 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePietro Mazzaglia
Information-driven Affordance Discovery for Efficient Robotic Manipulation
May 06, 2024
Robotic affordances, providing information about what actions can be taken in a given situation, can aid robotic manipulation. However, learning about affordances requires expensive large annotated datasets of interactions or demonstrations. In this work, we argue that well-directed interactions with the environment can mitigate this problem and propose an information-based measure to augment the agent's objective and accelerate the affordance discovery process. We provide a theoretical justification of our approach and we empirically validate the approach both in simulation and real-world tasks. Our method, which we dub IDA, enables the efficient discovery of visual affordances for several action primitives, such as grasping, stacking objects, or opening drawers, strongly improving data efficiency in simulation, and it allows us to learn grasping affordances in a small number of interactions, on a real-world setup with a UFACTORY XArm 6 robot arm.
Learning to Navigate from Scratch using World Models and Curiosity: the Good, the Bad, and the Ugly
Aug 30, 2023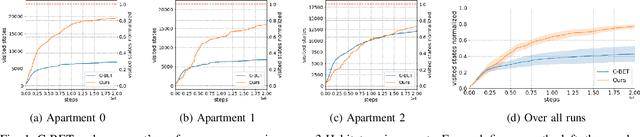
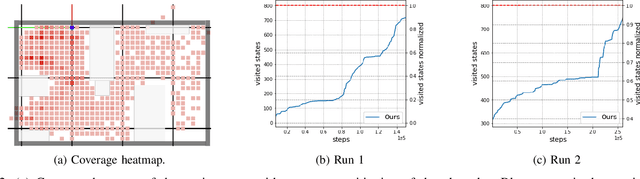
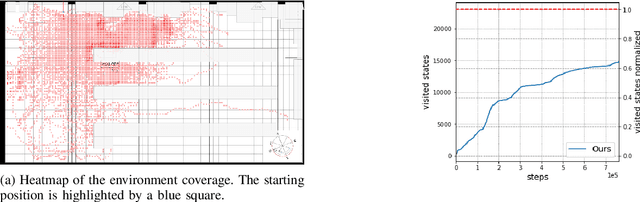

Learning to navigate unknown environments from scratch is a challenging problem. This work presents a system that integrates world models with curiosity-driven exploration for autonomous navigation in new environments. We evaluate performance through simulations and real-world experiments of varying scales and complexities. In simulated environments, the approach rapidly and comprehensively explores the surroundings. Real-world scenarios introduce additional challenges. Despite demonstrating promise in a small controlled environment, we acknowledge that larger and dynamic environments can pose challenges for the current system. Our analysis emphasizes the significance of developing adaptable and robust world models that can handle environmental changes to prevent repetitive exploration of the same areas.
Uncertainty-driven Affordance Discovery for Efficient Robotics Manipulation
Aug 28, 2023Robotics affordances, providing information about what actions can be taken in a given situation, can aid robotics manipulation. However, learning about affordances requires expensive large annotated datasets of interactions or demonstrations. In this work, we show active learning can mitigate this problem and propose the use of uncertainty to drive an interactive affordance discovery process. We show that our method enables the efficient discovery of visual affordances for several action primitives, such as grasping, stacking objects, or opening drawers, strongly improving data efficiency and allowing us to learn grasping affordances on a real-world setup with an xArm 6 robot arm in a small number of trials.
