 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiotr Miłoś
tsGT: Stochastic Time Series Modeling With Transformer
Mar 15, 2024




Time series methods are of fundamental importance in virtually any field of science that deals with temporally structured data. Recently, there has been a surge of deterministic transformer models with time series-specific architectural biases. In this paper, we go in a different direction by introducing tsGT, a stochastic time series model built on a general-purpose transformer architecture. We focus on using a well-known and theoretically justified rolling window backtesting and evaluation protocol. We show that tsGT outperforms the state-of-the-art models on MAD and RMSE, and surpasses its stochastic peers on QL and CRPS, on four commonly used datasets. We complement these results with a detailed analysis of tsGT's ability to model the data distribution and predict marginal quantile values.
Overestimation, Overfitting, and Plasticity in Actor-Critic: the Bitter Lesson of Reinforcement Learning
Mar 01, 2024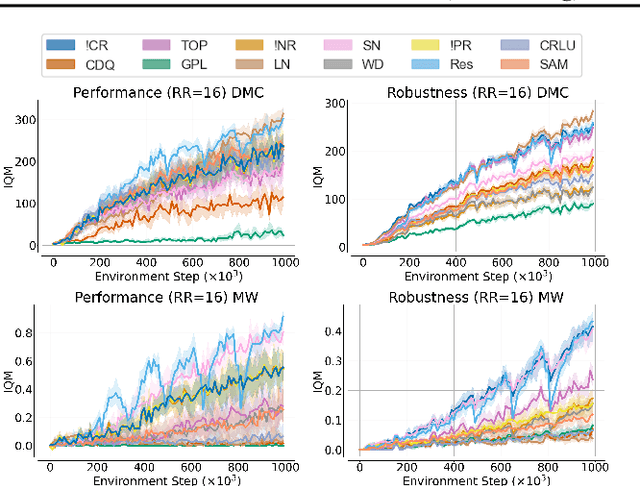
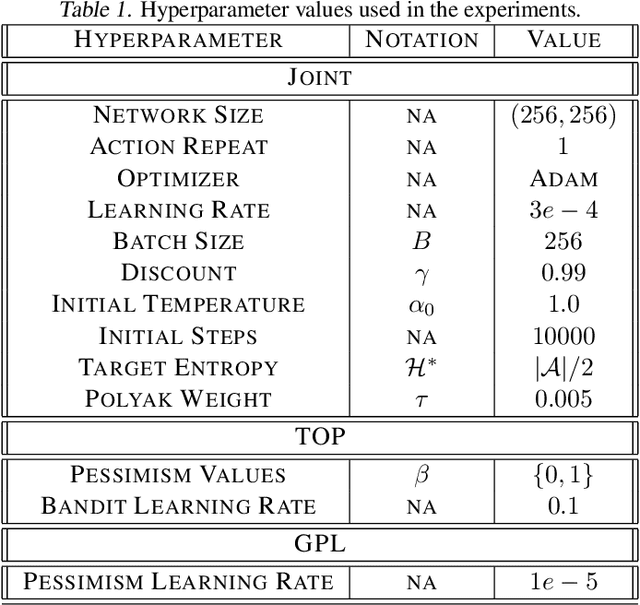

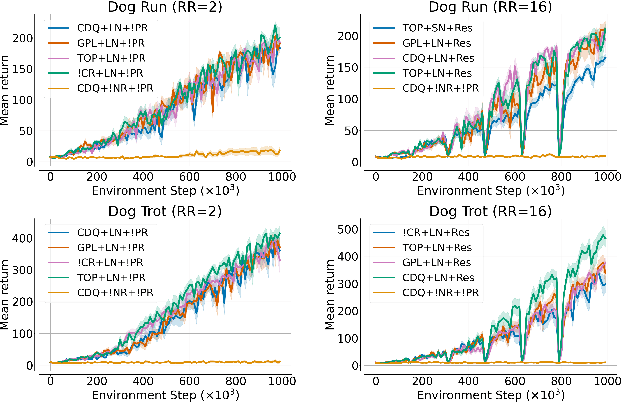
Recent advancements in off-policy Reinforcement Learning (RL) have significantly improved sample efficiency, primarily due to the incorporation of various forms of regularization that enable more gradient update steps than traditional agents. However, many of these techniques have been tested in limited settings, often on tasks from single simulation benchmarks and against well-known algorithms rather than a range of regularization approaches. This limits our understanding of the specific mechanisms driving RL improvements. To address this, we implemented over 60 different off-policy agents, each integrating established regularization techniques from recent state-of-the-art algorithms. We tested these agents across 14 diverse tasks from 2 simulation benchmarks. Our findings reveal that while the effectiveness of a specific regularization setup varies with the task, certain combinations consistently demonstrate robust and superior performance. Notably, a simple Soft Actor-Critic agent, appropriately regularized, reliably solves dog tasks, which were previously solved mainly through model-based approaches.
