 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhilipp Koehn
Pointer-Generator Networks for Low-Resource Machine Translation: Don't Copy That!
Mar 25, 2024


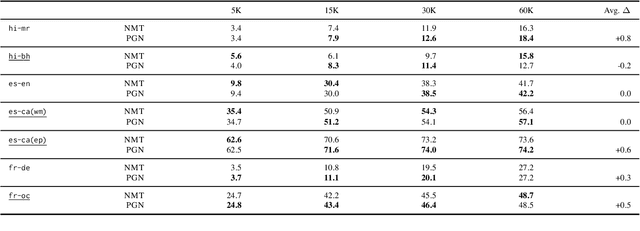
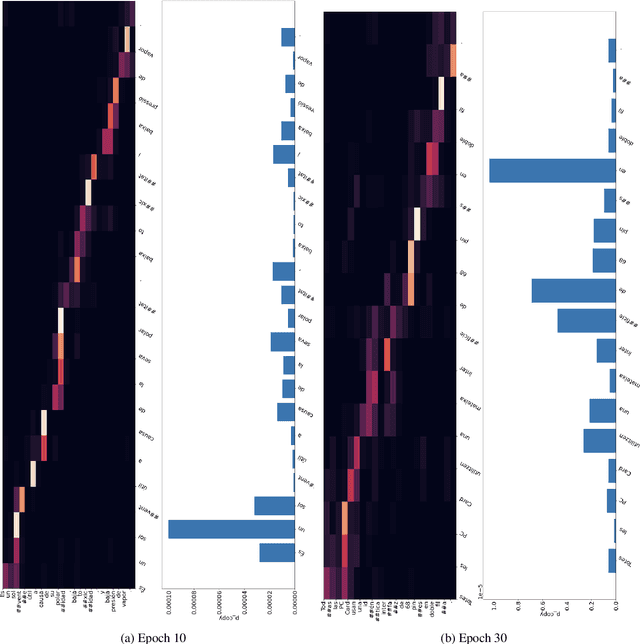
While Transformer-based neural machine translation (NMT) is very effective in high-resource settings, many languages lack the necessary large parallel corpora to benefit from it. In the context of low-resource (LR) MT between two closely-related languages, a natural intuition is to seek benefits from structural "shortcuts", such as copying subwords from the source to the target, given that such language pairs often share a considerable number of identical words, cognates, and borrowings. We test Pointer-Generator Networks for this purpose for six language pairs over a variety of resource ranges, and find weak improvements for most settings. However, analysis shows that the model does not show greater improvements for closely-related vs. more distant language pairs, or for lower resource ranges, and that the models do not exhibit the expected usage of the mechanism for shared subwords. Our discussion of the reasons for this behaviour highlights several general challenges for LR NMT, such as modern tokenization strategies, noisy real-world conditions, and linguistic complexities. We call for better scrutiny of linguistically motivated improvements to NMT given the blackbox nature of Transformer models, as well as for a focus on the above problems in the field.
Streaming Sequence Transduction through Dynamic Compression
Feb 02, 2024We introduce STAR (Stream Transduction with Anchor Representations), a novel Transformer-based model designed for efficient sequence-to-sequence transduction over streams. STAR dynamically segments input streams to create compressed anchor representations, achieving nearly lossless compression (12x) in Automatic Speech Recognition (ASR) and outperforming existing methods. Moreover, STAR demonstrates superior segmentation and latency-quality trade-offs in simultaneous speech-to-text tasks, optimizing latency, memory footprint, and quality.
The Language Barrier: Dissecting Safety Challenges of LLMs in Multilingual Contexts
Jan 23, 2024As the influence of large language models (LLMs) spans across global communities, their safety challenges in multilingual settings become paramount for alignment research. This paper examines the variations in safety challenges faced by LLMs across different languages and discusses approaches to alleviating such concerns. By comparing how state-of-the-art LLMs respond to the same set of malicious prompts written in higher- vs. lower-resource languages, we observe that (1) LLMs tend to generate unsafe responses much more often when a malicious prompt is written in a lower-resource language, and (2) LLMs tend to generate more irrelevant responses to malicious prompts in lower-resource languages. To understand where the discrepancy can be attributed, we study the effect of instruction tuning with reinforcement learning from human feedback (RLHF) or supervised finetuning (SFT) on the HH-RLHF dataset. Surprisingly, while training with high-resource languages improves model alignment, training in lower-resource languages yields minimal improvement. This suggests that the bottleneck of cross-lingual alignment is rooted in the pretraining stage. Our findings highlight the challenges in cross-lingual LLM safety, and we hope they inform future research in this direction.