FOCUS: Object-Centric World Models for Robotics Manipulation
Jul 07, 2023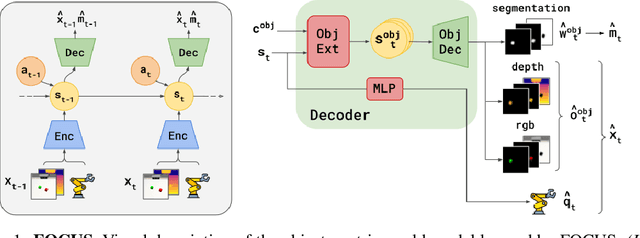
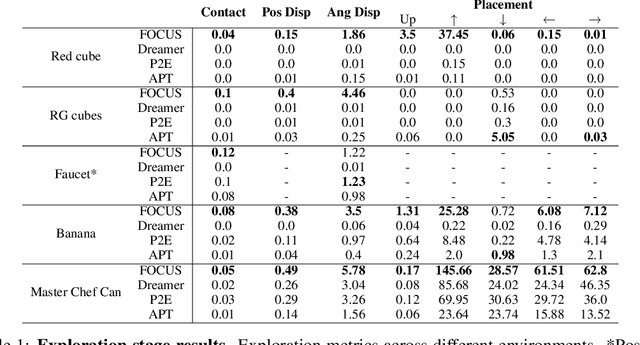
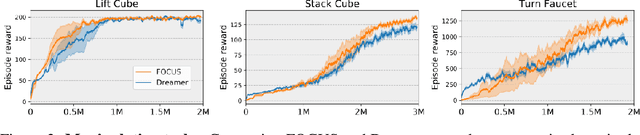

Understanding the world in terms of objects and the possible interplays with them is an important cognition ability, especially in robotics manipulation, where many tasks require robot-object interactions. However, learning such a structured world model, which specifically captures entities and relationships, remains a challenging and underexplored problem. To address this, we propose FOCUS, a model-based agent that learns an object-centric world model. Thanks to a novel exploration bonus that stems from the object-centric representation, FOCUS can be deployed on robotics manipulation tasks to explore object interactions more easily. Evaluating our approach on manipulation tasks across different settings, we show that object-centric world models allow the agent to solve tasks more efficiently and enable consistent exploration of robot-object interactions. Using a Franka Emika robot arm, we also showcase how FOCUS could be adopted in real-world settings.
Maximum Causal Entropy Inverse Constrained Reinforcement Learning
May 04, 2023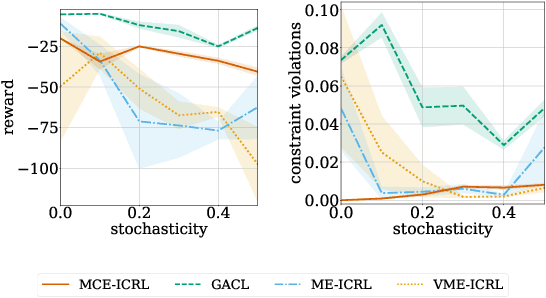
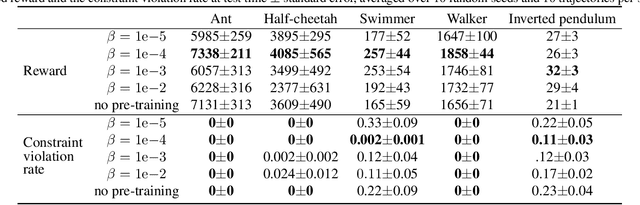
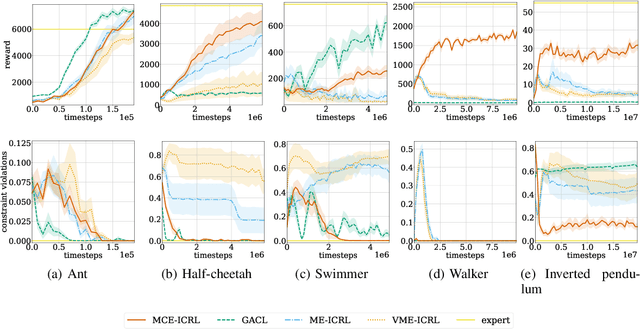
When deploying artificial agents in real-world environments where they interact with humans, it is crucial that their behavior is aligned with the values, social norms or other requirements of that environment. However, many environments have implicit constraints that are difficult to specify and transfer to a learning agent. To address this challenge, we propose a novel method that utilizes the principle of maximum causal entropy to learn constraints and an optimal policy that adheres to these constraints, using demonstrations of agents that abide by the constraints. We prove convergence in a tabular setting and provide an approximation which scales to complex environments. We evaluate the effectiveness of the learned policy by assessing the reward received and the number of constraint violations, and we evaluate the learned cost function based on its transferability to other agents. Our method has been shown to outperform state-of-the-art approaches across a variety of tasks and environments, and it is able to handle problems with stochastic dynamics and a continuous state-action space.
