 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrashant Doshi
MVSA-Net: Multi-View State-Action Recognition for Robust and Deployable Trajectory Generation
Nov 18, 2023
The learn-from-observation (LfO) paradigm is a human-inspired mode for a robot to learn to perform a task simply by watching it being performed. LfO can facilitate robot integration on factory floors by minimizing disruption and reducing tedious programming. A key component of the LfO pipeline is a transformation of the depth camera frames to the corresponding task state and action pairs, which are then relayed to learning techniques such as imitation or inverse reinforcement learning for understanding the task parameters. While several existing computer vision models analyze videos for activity recognition, SA-Net specifically targets robotic LfO from RGB-D data. However, SA-Net and many other models analyze frame data captured from a single viewpoint. Their analysis is therefore highly sensitive to occlusions of the observed task, which are frequent in deployments. An obvious way of reducing occlusions is to simultaneously observe the task from multiple viewpoints and synchronously fuse the multiple streams in the model. Toward this, we present multi-view SA-Net, which generalizes the SA-Net model to allow the perception of multiple viewpoints of the task activity, integrate them, and better recognize the state and action in each frame. Performance evaluations on two distinct domains establish that MVSA-Net recognizes the state-action pairs under occlusion more accurately compared to single-view MVSA-Net and other baselines. Our ablation studies further evaluate its performance under different ambient conditions and establish the contribution of the architecture components. As such, MVSA-Net offers a significantly more robust and deployable state-action trajectory generation compared to previous methods.
A Novel Variational Lower Bound for Inverse Reinforcement Learning
Nov 10, 2023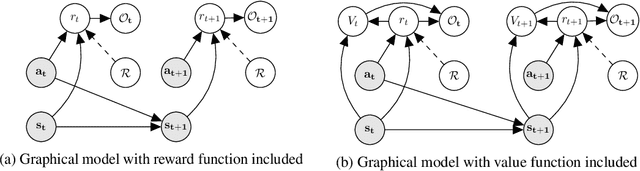
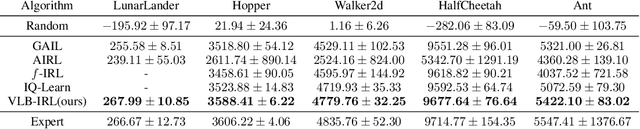
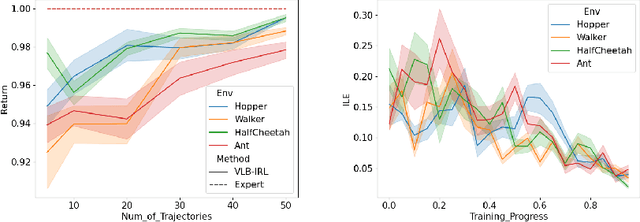
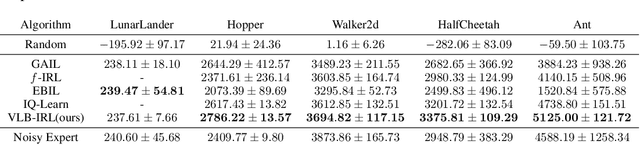
Inverse reinforcement learning (IRL) seeks to learn the reward function from expert trajectories, to understand the task for imitation or collaboration thereby removing the need for manual reward engineering. However, IRL in the context of large, high-dimensional problems with unknown dynamics has been particularly challenging. In this paper, we present a new Variational Lower Bound for IRL (VLB-IRL), which is derived under the framework of a probabilistic graphical model with an optimality node. Our method simultaneously learns the reward function and policy under the learned reward function by maximizing the lower bound, which is equivalent to minimizing the reverse Kullback-Leibler divergence between an approximated distribution of optimality given the reward function and the true distribution of optimality given trajectories. This leads to a new IRL method that learns a valid reward function such that the policy under the learned reward achieves expert-level performance on several known domains. Importantly, the method outperforms the existing state-of-the-art IRL algorithms on these domains by demonstrating better reward from the learned policy.
