 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeter Tino
Interpretable Models Capable of Handling Systematic Missingness in Imbalanced Classes and Heterogeneous Datasets
Jun 04, 2022
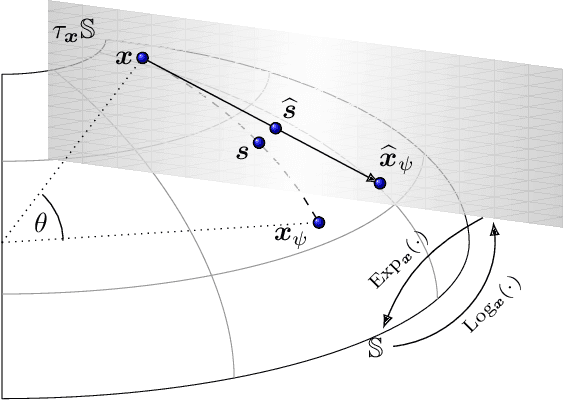
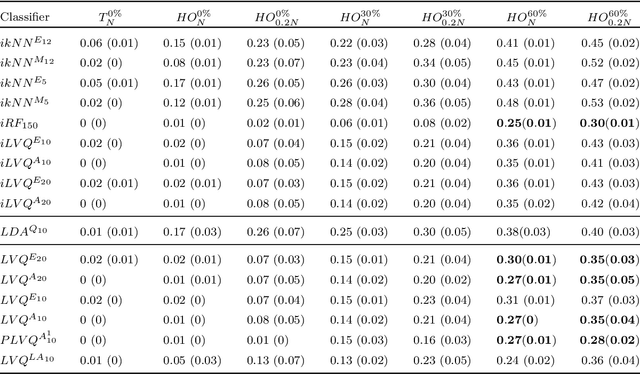

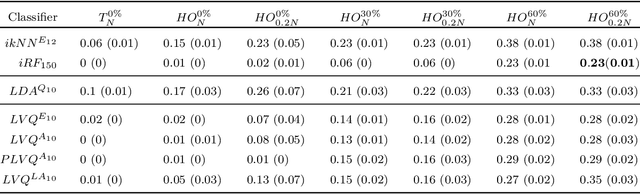
Application of interpretable machine learning techniques on medical datasets facilitate early and fast diagnoses, along with getting deeper insight into the data. Furthermore, the transparency of these models increase trust among application domain experts. Medical datasets face common issues such as heterogeneous measurements, imbalanced classes with limited sample size, and missing data, which hinder the straightforward application of machine learning techniques. In this paper we present a family of prototype-based (PB) interpretable models which are capable of handling these issues. The models introduced in this contribution show comparable or superior performance to alternative techniques applicable in such situations. However, unlike ensemble based models, which have to compromise on easy interpretation, the PB models here do not. Moreover we propose a strategy of harnessing the power of ensembles while maintaining the intrinsic interpretability of the PB models, by averaging the model parameter manifolds. All the models were evaluated on a synthetic (publicly available dataset) in addition to detailed analyses of two real-world medical datasets (one publicly available). Results indicated that the models and strategies we introduced addressed the challenges of real-world medical data, while remaining computationally inexpensive and transparent, as well as similar or superior in performance compared to their alternatives.
Probabilistic Learning Vector Quantization on Manifold of Symmetric Positive Definite Matrices
Feb 01, 2021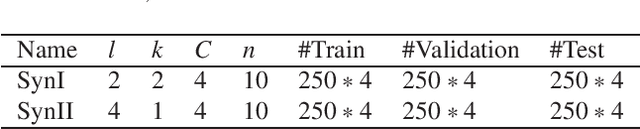

In this paper, we develop a new classification method for manifold-valued data in the framework of probabilistic learning vector quantization. In many classification scenarios, the data can be naturally represented by symmetric positive definite matrices, which are inherently points that live on a curved Riemannian manifold. Due to the non-Euclidean geometry of Riemannian manifolds, traditional Euclidean machine learning algorithms yield poor results on such data. In this paper, we generalize the probabilistic learning vector quantization algorithm for data points living on the manifold of symmetric positive definite matrices equipped with Riemannian natural metric (affine-invariant metric). By exploiting the induced Riemannian distance, we derive the probabilistic learning Riemannian space quantization algorithm, obtaining the learning rule through Riemannian gradient descent. Empirical investigations on synthetic data, image data , and motor imagery EEG data demonstrate the superior performance of the proposed method.