Findings of the WMT 2023 Shared Task on Discourse-Level Literary Translation: A Fresh Orb in the Cosmos of LLMs
Nov 06, 2023Translating literary works has perennially stood as an elusive dream in machine translation (MT), a journey steeped in intricate challenges. To foster progress in this domain, we hold a new shared task at WMT 2023, the first edition of the Discourse-Level Literary Translation. First, we (Tencent AI Lab and China Literature Ltd.) release a copyrighted and document-level Chinese-English web novel corpus. Furthermore, we put forth an industry-endorsed criteria to guide human evaluation process. This year, we totally received 14 submissions from 7 academia and industry teams. We employ both automatic and human evaluations to measure the performance of the submitted systems. The official ranking of the systems is based on the overall human judgments. In addition, our extensive analysis reveals a series of interesting findings on literary and discourse-aware MT. We release data, system outputs, and leaderboard at http://www2.statmt.org/wmt23/literary-translation-task.html.
Narrowing the Gap between Zero- and Few-shot Machine Translation by Matching Styles
Nov 04, 2023Large language models trained primarily in a monolingual setting have demonstrated their ability to generalize to machine translation using zero- and few-shot examples with in-context learning. However, even though zero-shot translations are relatively good, there remains a discernible gap comparing their performance with the few-shot setting. In this paper, we investigate the factors contributing to this gap and find that this gap can largely be closed (for about 70%) by matching the writing styles of the target corpus. Additionally, we explore potential approaches to enhance zero-shot baselines without the need for parallel demonstration examples, providing valuable insights into how these methods contribute to improving translation metrics.
Error Norm Truncation: Robust Training in the Presence of Data Noise for Text Generation Models
Oct 02, 2023
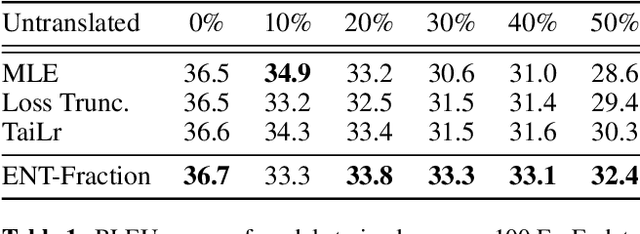

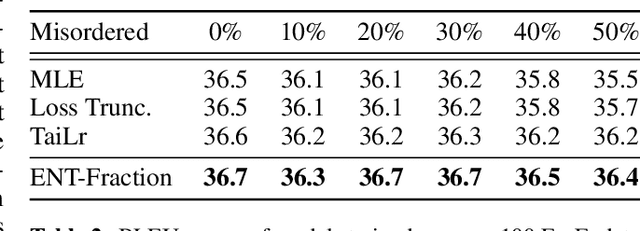
Text generation models are notoriously vulnerable to errors in the training data. With the wide-spread availability of massive amounts of web-crawled data becoming more commonplace, how can we enhance the robustness of models trained on a massive amount of noisy web-crawled text? In our work, we propose Error Norm Truncation (ENT), a robust enhancement method to the standard training objective that truncates noisy data. Compared to methods that only uses the negative log-likelihood loss to estimate data quality, our method provides a more accurate estimation by considering the distribution of non-target tokens, which is often overlooked by previous work. Through comprehensive experiments across language modeling, machine translation, and text summarization, we show that equipping text generation models with ENT improves generation quality over standard training and previous soft and hard truncation methods. Furthermore, we show that our method improves the robustness of models against two of the most detrimental types of noise in machine translation, resulting in an increase of more than 2 BLEU points over the MLE baseline when up to 50% of noise is added to the data.