Latent Interactive A2C for Improved RL in Open Many-Agent Systems
May 09, 2023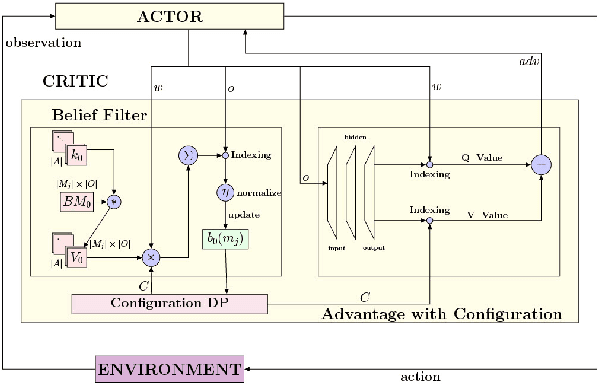
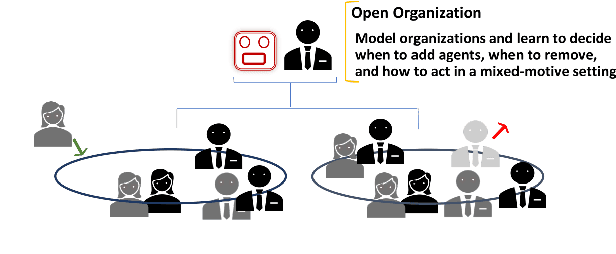

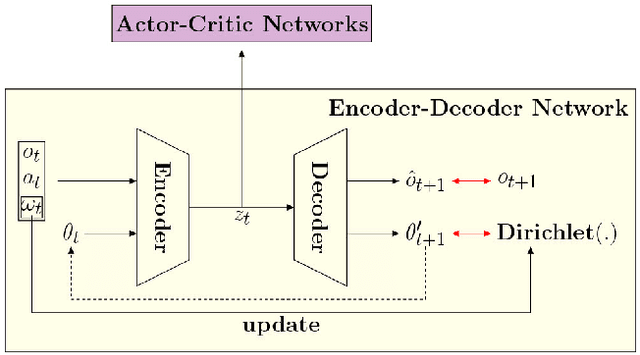
There is a prevalence of multiagent reinforcement learning (MARL) methods that engage in centralized training. But, these methods involve obtaining various types of information from the other agents, which may not be feasible in competitive or adversarial settings. A recent method, the interactive advantage actor critic (IA2C), engages in decentralized training coupled with decentralized execution, aiming to predict the other agents' actions from possibly noisy observations. In this paper, we present the latent IA2C that utilizes an encoder-decoder architecture to learn a latent representation of the hidden state and other agents' actions. Our experiments in two domains -- each populated by many agents -- reveal that the latent IA2C significantly improves sample efficiency by reducing variance and converging faster. Additionally, we introduce open versions of these domains where the agent population may change over time, and evaluate on these instances as well.