Object-Centric Scene Representations using Active Inference
Feb 07, 2023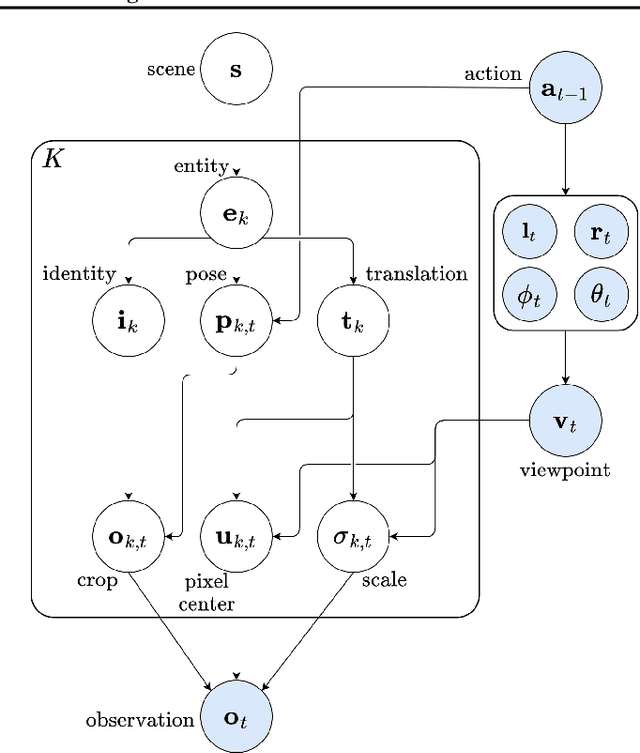
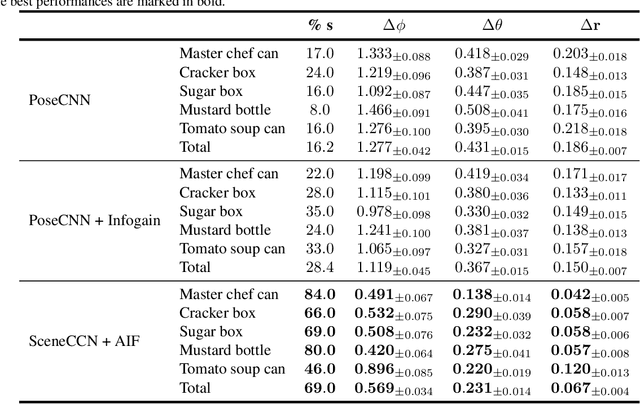
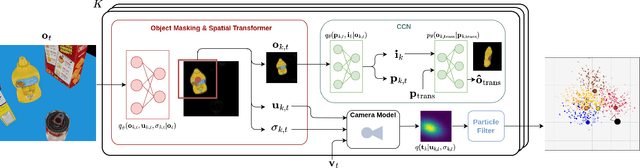
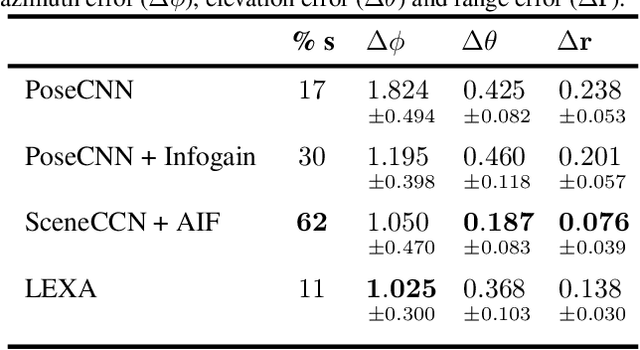
Representing a scene and its constituent objects from raw sensory data is a core ability for enabling robots to interact with their environment. In this paper, we propose a novel approach for scene understanding, leveraging a hierarchical object-centric generative model that enables an agent to infer object category and pose in an allocentric reference frame using active inference, a neuro-inspired framework for action and perception. For evaluating the behavior of an active vision agent, we also propose a new benchmark where, given a target viewpoint of a particular object, the agent needs to find the best matching viewpoint given a workspace with randomly positioned objects in 3D. We demonstrate that our active inference agent is able to balance epistemic foraging and goal-driven behavior, and outperforms both supervised and reinforcement learning baselines by a large margin.
