 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeter Wonka
LASPA: Latent Spatial Alignment for Fast Training-free Single Image Editing
Mar 19, 2024
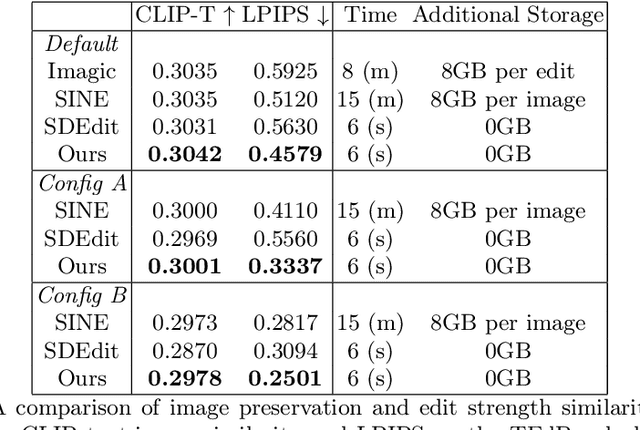
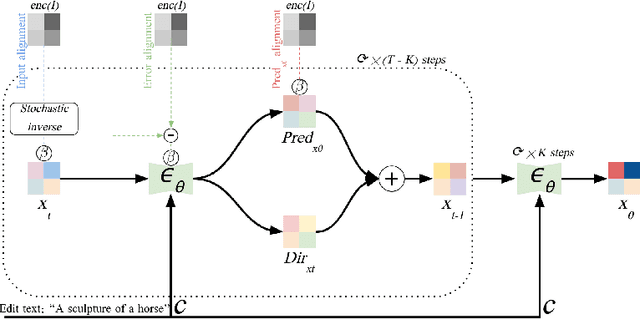
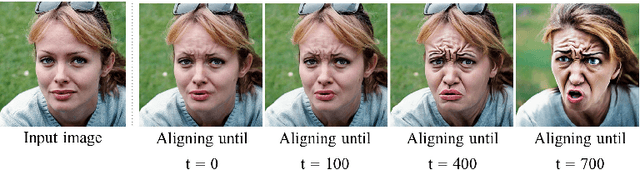

We present a novel, training-free approach for textual editing of real images using diffusion models. Unlike prior methods that rely on computationally expensive finetuning, our approach leverages LAtent SPatial Alignment (LASPA) to efficiently preserve image details. We demonstrate how the diffusion process is amenable to spatial guidance using a reference image, leading to semantically coherent edits. This eliminates the need for complex optimization and costly model finetuning, resulting in significantly faster editing compared to previous methods. Additionally, our method avoids the storage requirements associated with large finetuned models. These advantages make our approach particularly well-suited for editing on mobile devices and applications demanding rapid response times. While simple and fast, our method achieves 62-71\% preference in a user-study and significantly better model-based editing strength and image preservation scores.
AvatarMMC: 3D Head Avatar Generation and Editing with Multi-Modal Conditioning
Feb 08, 2024We introduce an approach for 3D head avatar generation and editing with multi-modal conditioning based on a 3D Generative Adversarial Network (GAN) and a Latent Diffusion Model (LDM). 3D GANs can generate high-quality head avatars given a single or no condition. However, it is challenging to generate samples that adhere to multiple conditions of different modalities. On the other hand, LDMs excel at learning complex conditional distributions. To this end, we propose to exploit the conditioning capabilities of LDMs to enable multi-modal control over the latent space of a pre-trained 3D GAN. Our method can generate and edit 3D head avatars given a mixture of control signals such as RGB input, segmentation masks, and global attributes. This provides better control over the generation and editing of synthetic avatars both globally and locally. Experiments show that our proposed approach outperforms a solely GAN-based approach both qualitatively and quantitatively on generation and editing tasks. To the best of our knowledge, our approach is the first to introduce multi-modal conditioning to 3D avatar generation and editing. \\href{avatarmmc-sig24.github.io}{Project Page}
Deep Learning-based Image and Video Inpainting: A Survey
Jan 07, 2024Image and video inpainting is a classic problem in computer vision and computer graphics, aiming to fill in the plausible and realistic content in the missing areas of images and videos. With the advance of deep learning, this problem has achieved significant progress recently. The goal of this paper is to comprehensively review the deep learning-based methods for image and video inpainting. Specifically, we sort existing methods into different categories from the perspective of their high-level inpainting pipeline, present different deep learning architectures, including CNN, VAE, GAN, diffusion models, etc., and summarize techniques for module design. We review the training objectives and the common benchmark datasets. We present evaluation metrics for low-level pixel and high-level perceptional similarity, conduct a performance evaluation, and discuss the strengths and weaknesses of representative inpainting methods. We also discuss related real-world applications. Finally, we discuss open challenges and suggest potential future research directions.