IRL with Partial Observations using the Principle of Uncertain Maximum Entropy
Aug 15, 2022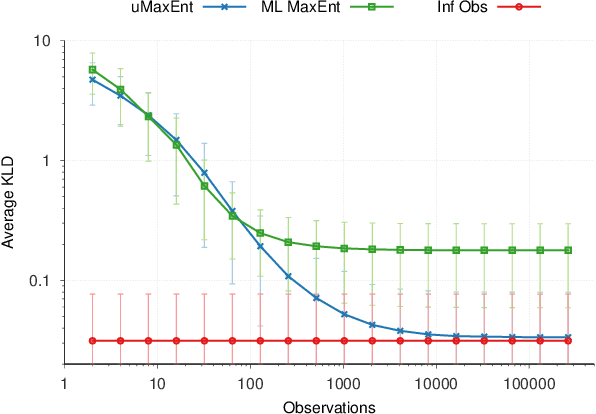
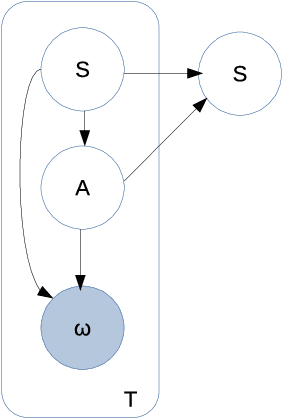
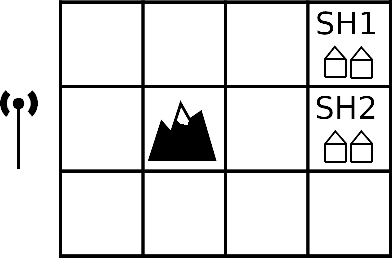
The principle of maximum entropy is a broadly applicable technique for computing a distribution with the least amount of information possible while constrained to match empirically estimated feature expectations. However, in many real-world applications that use noisy sensors computing the feature expectations may be challenging due to partial observation of the relevant model variables. For example, a robot performing apprenticeship learning may lose sight of the agent it is learning from due to environmental occlusion. We show that in generalizing the principle of maximum entropy to these types of scenarios we unavoidably introduce a dependency on the learned model to the empirical feature expectations. We introduce the principle of uncertain maximum entropy and present an expectation-maximization based solution generalized from the principle of latent maximum entropy. Finally, we experimentally demonstrate the improved robustness to noisy data offered by our technique in a maximum causal entropy inverse reinforcement learning domain.
Marginal MAP Estimation for Inverse RL under Occlusion with Observer Noise
Sep 16, 2021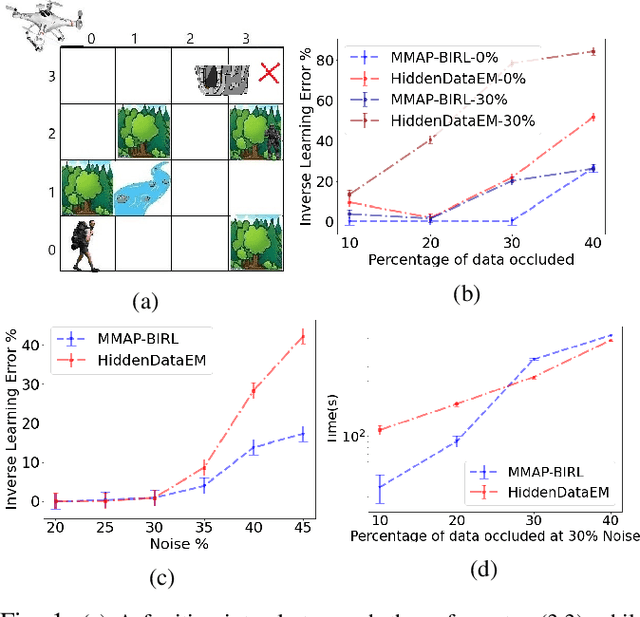

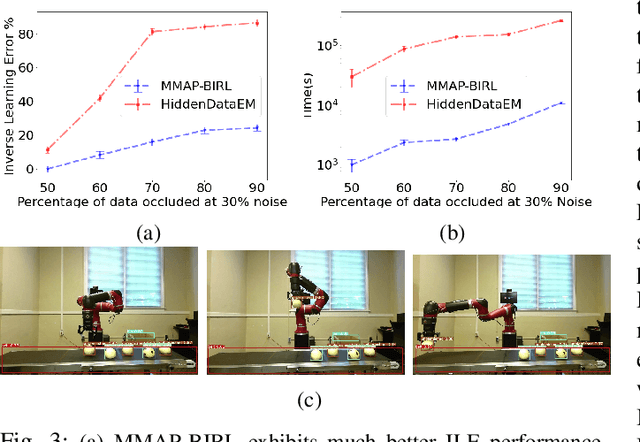

We consider the problem of learning the behavioral preferences of an expert engaged in a task from noisy and partially-observable demonstrations. This is motivated by real-world applications such as a line robot learning from observing a human worker, where some observations are occluded by environmental objects that cannot be removed. Furthermore, robotic perception tends to be imperfect and noisy. Previous techniques for inverse reinforcement learning (IRL) take the approach of either omitting the missing portions or inferring it as part of expectation-maximization, which tends to be slow and prone to local optima. We present a new method that generalizes the well-known Bayesian maximum-a-posteriori (MAP) IRL method by marginalizing the occluded portions of the trajectory. This is additionally extended with an observation model to account for perception noise. We show that the marginal MAP (MMAP) approach significantly improves on the previous IRL technique under occlusion in both formative evaluations on a toy problem and in a summative evaluation on an onion sorting line task by a robot.
