 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeter R. Wurman
Composing Efficient, Robust Tests for Policy Selection
Jun 12, 2023
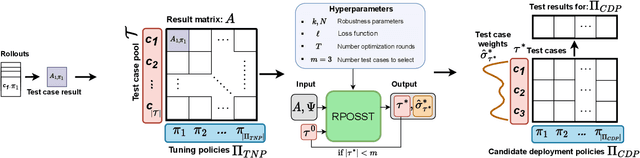

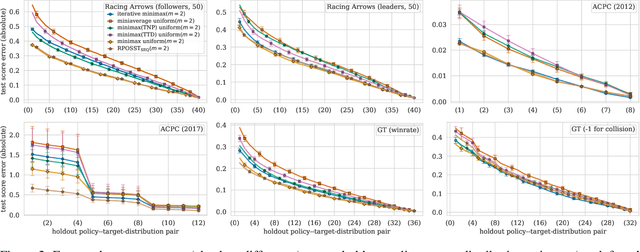
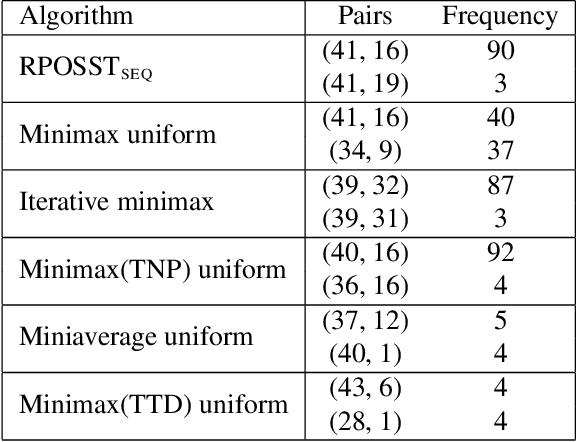
Modern reinforcement learning systems produce many high-quality policies throughout the learning process. However, to choose which policy to actually deploy in the real world, they must be tested under an intractable number of environmental conditions. We introduce RPOSST, an algorithm to select a small set of test cases from a larger pool based on a relatively small number of sample evaluations. RPOSST treats the test case selection problem as a two-player game and optimizes a solution with provable $k$-of-$N$ robustness, bounding the error relative to a test that used all the test cases in the pool. Empirical results demonstrate that RPOSST finds a small set of test cases that identify high quality policies in a toy one-shot game, poker datasets, and a high-fidelity racing simulator.
Value Function Decomposition for Iterative Design of Reinforcement Learning Agents
Jun 24, 2022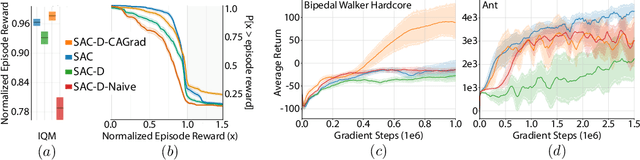

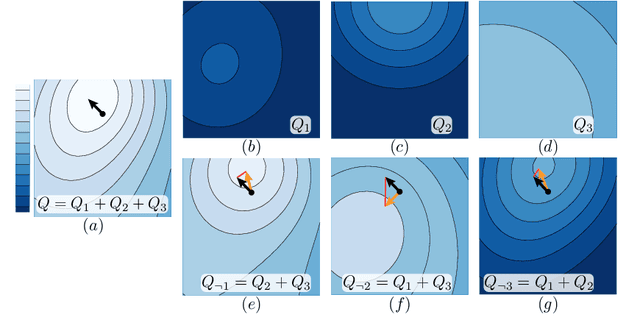

Designing reinforcement learning (RL) agents is typically a difficult process that requires numerous design iterations. Learning can fail for a multitude of reasons, and standard RL methods provide too few tools to provide insight into the exact cause. In this paper, we show how to integrate value decomposition into a broad class of actor-critic algorithms and use it to assist in the iterative agent-design process. Value decomposition separates a reward function into distinct components and learns value estimates for each. These value estimates provide insight into an agent's learning and decision-making process and enable new training methods to mitigate common problems. As a demonstration, we introduce SAC-D, a variant of soft actor-critic (SAC) adapted for value decomposition. SAC-D maintains similar performance to SAC, while learning a larger set of value predictions. We also introduce decomposition-based tools that exploit this information, including a new reward influence metric, which measures each reward component's effect on agent decision-making. Using these tools, we provide several demonstrations of decomposition's use in identifying and addressing problems in the design of both environments and agents. Value decomposition is broadly applicable and easy to incorporate into existing algorithms and workflows, making it a powerful tool in an RL practitioner's toolbox.
Analysis and Observations from the First Amazon Picking Challenge
Sep 22, 2017



This paper presents a overview of the inaugural Amazon Picking Challenge along with a summary of a survey conducted among the 26 participating teams. The challenge goal was to design an autonomous robot to pick items from a warehouse shelf. This task is currently performed by human workers, and there is hope that robots can someday help increase efficiency and throughput while lowering cost. We report on a 28-question survey posed to the teams to learn about each team's background, mechanism design, perception apparatus, planning and control approach. We identify trends in this data, correlate it with each team's success in the competition, and discuss observations and lessons learned based on survey results and the authors' personal experiences during the challenge.
Optimal Factory Scheduling using Stochastic Dominance A*
Feb 13, 2013



We examine a standard factory scheduling problem with stochastic processing and setup times, minimizing the expectation of the weighted number of tardy jobs. Because the costs of operators in the schedule are stochastic and sequence dependent, standard dynamic programming algorithms such as A* may fail to find the optimal schedule. The SDA* (Stochastic Dominance A*) algorithm remedies this difficulty by relaxing the pruning condition. We present an improved state-space search formulation for these problems and discuss the conditions under which stochastic scheduling problems can be solved optimally using SDA*. In empirical testing on randomly generated problems, we found that in 70%, the expected cost of the optimal stochastic solution is lower than that of the solution derived using a deterministic approximation, with comparable search effort.