EVP: Enhanced Visual Perception using Inverse Multi-Attentive Feature Refinement and Regularized Image-Text Alignment
Dec 13, 2023This work presents the network architecture EVP (Enhanced Visual Perception). EVP builds on the previous work VPD which paved the way to use the Stable Diffusion network for computer vision tasks. We propose two major enhancements. First, we develop the Inverse Multi-Attentive Feature Refinement (IMAFR) module which enhances feature learning capabilities by aggregating spatial information from higher pyramid levels. Second, we propose a novel image-text alignment module for improved feature extraction of the Stable Diffusion backbone. The resulting architecture is suitable for a wide variety of tasks and we demonstrate its performance in the context of single-image depth estimation with a specialized decoder using classification-based bins and referring segmentation with an off-the-shelf decoder. Comprehensive experiments conducted on established datasets show that EVP achieves state-of-the-art results in single-image depth estimation for indoor (NYU Depth v2, 11.8% RMSE improvement over VPD) and outdoor (KITTI) environments, as well as referring segmentation (RefCOCO, 2.53 IoU improvement over ReLA). The code and pre-trained models are publicly available at https://github.com/Lavreniuk/EVP.
Text2AC-Zero: Consistent Synthesis of Animated Characters using 2D Diffusion
Dec 12, 2023We propose a zero-shot approach for consistent Text-to-Animated-Characters synthesis based on pre-trained Text-to-Image (T2I) diffusion models. Existing Text-to-Video (T2V) methods are expensive to train and require large-scale video datasets to produce diverse characters and motions. At the same time, their zero-shot alternatives fail to produce temporally consistent videos. We strive to bridge this gap, and we introduce a zero-shot approach that produces temporally consistent videos of animated characters and requires no training or fine-tuning. We leverage existing text-based motion diffusion models to generate diverse motions that we utilize to guide a T2I model. To achieve temporal consistency, we introduce the Spatial Latent Alignment module that exploits cross-frame dense correspondences that we compute to align the latents of the video frames. Furthermore, we propose Pixel-Wise Guidance to steer the diffusion process in a direction that minimizes visual discrepancies. Our proposed approach generates temporally consistent videos with diverse motions and styles, outperforming existing zero-shot T2V approaches in terms of pixel-wise consistency and user preference.
VoxelKP: A Voxel-based Network Architecture for Human Keypoint Estimation in LiDAR Data
Dec 11, 2023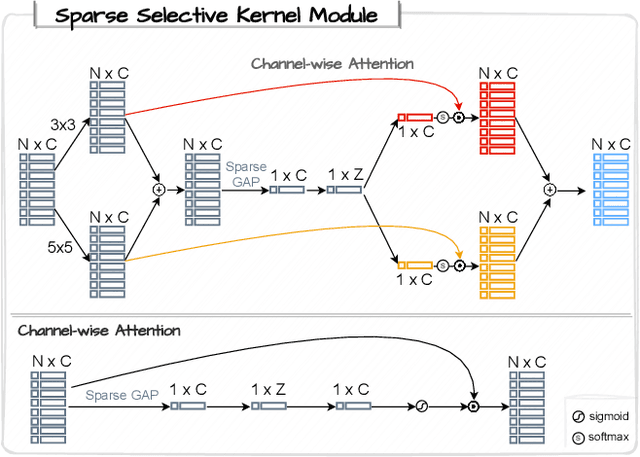
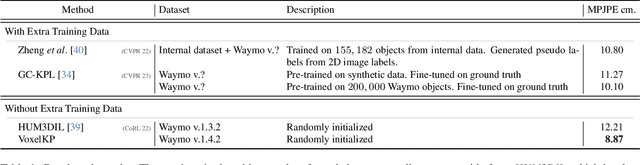
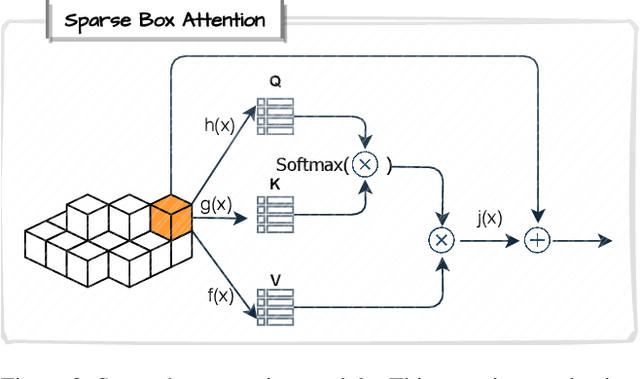
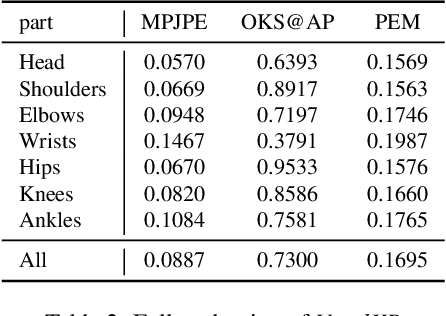
We present \textit{VoxelKP}, a novel fully sparse network architecture tailored for human keypoint estimation in LiDAR data. The key challenge is that objects are distributed sparsely in 3D space, while human keypoint detection requires detailed local information wherever humans are present. We propose four novel ideas in this paper. First, we propose sparse selective kernels to capture multi-scale context. Second, we introduce sparse box-attention to focus on learning spatial correlations between keypoints within each human instance. Third, we incorporate a spatial encoding to leverage absolute 3D coordinates when projecting 3D voxels to a 2D grid encoding a bird's eye view. Finally, we propose hybrid feature learning