A Hierarchical Bayesian model for Inverse RL in Partially-Controlled Environments
Jul 13, 2021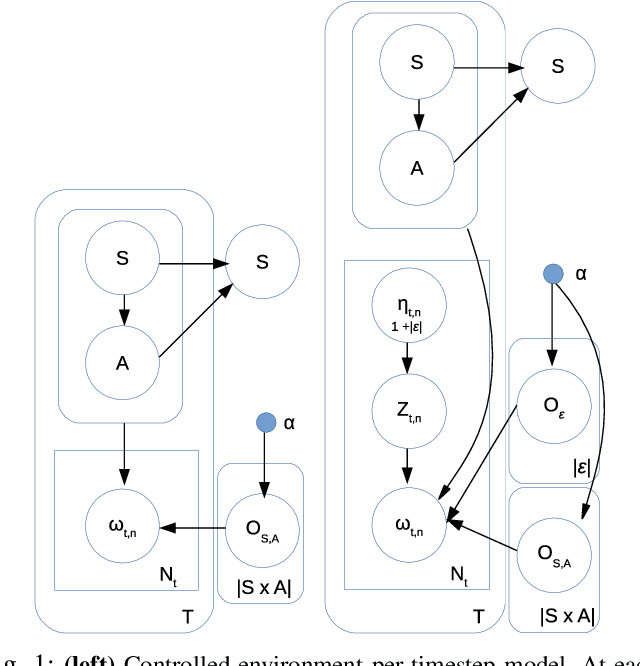
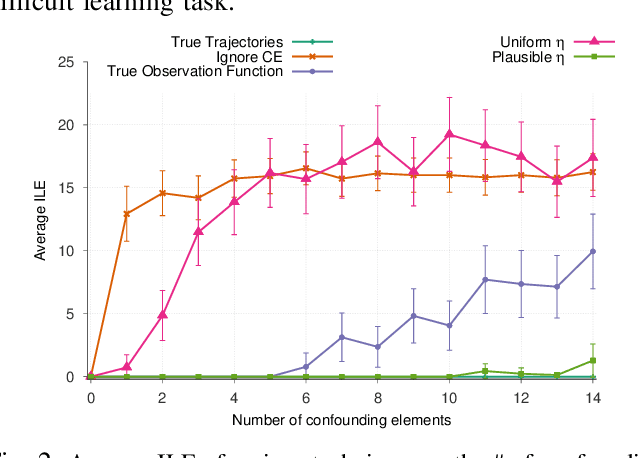
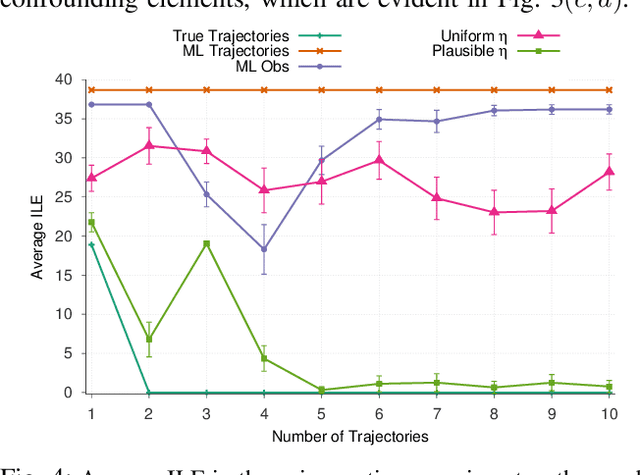
Robots learning from observations in the real world using inverse reinforcement learning (IRL) may encounter objects or agents in the environment, other than the expert, that cause nuisance observations during the demonstration. These confounding elements are typically removed in fully-controlled environments such as virtual simulations or lab settings. When complete removal is impossible the nuisance observations must be filtered out. However, identifying the source of observations when large amounts of observations are made is difficult. To address this, we present a hierarchical Bayesian model that incorporates both the expert's and the confounding elements' observations thereby explicitly modeling the diverse observations a robot may receive. We extend an existing IRL algorithm originally designed to work under partial occlusion of the expert to consider the diverse observations. In a simulated robotic sorting domain containing both occlusion and confounding elements, we demonstrate the model's effectiveness. In particular, our technique outperforms several other comparative methods, second only to having perfect knowledge of the subject's trajectory.