Pixel Representations for Multilingual Translation and Data-efficient Cross-lingual Transfer
May 23, 2023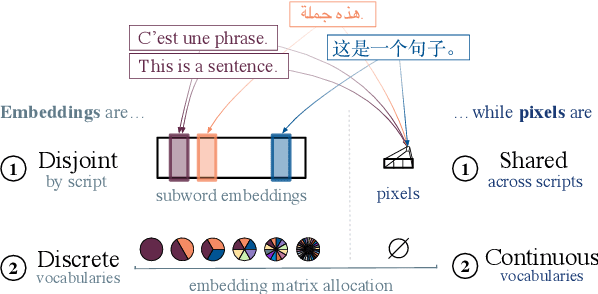

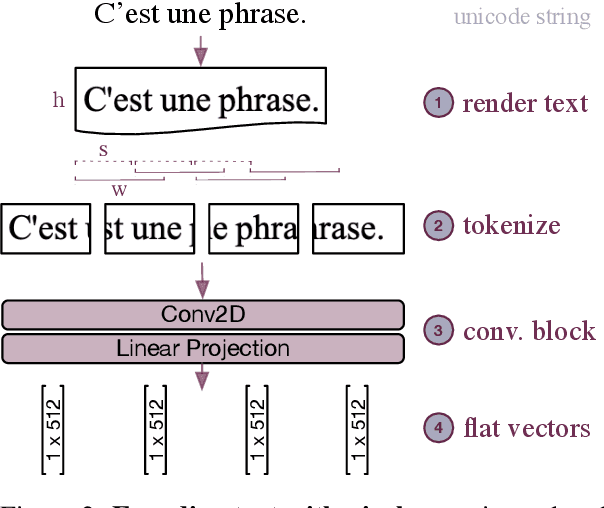
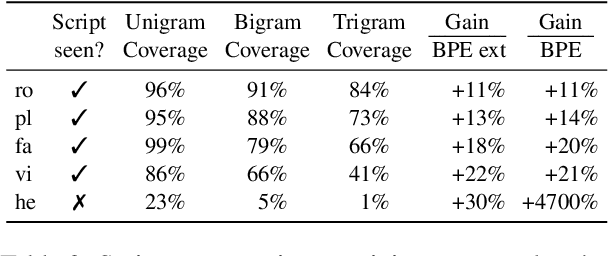
We introduce and demonstrate how to effectively train multilingual machine translation models with pixel representations. We experiment with two different data settings with a variety of language and script coverage, and show performance competitive with subword embeddings. We analyze various properties of pixel representations to better understand where they provide potential benefits and the impact of different scripts and data representations. We observe that these properties not only enable seamless cross-lingual transfer to unseen scripts, but make pixel representations more data-efficient than alternatives such as vocabulary expansion. We hope this work contributes to more extensible multilingual models for all languages and scripts.
Condensing Multilingual Knowledge with Lightweight Language-Specific Modules
May 23, 2023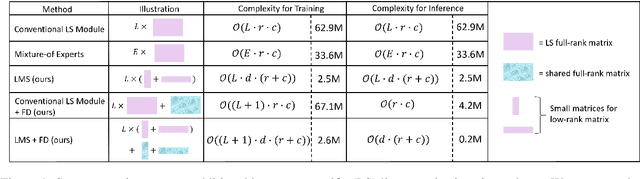

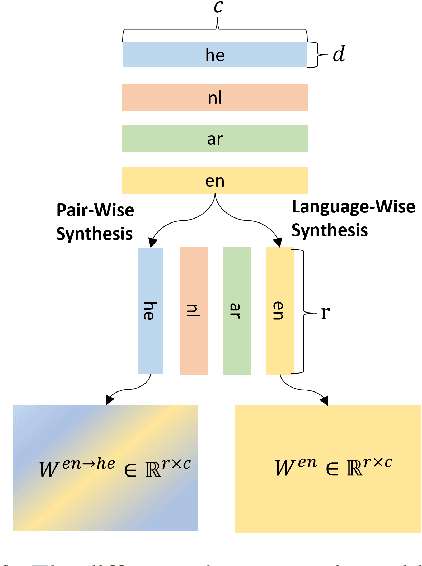
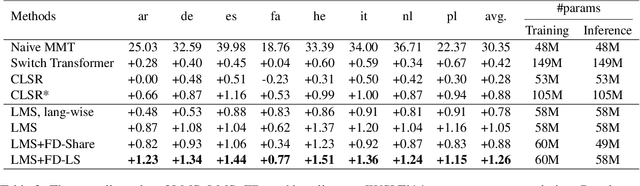
Incorporating language-specific (LS) modules is a proven method to boost performance in multilingual machine translation. This approach bears similarity to Mixture-of-Experts (MoE) because it does not inflate FLOPs. However, the scalability of this approach to hundreds of languages (experts) tends to be unmanageable due to the prohibitive number of parameters introduced by full-rank matrices in fully-connected layers. In this work, we introduce the Language-Specific Matrix Synthesis (LMS) method. This approach constructs LS modules by generating low-rank matrices from two significantly smaller matrices to approximate the full-rank matrix. Furthermore, we condense multilingual knowledge from multiple LS modules into a single shared module with the Fuse Distillation (FD) technique to improve the efficiency of inference and model serialization. We show that our LMS method significantly outperforms previous LS methods and MoE methods with the same amount of extra parameters, e.g., 1.73 BLEU points over the Switch Transformer on many-to-many multilingual machine translation. Importantly, LMS is able to have comparable translation performance with much fewer parameters.