LAAT: Locally Aligned Ant Technique for detecting manifolds of varying density
Sep 17, 2020
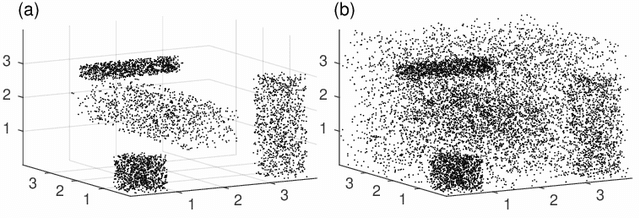

Dimensionality reduction and clustering are often used as preliminary steps for many complex machine learning tasks. The presence of noise and outliers can deteriorate the performance of such preprocessing and therefore impair the subsequent analysis tremendously. In manifold learning, several studies indicate solutions for removing background noise or noise close to the structure when the density is substantially higher than that exhibited by the noise. However, in many applications, including astronomical datasets, the density varies alongside manifolds that are buried in a noisy background. We propose a novel method to extract manifolds in the presence of noise based on the idea of Ant colony optimization. In contrast to the existing random walk solutions, our technique captures points which are locally aligned with major directions of the manifold. Moreover, we empirically show that the biologically inspired formulation of ant pheromone reinforces this behavior enabling it to recover multiple manifolds embedded in extremely noisy data clouds. The algorithm's performance is demonstrated in comparison to the state-of-the-art approaches, such as Markov Chain, LLPD, and Disperse, on several synthetic and real astronomical datasets stemming from an N-body simulation of a cosmological volume.
Visualisation and knowledge discovery from interpretable models
May 08, 2020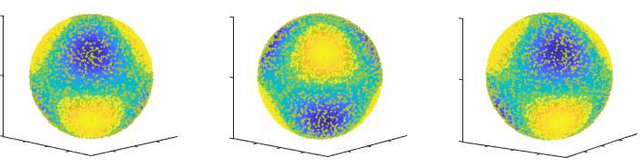

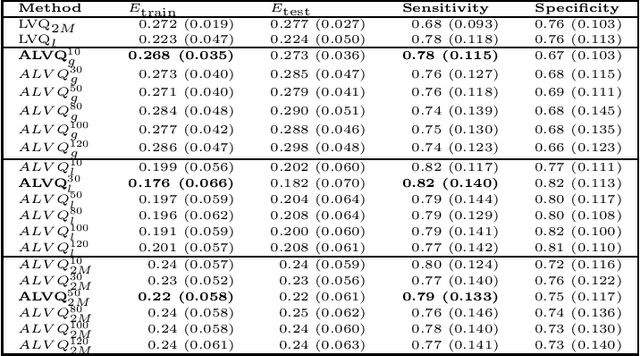

Increasing number of sectors which affect human lives, are using Machine Learning (ML) tools. Hence the need for understanding their working mechanism and evaluating their fairness in decision-making, are becoming paramount, ushering in the era of Explainable AI (XAI). In this contribution we introduced a few intrinsically interpretable models which are also capable of dealing with missing values, in addition to extracting knowledge from the dataset and about the problem. These models are also capable of visualisation of the classifier and decision boundaries: they are the angle based variants of Learning Vector Quantization. We have demonstrated the algorithms on a synthetic dataset and a real-world one (heart disease dataset from the UCI repository). The newly developed classifiers helped in investigating the complexities of the UCI dataset as a multiclass problem. The performance of the developed classifiers were comparable to those reported in literature for this dataset, with additional value of interpretability, when the dataset was treated as a binary class problem.