Many Agent Reinforcement Learning Under Partial Observability
Jun 17, 2021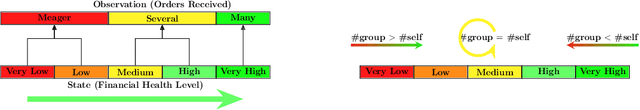
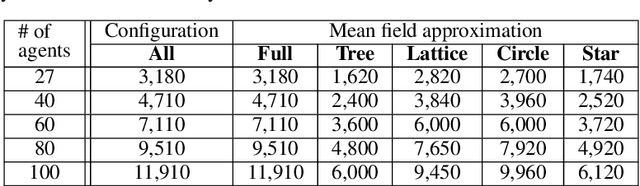
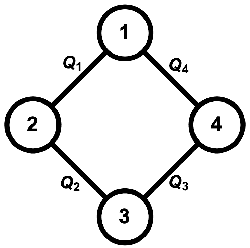
Recent renewed interest in multi-agent reinforcement learning (MARL) has generated an impressive array of techniques that leverage deep reinforcement learning, primarily actor-critic architectures, and can be applied to a limited range of settings in terms of observability and communication. However, a continuing limitation of much of this work is the curse of dimensionality when it comes to representations based on joint actions, which grow exponentially with the number of agents. In this paper, we squarely focus on this challenge of scalability. We apply the key insight of action anonymity, which leads to permutation invariance of joint actions, to two recently presented deep MARL algorithms, MADDPG and IA2C, and compare these instantiations to another recent technique that leverages action anonymity, viz., mean-field MARL. We show that our instantiations can learn the optimal behavior in a broader class of agent networks than the mean-field method, using a recently introduced pragmatic domain.
