination conditions, which in practice are commonly hand-crafted. Our proposal, the Deep Variational Q-Network (DVQN), combines deep generative- and reinforcement learning. The algorithm finds good policies from a Gaussian distributed latent-space, which is especially useful for defining options. The DVQN algorithm uses MSE with KL-divergence as regularization, combined with traditional Q-Learning updates. The algorithm learns a latent-space that represents good policies with state clusters for options. We show that the DVQN algorithm is a promising approach for identifying initiation and termination conditions for option-based reinforcement learning. Experiments show that the DVQN algorithm, with automatic initiation and termination, has comparable performance to Rainbow and can maintain stability when trained for extended periods after convergence.
* 12 pages, 5 figures, Proceedings of the 3rd International Conference on Intelligent Technologies and Applications
Towards Model-based Reinforcement Learning for Industry-near Environments
Jul 27, 2019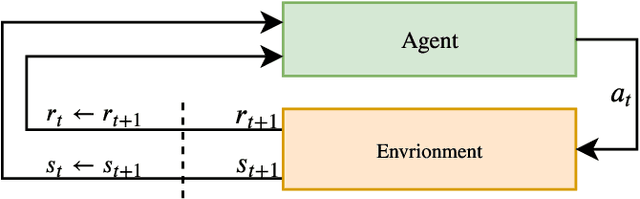
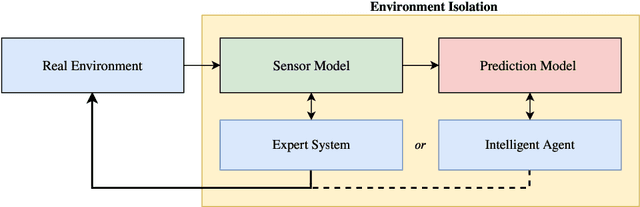
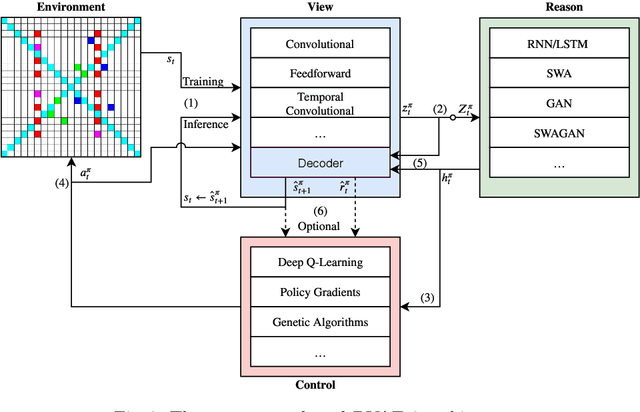
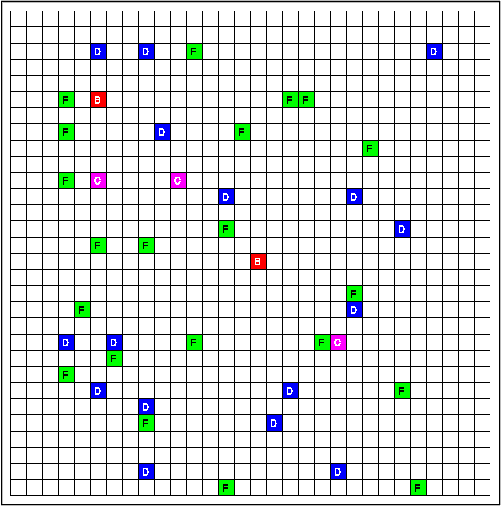
Deep reinforcement learning has over the past few years shown great potential in learning near-optimal control in complex simulated environments with little visible information. Rainbow (Q-Learning) and PPO (Policy Optimisation) have shown outstanding performance in a variety of tasks, including Atari 2600, MuJoCo, and Roboschool test suite. While these algorithms are fundamentally different, both suffer from high variance, low sample efficiency, and hyperparameter sensitivity that in practice, make these algorithms a no-go for critical operations in the industry. On the other hand, model-based reinforcement learning focuses on learning the transition dynamics between states in an environment. If these environment dynamics are adequately learned, a model-based approach is perhaps the most sample efficient method for learning agents to act in an environment optimally. The traits of model-based reinforcement are ideal for real-world environments where sampling is slow and for mission-critical operations. In the warehouse industry, there is an increasing motivation to minimise time and to maximise production. Currently, autonomous agents act suboptimally using handcrafted policies for significant portions of the state-space. In this paper, we present The Dreaming Variational Autoencoder v2 (DVAE-2), a model-based reinforcement learning algorithm that increases sample efficiency, hence enable algorithms with low sample efficiency function better in real-world environments. We introduce Deep Warehouse, a simulated environment for industry-near testing of autonomous agents in grid-based warehouses. Finally, we illustrate that DVAE-2 improves the sample efficiency for the Deep Warehouse compared to model-free methods.