Input representation in recurrent neural networks dynamics
Mar 24, 2020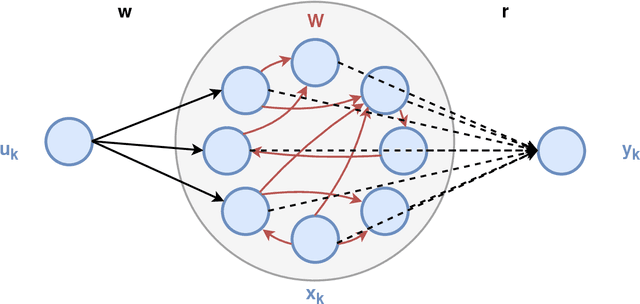
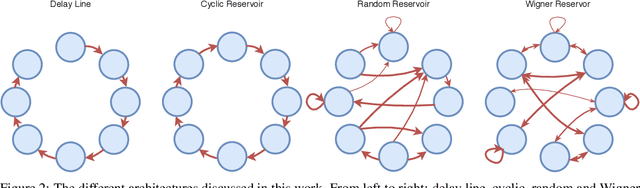
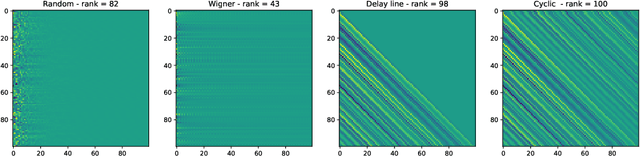

Reservoir computing is a popular approach to design recurrent neural networks, due to its training simplicity and its approximation performance. The recurrent part of these networks is not trained (e.g. via gradient descent), making them appealing for analytical studies, raising the interest of a vast community of researcher spanning from dynamical systems to neuroscience. It emerges that, even in the simple linear case, the working principle of these networks is not fully understood and the applied research is usually driven by heuristics. A novel analysis of the dynamics of such networks is proposed, which allows one to express the state evolution using the controllability matrix. Such a matrix encodes salient characteristics of the network dynamics: in particular, its rank can be used as an input-indepedent measure of the memory of the network. Using the proposed approach, it is possible to compare different architectures and explain why a cyclic topology achieves favourable results.
Feature Relevance Determination for Ordinal Regression in the Context of Feature Redundancies and Privileged Information
Dec 10, 2019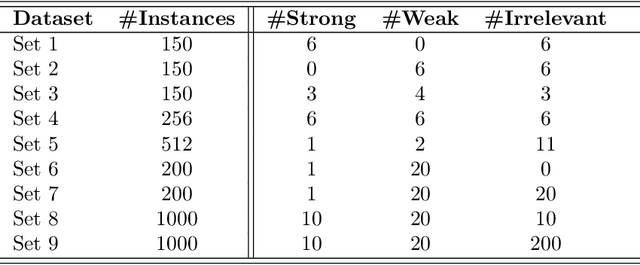
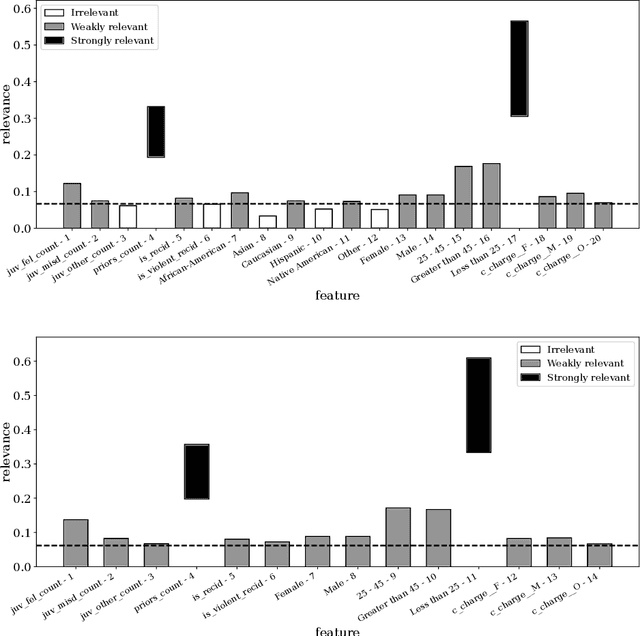
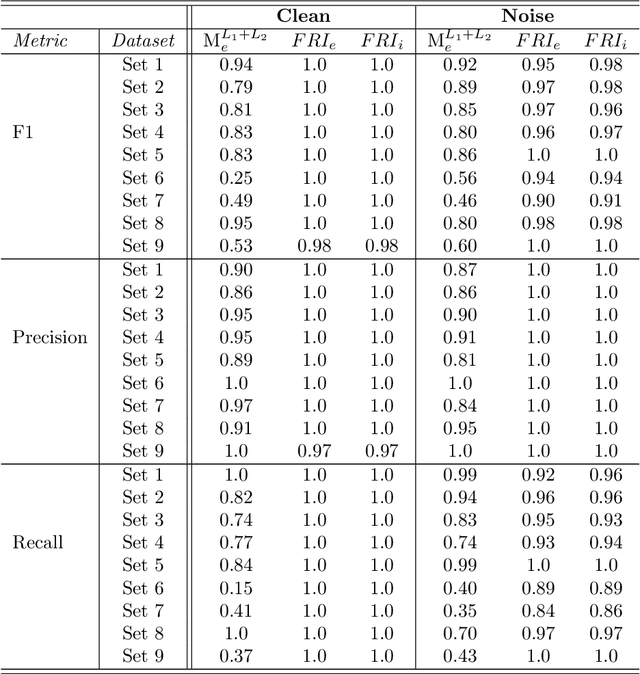
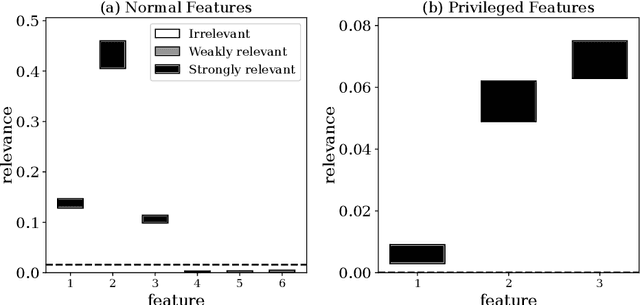
Advances in machine learning technologies have led to increasingly powerful models in particular in the context of big data. Yet, many application scenarios demand for robustly interpretable models rather than optimum model accuracy; as an example, this is the case if potential biomarkers or causal factors should be discovered based on a set of given measurements. In this contribution, we focus on feature selection paradigms, which enable us to uncover relevant factors of a given regularity based on a sparse model. We focus on the important specific setting of linear ordinal regression, i.e.