Analysing The Impact of Sequence Composition on Language Model Pre-Training
Feb 21, 2024Most language model pre-training frameworks concatenate multiple documents into fixed-length sequences and use causal masking to compute the likelihood of each token given its context; this strategy is widely adopted due to its simplicity and efficiency. However, to this day, the influence of the pre-training sequence composition strategy on the generalisation properties of the model remains under-explored. In this work, we find that applying causal masking can lead to the inclusion of distracting information from previous documents during pre-training, which negatively impacts the performance of the models on language modelling and downstream tasks. In intra-document causal masking, the likelihood of each token is only conditioned on the previous tokens in the same document, eliminating potential distracting information from previous documents and significantly improving performance. Furthermore, we find that concatenating related documents can reduce some potential distractions during pre-training, and our proposed efficient retrieval-based sequence construction method, BM25Chunk, can improve in-context learning (+11.6\%), knowledge memorisation (+9.8\%), and context utilisation (+7.2\%) abilities of language models without sacrificing efficiency.
Fine-tuning Reinforcement Learning Models is Secretly a Forgetting Mitigation Problem
Feb 05, 2024Fine-tuning is a widespread technique that allows practitioners to transfer pre-trained capabilities, as recently showcased by the successful applications of foundation models. However, fine-tuning reinforcement learning (RL) models remains a challenge. This work conceptualizes one specific cause of poor transfer, accentuated in the RL setting by the interplay between actions and observations: forgetting of pre-trained capabilities. Namely, a model deteriorates on the state subspace of the downstream task not visited in the initial phase of fine-tuning, on which the model behaved well due to pre-training. This way, we lose the anticipated transfer benefits. We identify conditions when this problem occurs, showing that it is common and, in many cases, catastrophic. Through a detailed empirical analysis of the challenging NetHack and Montezuma's Revenge environments, we show that standard knowledge retention techniques mitigate the problem and thus allow us to take full advantage of the pre-trained capabilities. In particular, in NetHack, we achieve a new state-of-the-art for neural models, improving the previous best score from $5$K to over $10$K points in the Human Monk scenario.
Structured Packing in LLM Training Improves Long Context Utilization
Jan 02, 2024Recent advances in long-context Large Language Models (LCLMs) have generated significant interest, especially in applications such as querying scientific research papers. However, their potential is often limited by inadequate context utilization. We identify the absence of long-range semantic dependencies in typical training data as a primary hindrance. To address this, we delve into the benefits of frequently incorporating related documents into training inputs. Using the inherent directory structure of code data as a source of training examples, we demonstrate improvements in perplexity, even for tasks unrelated to coding. Building on these findings, but with a broader focus, we introduce Structured Packing for Long Context (SPLiCe). SPLiCe is an innovative method for creating training examples by using a retrieval method to collate the most mutually relevant documents into a single training context. Our results indicate that \method{} enhances model performance and can be used to train large models to utilize long contexts better. We validate our results by training a large $3$B model, showing both perplexity improvements and better long-context performance on downstream tasks.