Bilingual Lexicon Induction for Low-Resource Languages using Graph Matching via Optimal Transport
Oct 25, 2022
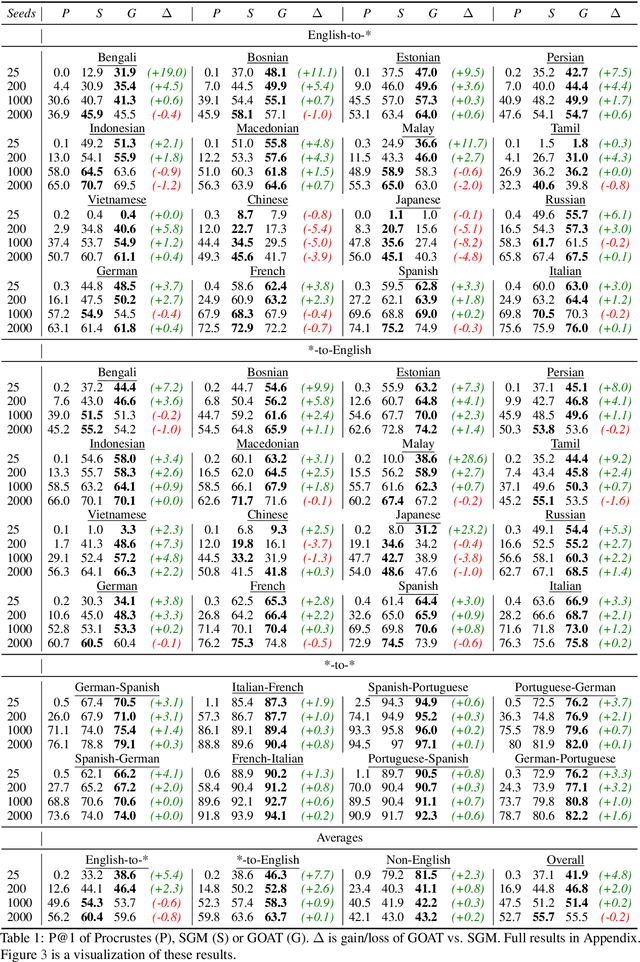

Bilingual lexicons form a critical component of various natural language processing applications, including unsupervised and semisupervised machine translation and crosslingual information retrieval. We improve bilingual lexicon induction performance across 40 language pairs with a graph-matching method based on optimal transport. The method is especially strong with low amounts of supervision.
IsoVec: Controlling the Relative Isomorphism of Word Embedding Spaces
Oct 11, 2022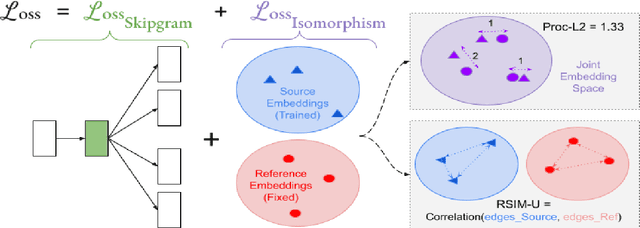
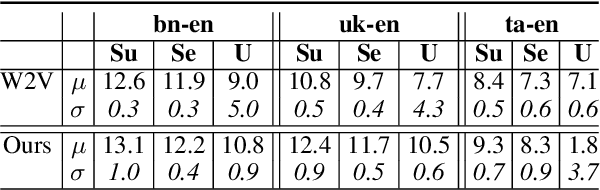
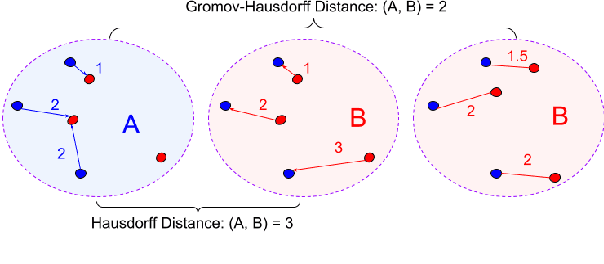

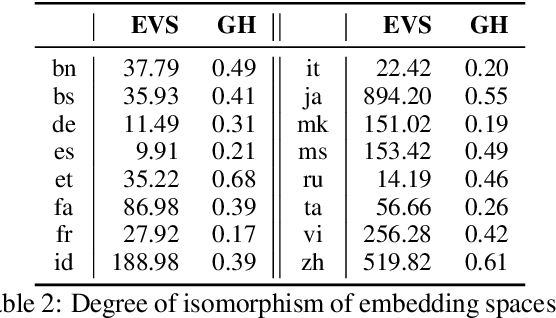
The ability to extract high-quality translation dictionaries from monolingual word embedding spaces depends critically on the geometric similarity of the spaces -- their degree of "isomorphism." We address the root-cause of faulty cross-lingual mapping: that word embedding training resulted in the underlying spaces being non-isomorphic. We incorporate global measures of isomorphism directly into the skipgram loss function, successfully increasing the relative isomorphism of trained word embedding spaces and improving their ability to be mapped to a shared cross-lingual space. The result is improved bilingual lexicon induction in general data conditions, under domain mismatch, and with training algorithm dissimilarities. We release IsoVec at https://github.com/kellymarchisio/isovec.