\ data have to be ranked into one of a finite number of ordered categories by a linear projection. Unlike previous work, we consider the case that features are potentially redundant, such that no unique minimum set of relevant features exists. We aim for an identification of all strongly and all weakly relevant features as well as their type of relevance (strong or weak); we achieve this goal by determining feature relevance bounds, which correspond to the minimum and maximum feature relevance, respectively, if searched over all equivalent models. In addition, we discuss how this setting enables us to substitute some of the features, e.g.\ due to their semantics, and how to extend the framework of feature relevance intervals to the setting of privileged information, i.e.\ potentially relevant information is available for training purposes only, but cannot be used for the prediction itself.
Dynamical Systems as Temporal Feature Spaces
Jul 15, 2019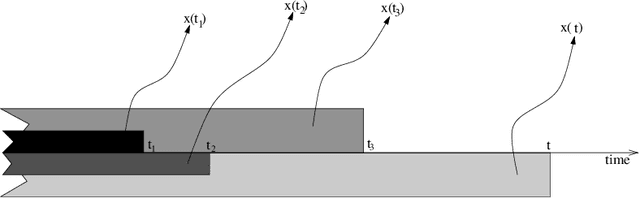
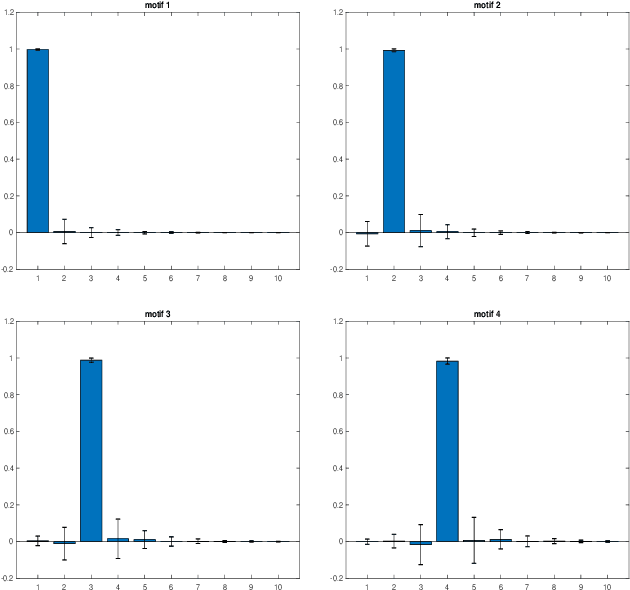

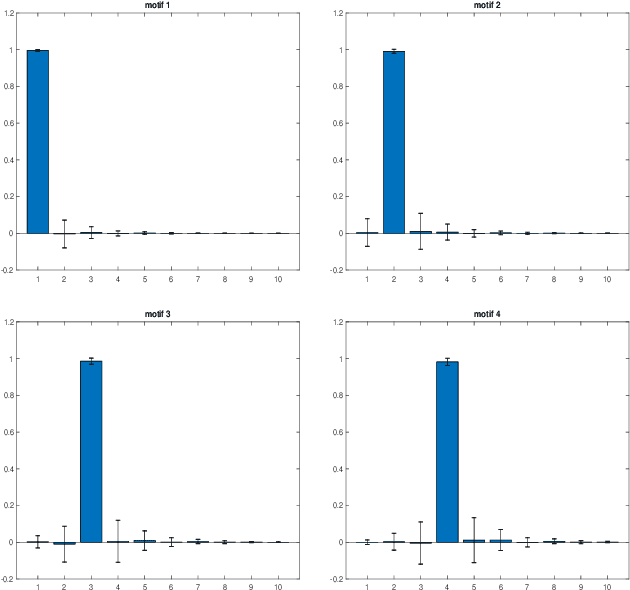
Parameterized state space models in the form of recurrent networks are often used in machine learning to learn from data streams exhibiting temporal dependencies. To break the black box nature of such models it is important to understand the dynamical features of the input driving time series that are formed in the state space. We propose a framework for rigorous analysis of such state representations in vanishing memory state space models such as echo state networks (ESN). In particular, we consider the state space a temporal feature space and the readout mapping from the state space a kernel machine operating in that feature space. We show that: (1) The usual