Focused Transformer: Contrastive Training for Context Scaling
Jul 06, 2023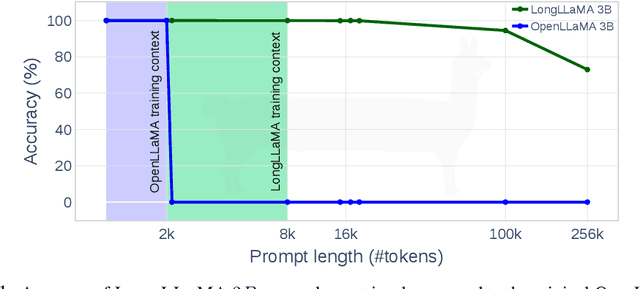
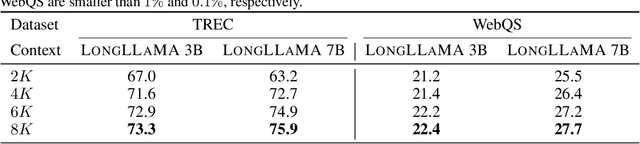
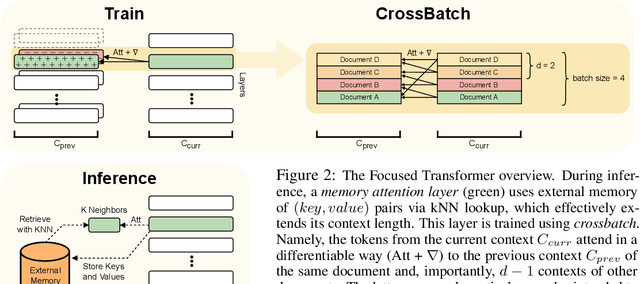
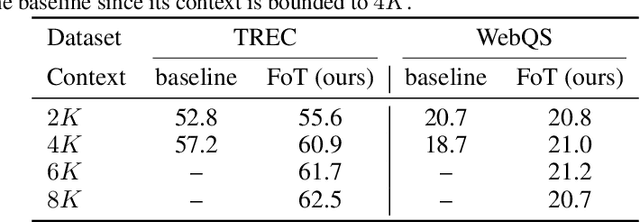
Large language models have an exceptional capability to incorporate new information in a contextual manner. However, the full potential of such an approach is often restrained due to a limitation in the effective context length. One solution to this issue is to endow an attention layer with access to an external memory, which comprises of (key, value) pairs. Yet, as the number of documents increases, the proportion of relevant keys to irrelevant ones decreases, leading the model to focus more on the irrelevant keys. We identify a significant challenge, dubbed the distraction issue, where keys linked to different semantic values might overlap, making them hard to distinguish. To tackle this problem, we introduce the Focused Transformer (FoT), a technique that employs a training process inspired by contrastive learning. This novel approach enhances the structure of the (key, value) space, enabling an extension of the context length. Our method allows for fine-tuning pre-existing, large-scale models to lengthen their effective context. This is demonstrated by our fine-tuning of $3B$ and $7B$ OpenLLaMA checkpoints. The resulting models, which we name LongLLaMA, exhibit advancements in tasks requiring a long context. We further illustrate that our LongLLaMA models adeptly manage a $256 k$ context length for passkey retrieval.
The Tunnel Effect: Building Data Representations in Deep Neural Networks
May 31, 2023



Deep neural networks are widely known for their remarkable effectiveness across various tasks, with the consensus that deeper networks implicitly learn more complex data representations. This paper shows that sufficiently deep networks trained for supervised image classification split into two distinct parts that contribute to the resulting data representations differently. The initial layers create linearly-separable representations, while the subsequent layers, which we refer to as \textit{the tunnel}, compress these representations and have a minimal impact on the overall performance. We explore the tunnel's behavior through comprehensive empirical studies, highlighting that it emerges early in the training process. Its depth depends on the relation between the network's capacity and task complexity. Furthermore, we show that the tunnel degrades out-of-distribution generalization and discuss its implications for continual learning.
Exploring Continual Learning of Diffusion Models
Mar 27, 2023
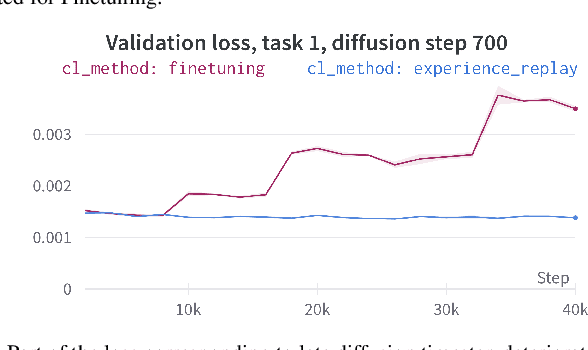

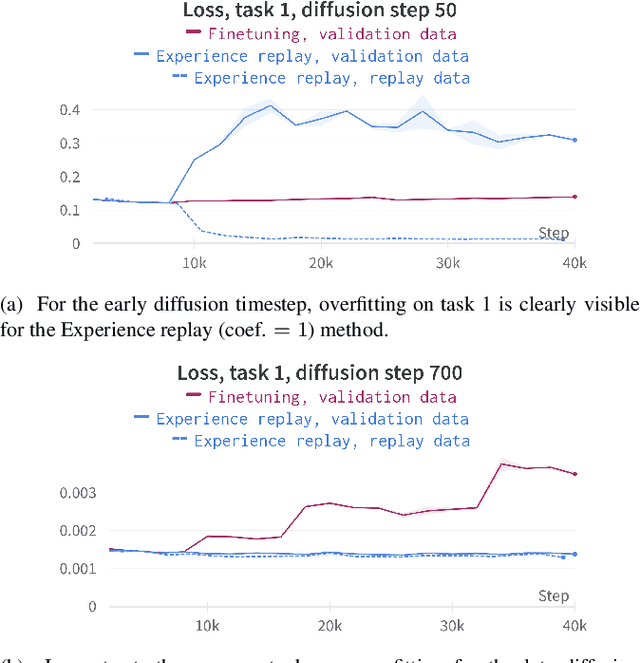
Diffusion models have achieved remarkable success in generating high-quality images thanks to their novel training procedures applied to unprecedented amounts of data. However, training a diffusion model from scratch is computationally expensive. This highlights the need to investigate the possibility of training these models iteratively, reusing computation while the data distribution changes. In this study, we take the first step in this direction and evaluate the continual learning (CL) properties of diffusion models. We begin by benchmarking the most common CL methods applied to Denoising Diffusion Probabilistic Models (DDPMs), where we note the strong performance of the experience replay with the reduced rehearsal coefficient. Furthermore, we provide insights into the dynamics of forgetting, which exhibit diverse behavior across diffusion timesteps. We also uncover certain pitfalls of using the bits-per-dimension metric for evaluating CL.