to combine the processing of per-voxel features with sparse convolution. We evaluate our method on the Waymo dataset and achieve an improvement of $27\%$ on the MPJPE metric compared to the state-of-the-art, \textit{HUM3DIL}, trained on the same data, and $12\%$ against the state-of-the-art, \textit{GC-KPL}, pretrained on a $25\times$ larger dataset. To the best of our knowledge, \textit{VoxelKP} is the first single-staged, fully sparse network that is specifically designed for addressing the challenging task of 3D keypoint estimation from LiDAR data, achieving state-of-the-art performances. Our code is available at \url{https://github.com/shijianjian/VoxelKP}.
NeuSD: Surface Completion with Multi-View Text-to-Image Diffusion
Dec 07, 2023We present a novel method for 3D surface reconstruction from multiple images where only a part of the object of interest is captured. Our approach builds on two recent developments: surface reconstruction using neural radiance fields for the reconstruction of the visible parts of the surface, and guidance of pre-trained 2D diffusion models in the form of Score Distillation Sampling (SDS) to complete the shape in unobserved regions in a plausible manner. We introduce three components. First, we suggest employing normal maps as a pure geometric representation for SDS instead of color renderings which are entangled with the appearance information. Second, we introduce the freezing of the SDS noise during training which results in more coherent gradients and better convergence. Third, we propose Multi-View SDS as a way to condition the generation of the non-observable part of the surface without fine-tuning or making changes to the underlying 2D Stable Diffusion model. We evaluate our approach on the BlendedMVS dataset demonstrating significant qualitative and quantitative improvements over competing methods.
LooseControl: Lifting ControlNet for Generalized Depth Conditioning
Dec 05, 2023We present LooseControl to allow generalized depth conditioning for diffusion-based image generation. ControlNet, the SOTA for depth-conditioned image generation, produces remarkable results but relies on having access to detailed depth maps for guidance. Creating such exact depth maps, in many scenarios, is challenging. This paper introduces a generalized version of depth conditioning that enables many new content-creation workflows. Specifically, we allow (C1) scene boundary control for loosely specifying scenes with only boundary conditions, and (C2) 3D box control for specifying layout locations of the target objects rather than the exact shape and appearance of the objects. Using LooseControl, along with text guidance, users can create complex environments (e.g., rooms, street views, etc.) by specifying only scene boundaries and locations of primary objects. Further, we provide two editing mechanisms to refine the results: (E1) 3D box editing enables the user to refine images by changing, adding, or removing boxes while freezing the style of the image. This yields minimal changes apart from changes induced by the edited boxes. (E2) Attribute editing proposes possible editing directions to change one particular aspect of the scene, such as the overall object density or a particular object. Extensive tests and comparisons with baselines demonstrate the generality of our method. We believe that LooseControl can become an important design tool for easily creating complex environments and be extended to other forms of guidance channels. Code and more information are available at https://shariqfarooq123.github.io/loose-control/ .