ESN strategy of randomly generating input-to-state, as well as state coupling leads to shallow memory time series representations, corresponding to cross-correlation operator with fast exponentially decaying coefficients; (2) Imposing symmetry on dynamic coupling yields a constrained dynamic kernel matching the input time series with straightforward exponentially decaying motifs or exponentially decaying motifs of the highest frequency; (3) Simple cycle high-dimensional reservoir topology specified only through two free parameters can implement deep memory dynamic kernels with a rich variety of matching motifs. We quantify richness of feature representations imposed by dynamic kernels and demonstrate that for dynamic kernel associated with cycle reservoir topology, the kernel richness undergoes a phase transition close to the edge of stability.
Exploiting Synthetically Generated Data with Semi-Supervised Learning for Small and Imbalanced Datasets
Mar 24, 2019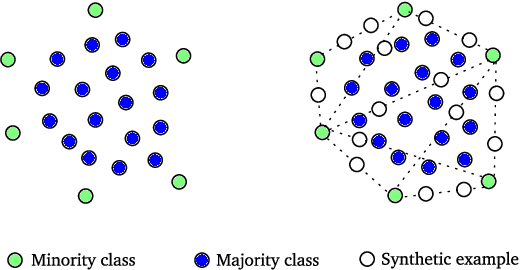
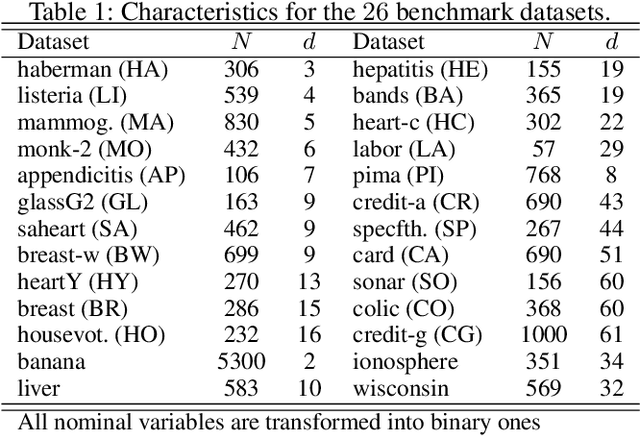
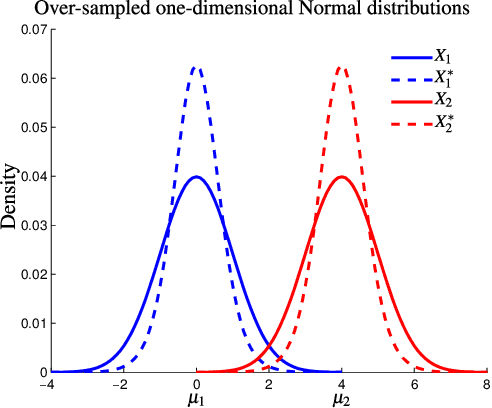

Data augmentation is rapidly gaining attention in machine learning. Synthetic data can be generated by simple transformations or through the data distribution. In the latter case, the main challenge is to estimate the label associated to new synthetic patterns. This paper studies the effect of generating synthetic data by convex combination of patterns and the use of these as unsupervised information in a semi-supervised learning framework with support vector machines, avoiding thus the need to label synthetic examples. We perform experiments on a total of 53 binary classification datasets. Our results show that this type of data over-sampling supports the well-known cluster assumption in semi-supervised learning, showing outstanding results for small high-dimensional datasets and imbalanced learning problems.