Magnushammer: A Transformer-based Approach to Premise Selection
Mar 08, 2023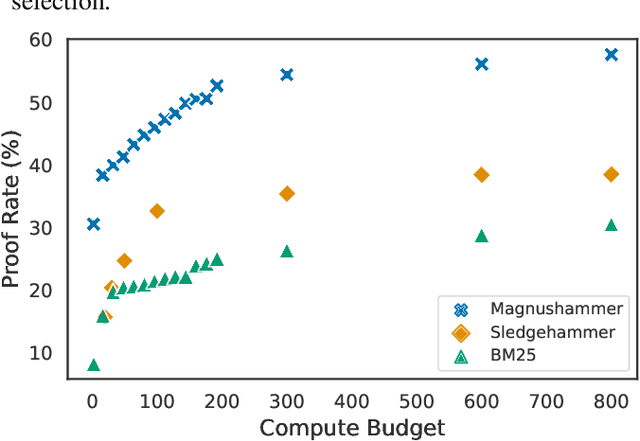
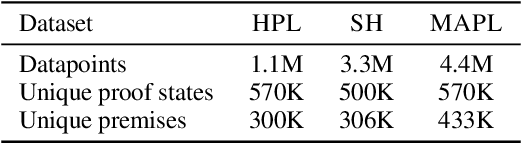
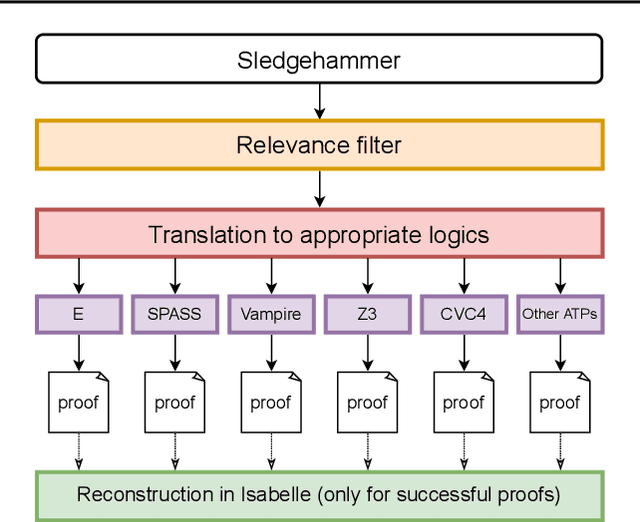

Premise selection is a fundamental problem of automated theorem proving. Previous works often use intricate symbolic methods, rely on domain knowledge, and require significant engineering effort to solve this task. In this work, we show that Magnushammer, a neural transformer-based approach, can outperform traditional symbolic systems by a large margin. Tested on the PISA benchmark, Magnushammer achieves $59.5\%$ proof rate compared to a $38.3\%$ proof rate of Sledgehammer, the most mature and popular symbolic-based solver. Furthermore, by combining Magnushammer with a neural formal prover based on a language model, we significantly improve the previous state-of-the-art proof rate from $57.0\%$ to $71.0\%$.
The Surprising Effectiveness of Latent World Models for Continual Reinforcement Learning
Nov 29, 2022



We study the use of model-based reinforcement learning methods, in particular, world models for continual reinforcement learning. In continual reinforcement learning, an agent is required to solve one task and then another sequentially while retaining performance and preventing forgetting on past tasks. World models offer a task-agnostic solution: they do not require knowledge of task changes. World models are a straight-forward baseline for continual reinforcement learning for three main reasons. Firstly, forgetting in the world model is prevented by persisting existing experience replay buffers across tasks, experience from previous tasks is replayed for learning the world model. Secondly, they are sample efficient. Thirdly and finally, they offer a task-agnostic exploration strategy through the uncertainty in the trajectories generated by the world model. We show that world models are a simple and effective continual reinforcement learning baseline. We study their effectiveness on Minigrid and Minihack continual reinforcement learning benchmarks and show that it outperforms state of the art task-agnostic continual reinforcement learning methods.