Choreographer: Learning and Adapting Skills in Imagination
Nov 23, 2022

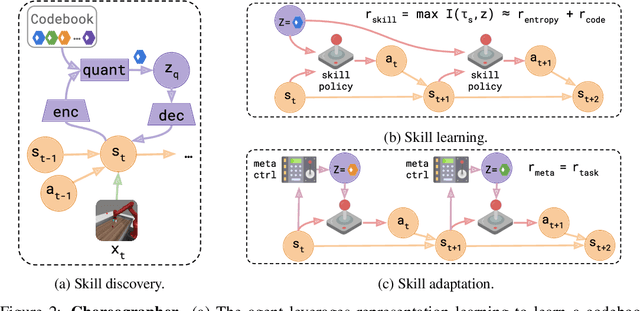
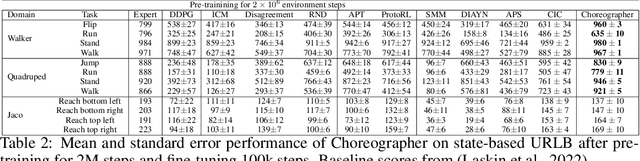
Unsupervised skill learning aims to learn a rich repertoire of behaviors without external supervision, providing artificial agents with the ability to control and influence the environment. However, without appropriate knowledge and exploration, skills may provide control only over a restricted area of the environment, limiting their applicability. Furthermore, it is unclear how to leverage the learned skill behaviors for adapting to downstream tasks in a data-efficient manner. We present Choreographer, a model-based agent that exploits its world model to learn and adapt skills in imagination. Our method decouples the exploration and skill learning processes, being able to discover skills in the latent state space of the model. During adaptation, the agent uses a meta-controller to evaluate and adapt the learned skills efficiently by deploying them in parallel in imagination. Choreographer is able to learn skills both from offline data, and by collecting data simultaneously with an exploration policy. The skills can be used to effectively adapt to downstream tasks, as we show in the URL benchmark, where we outperform previous approaches from both pixels and states inputs. The learned skills also explore the environment thoroughly, finding sparse rewards more frequently, as shown in goal-reaching tasks from the DMC Suite and Meta-World. Project website: https://skillchoreographer.github.io/
Unsupervised Model-based Pre-training for Data-efficient Control from Pixels
Sep 24, 2022
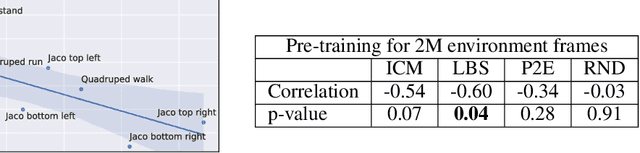
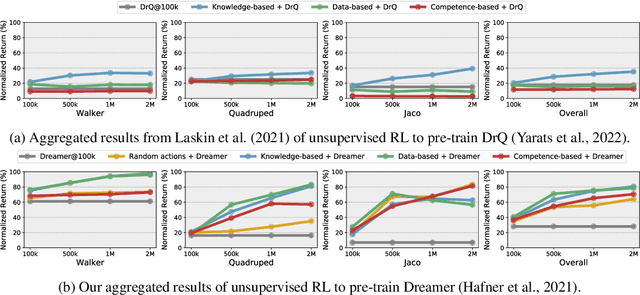
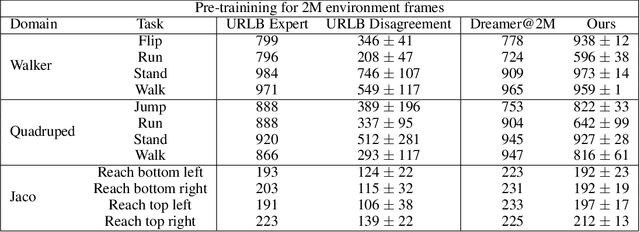
Controlling artificial agents from visual sensory data is an arduous task. Reinforcement learning (RL) algorithms can succeed in this but require large amounts of interactions between the agent and the environment. To alleviate the issue, unsupervised RL proposes to employ self-supervised interaction and learning, for adapting faster to future tasks. Yet, whether current unsupervised strategies improve generalization capabilities is still unclear, especially in visual control settings. In this work, we design an effective unsupervised RL strategy for data-efficient visual control. First, we show that world models pre-trained with data collected using unsupervised RL can facilitate adaptation for future tasks. Then, we analyze several design choices to adapt efficiently, effectively reusing the agents' pre-trained components, and learning and planning in imagination, with our hybrid planner, which we dub Dyna-MPC. By combining the findings of a large-scale empirical study, we establish an approach that strongly improves performance on the Unsupervised RL Benchmark, requiring 20$\times$ less data to match the performance of supervised methods. The approach also demonstrates robust performance on the Real-Word RL benchmark, hinting that the approach generalizes to noisy environments.