A mixture of experts model for predicting persistent weather patterns
Mar 24, 2019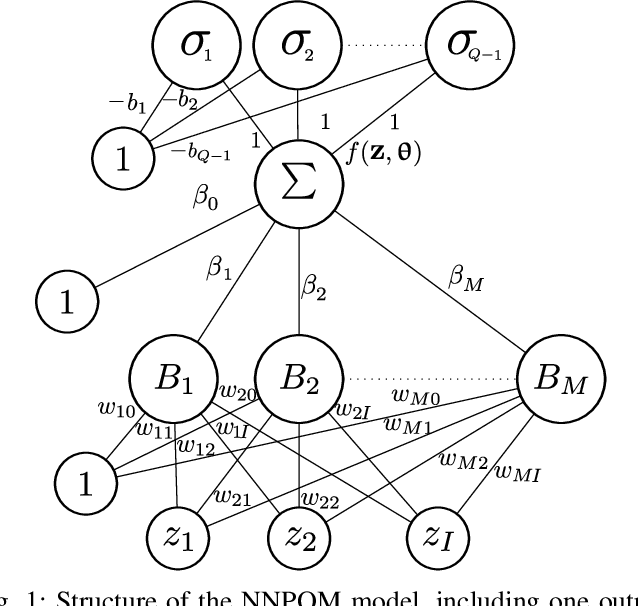
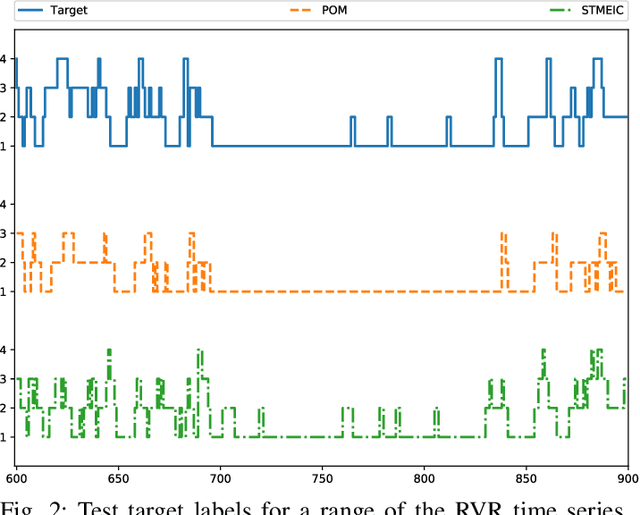
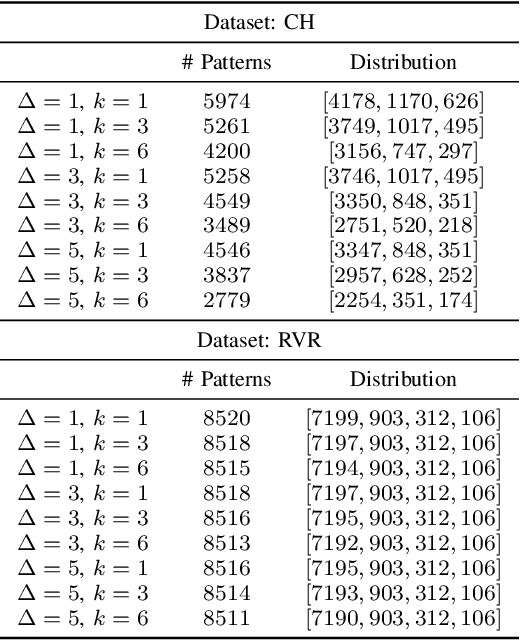
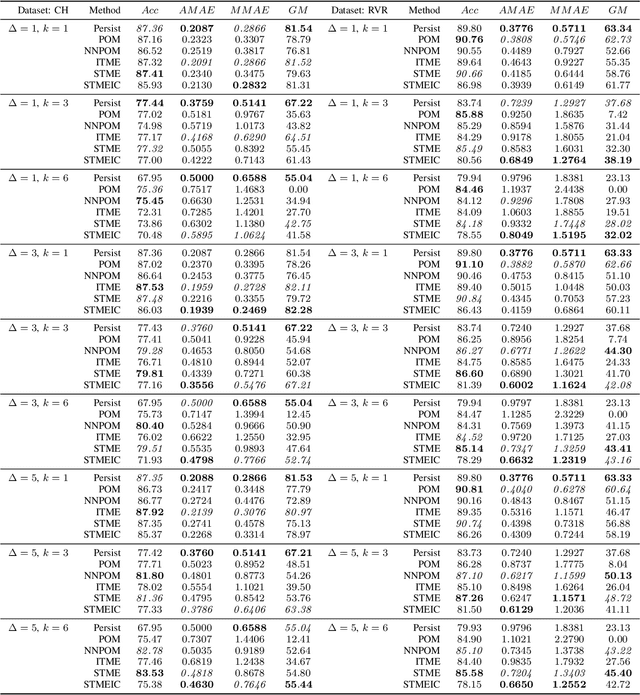
Weather and atmospheric patterns are often persistent. The simplest weather forecasting method is the so-called persistence model, which assumes that the future state of a system will be similar (or equal) to the present state. Machine learning (ML) models are widely used in different weather forecasting applications, but they need to be compared to the persistence model to analyse whether they provide a competitive solution to the problem at hand. In this paper, we devise a new model for predicting low-visibility in airports using the concepts of mixture of experts. Visibility level is coded as two different ordered categorical variables: cloud height and runway visual height. The underlying system in this application is stagnant approximately in 90% of the cases, and standard ML models fail to improve on the performance of the persistence model. Because of this, instead of trying to simply beat