PatchFusion: An End-to-End Tile-Based Framework for High-Resolution Monocular Metric Depth Estimation
Dec 04, 2023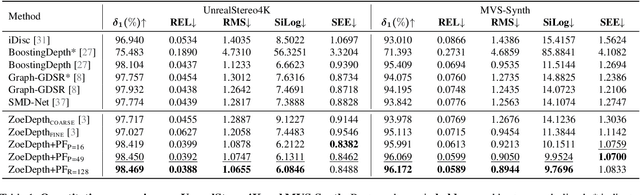
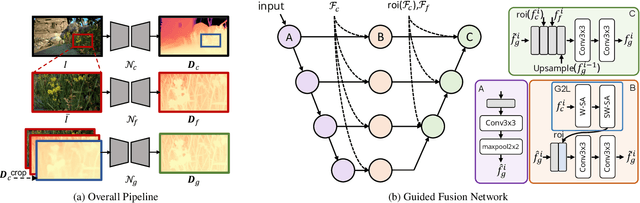
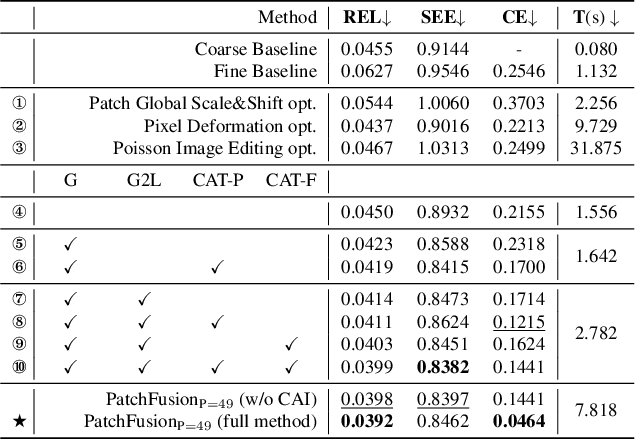
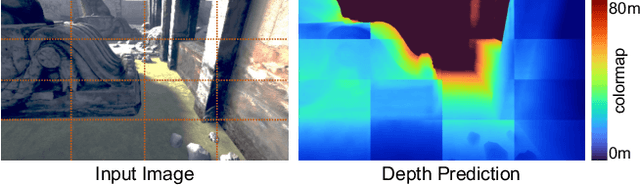
Single image depth estimation is a foundational task in computer vision and generative modeling. However, prevailing depth estimation models grapple with accommodating the increasing resolutions commonplace in today's consumer cameras and devices. Existing high-resolution strategies show promise, but they often face limitations, ranging from error propagation to the loss of high-frequency details. We present PatchFusion, a novel tile-based framework with three key components to improve the current state of the art: (1) A patch-wise fusion network that fuses a globally-consistent coarse prediction with finer, inconsistent tiled predictions via high-level feature guidance, (2) A Global-to-Local (G2L) module that adds vital context to the fusion network, discarding the need for patch selection heuristics, and (3) A Consistency-Aware Training (CAT) and Inference (CAI) approach, emphasizing patch overlap consistency and thereby eradicating the necessity for post-processing. Experiments on UnrealStereo4K, MVS-Synth, and Middleburry 2014 demonstrate that our framework can generate high-resolution depth maps with intricate details. PatchFusion is independent of the base model for depth estimation. Notably, our framework built on top of SOTA ZoeDepth brings improvements for a total of 17.3% and 29.4% in terms of the root mean squared error (RMSE) on UnrealStereo4K and MVS-Synth, respectively.
Back to 3D: Few-Shot 3D Keypoint Detection with Back-Projected 2D Features
Nov 29, 2023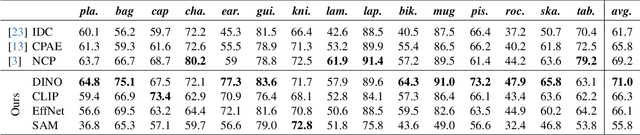
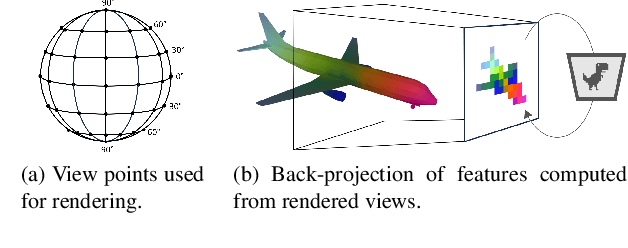
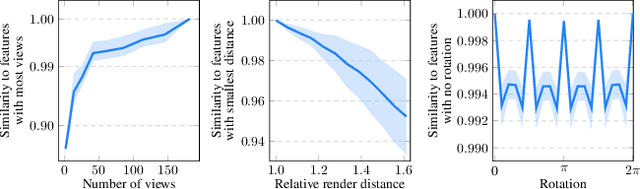

With the immense growth of dataset sizes and computing resources in recent years, so-called foundation models have become popular in NLP and vision tasks. In this work, we propose to explore foundation models for the task of keypoint detection on 3D shapes. A unique characteristic of keypoint detection is that it requires semantic and geometric awareness while demanding high localization accuracy. To address this problem, we propose, first, to back-project features from large pre-trained 2D vision models onto 3D shapes and employ them for this task. We show that we obtain robust 3D features that contain rich semantic information and analyze multiple candidate features stemming from different 2D foundation models. Second, we employ a keypoint candidate optimization module which aims to match the average observed distribution of keypoints on the shape and is guided by the back-projected features. The resulting approach achieves a new state of the art for few-shot keypoint detection on the KeyPointNet dataset, almost doubling the performance of the previous best methods.