Disentangling Shape and Pose for Object-Centric Deep Active Inference Models
Sep 16, 2022



Active inference is a first principles approach for understanding the brain in particular, and sentient agents in general, with the single imperative of minimizing free energy. As such, it provides a computational account for modelling artificial intelligent agents, by defining the agent's generative model and inferring the model parameters, actions and hidden state beliefs. However, the exact specification of the generative model and the hidden state space structure is left to the experimenter, whose design choices influence the resulting behaviour of the agent. Recently, deep learning methods have been proposed to learn a hidden state space structure purely from data, alleviating the experimenter from this tedious design task, but resulting in an entangled, non-interpreteable state space. In this paper, we hypothesize that such a learnt, entangled state space does not necessarily yield the best model in terms of free energy, and that enforcing different factors in the state space can yield a lower model complexity. In particular, we consider the problem of 3D object representation, and focus on different instances of the ShapeNet dataset. We propose a model that factorizes object shape, pose and category, while still learning a representation for each factor using a deep neural network. We show that models, with best disentanglement properties, perform best when adopted by an active agent in reaching preferred observations.
Home Run: Finding Your Way Home by Imagining Trajectories
Aug 19, 2022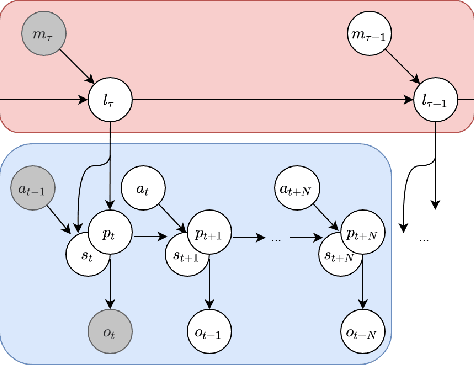



When studying unconstrained behaviour and allowing mice to leave their cage to navigate a complex labyrinth, the mice exhibit foraging behaviour in the labyrinth searching for rewards, returning to their home cage now and then, e.g. to drink. Surprisingly, when executing such a ``home run'', the mice do not follow the exact reverse path, in fact, the entry path and home path have very little overlap. Recent work proposed a hierarchical active inference model for navigation, where the low level model makes inferences about hidden states and poses that explain sensory inputs, whereas the high level model makes inferences about moving between locations, effectively building a map of the environment. However, using this ``map'' for planning, only allows the agent to find trajectories that it previously explored, far from the observed mice's behaviour. In this paper, we explore ways of incorporating before-unvisited paths in the planning algorithm, by using the low level generative model to imagine potential, yet undiscovered paths. We demonstrate a proof of concept in a grid-world environment, showing how an agent can accurately predict a new, shorter path in the map leading to its starting point, using a generative model learnt from pixel-based observations.