the persistence model using ML, we use this persistence as a baseline and learn an ordinal neural network model that refines its results by focusing on learning weather fluctuations. The results show that the proposal outperforms persistence and other ordinal autoregressive models, especially for longer time horizon predictions and for the runway visual height variable.
Feature Relevance Bounds for Ordinal Regression
Feb 20, 2019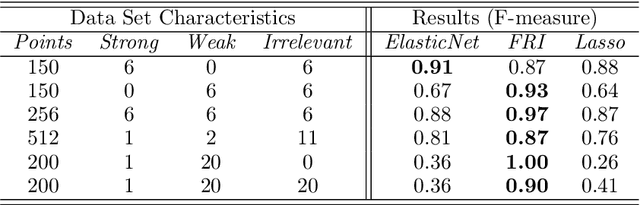
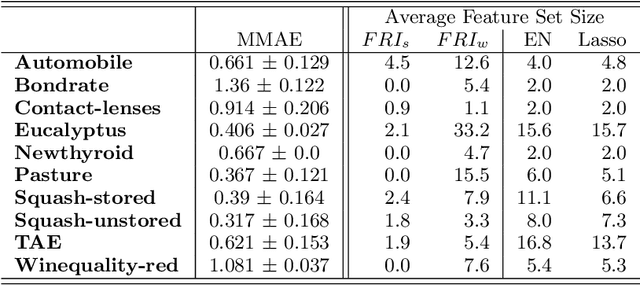
The increasing occurrence of ordinal data, mainly sociodemographic, led to a renewed research interest in ordinal regression, i.e. the prediction of ordered classes. Besides model accuracy, the interpretation of these models itself is of high relevance, and existing approaches therefore enforce e.g. model sparsity. For high dimensional or highly correlated data, however, this might be misleading due to strong variable dependencies. In this contribution, we aim for an identification of feature relevance bounds which - besides identifying all relevant features - explicitly differentiates between strongly and weakly relevant features.