Cooperative-Competitive Reinforcement Learning with History-Dependent Rewards
Oct 15, 2020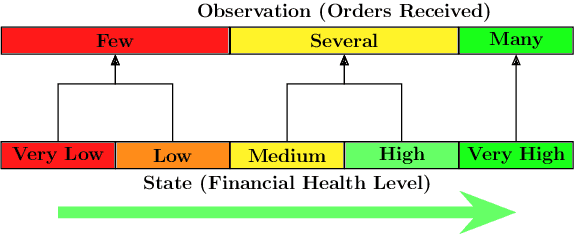

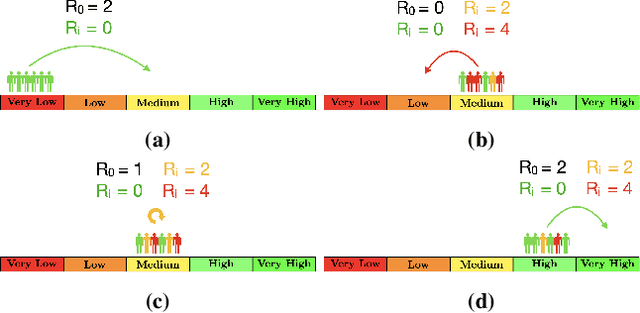

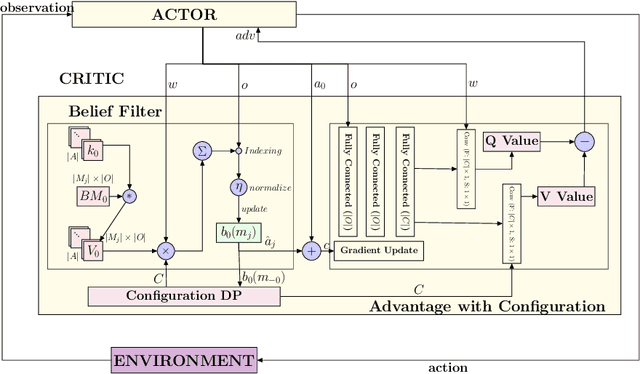
Consider a typical organization whose worker agents seek to collectively cooperate for its general betterment. However, each individual agent simultaneously seeks to act to secure a larger chunk than its co-workers of the annual increment in compensation, which usually comes from a {\em fixed} pot. As such, the individual agent in the organization must cooperate and compete. Another feature of many organizations is that a worker receives a bonus, which is often a fraction of previous year's total profit. As such, the agent derives a reward that is also partly dependent on historical performance. How should the individual agent decide to act in this context? Few methods for the mixed cooperative-competitive setting have been presented in recent years, but these are challenged by problem domains whose reward functions do not depend on the current state and action only. Recent deep multi-agent reinforcement learning (MARL) methods using long short-term memory (LSTM) may be used, but these adopt a joint perspective to the interaction or require explicit exchange of information among the agents to promote cooperation, which may not be possible under competition. In this paper, we first show that the agent's decision-making problem can be modeled as an interactive partially observable Markov decision process (I-POMDP) that captures the dynamic of a history-dependent reward. We present an interactive advantage actor-critic method (IA2C$^+$), which combines the independent advantage actor-critic network with a belief filter that maintains a belief distribution over other agents' models. Empirical results show that IA2C$^+$ learns the optimal policy faster and more robustly than several other baselines including one that uses a LSTM, even when attributed models are incorrect.
Recurrent Sum-Product-Max Networks for Decision Making in Perfectly-Observed Environments
Jun 12, 2020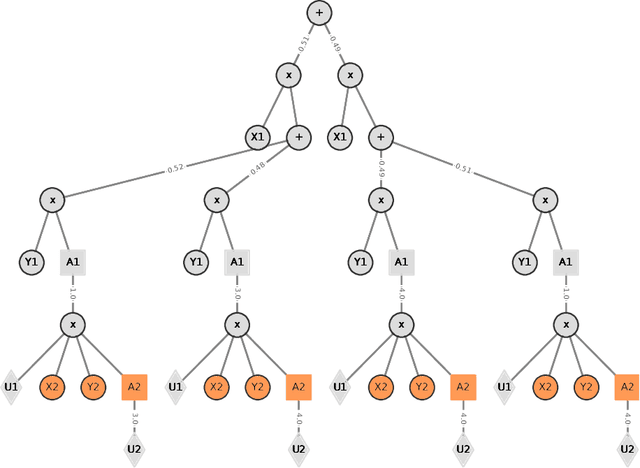

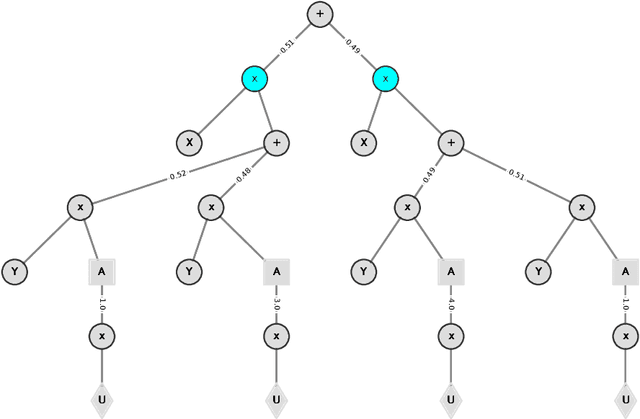
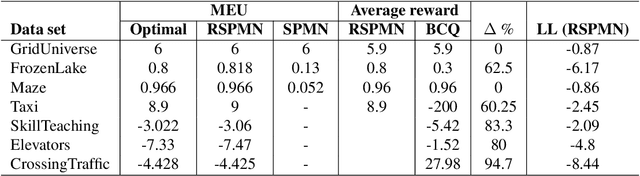
Recent investigations into sum-product-max networks (SPMN) that generalize sum-product networks (SPN) offer a data-driven alternative for decision making, which has predominantly relied on handcrafted models. SPMNs computationally represent a probabilistic decision-making problem whose solution scales linearly in the size of the network. However, SPMNs are not well suited for sequential decision making over multiple time steps. In this paper, we present recurrent SPMNs (RSPMN) that learn from and model decision-making data over time. RSPMNs utilize a template network that is unfolded as needed depending on the length of the data sequence. This is significant as RSPMNs not only inherit the benefits of SPMNs in being data driven and mostly tractable, they are also well suited for sequential problems. We establish conditions on the template network, which guarantee that the resulting SPMN is valid, and present a structure learning algorithm to learn a sound template network. We demonstrate that the RSPMNs learned on a testbed of sequential decision-making data sets generate MEUs and policies that are close to the optimal on perfectly-observed domains. They easily improve on a recent batch-constrained reinforcement learning method, which is important because RSPMNs offer a new model-based approach to offline reinforcement learning.
Maximum Entropy Multi-Task Inverse RL
Apr 27, 2020
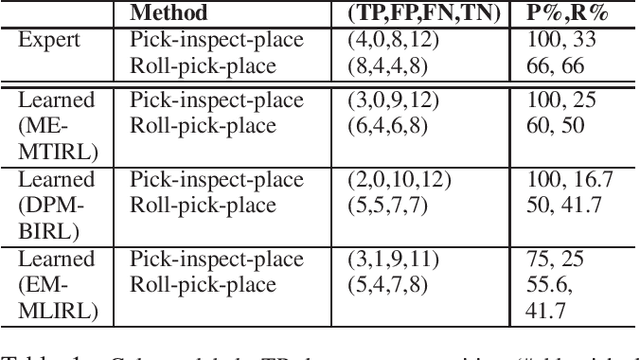
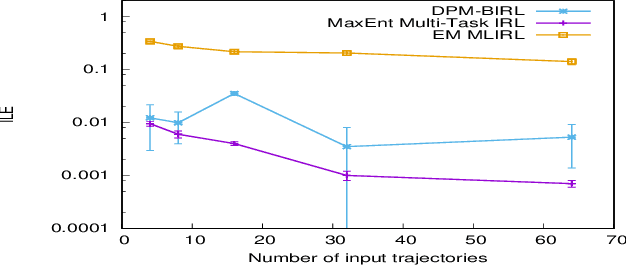
Multi-task IRL allows for the possibility that the expert could be switching between multiple ways of solving the same problem, or interleaving demonstrations of multiple tasks. The learner aims to learn the multiple reward functions that guide these ways of solving the problem. We present a new method for multi-task IRL that generalizes the well-known maximum entropy approach to IRL by combining it with the Dirichlet process based clustering of the observed input. This yields a single nonlinear optimization problem, called MaxEnt Multi-task IRL, which can be solved using the Lagrangian relaxation and gradient descent methods. We evaluate MaxEnt Multi-task IRL in simulation on the robotic task of sorting onions on a processing line where the expert utilizes multiple ways of detecting and removing blemished onions. The method is able to learn the underlying reward functions to a high level of accuracy and it improves on the previous approaches to multi-task IRL.