 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePraveen Manoharan
On the (Statistical) Detection of Adversarial Examples
Oct 17, 2017
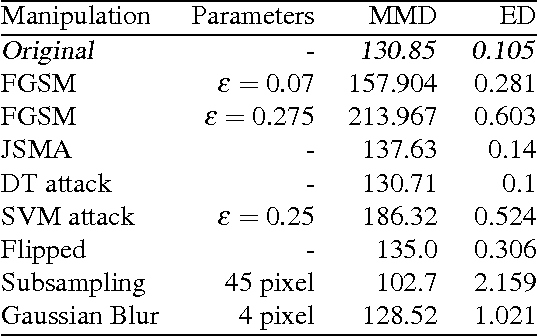
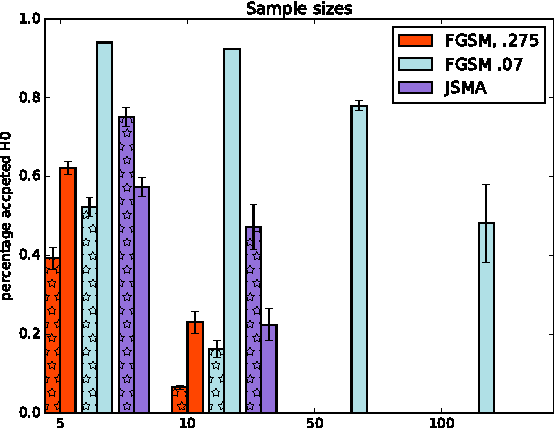

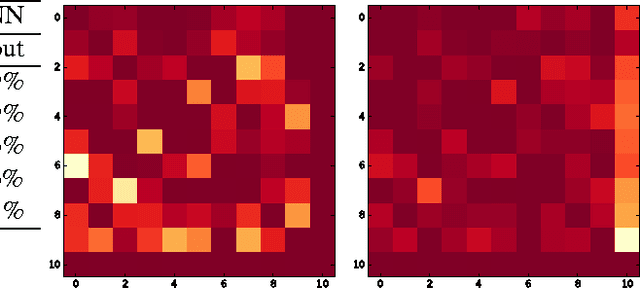
Machine Learning (ML) models are applied in a variety of tasks such as network intrusion detection or Malware classification. Yet, these models are vulnerable to a class of malicious inputs known as adversarial examples. These are slightly perturbed inputs that are classified incorrectly by the ML model. The mitigation of these adversarial inputs remains an open problem. As a step towards understanding adversarial examples, we show that they are not drawn from the same distribution than the original data, and can thus be detected using statistical tests. Using thus knowledge, we introduce a complimentary approach to identify specific inputs that are adversarial. Specifically, we augment our ML model with an additional output, in which the model is trained to classify all adversarial inputs. We evaluate our approach on multiple adversarial example crafting methods (including the fast gradient sign and saliency map methods) with several datasets. The statistical test flags sample sets containing adversarial inputs confidently at sample sizes between 10 and 100 data points. Furthermore, our augmented model either detects adversarial examples as outliers with high accuracy (> 80%) or increases the adversary's cost - the perturbation added - by more than 150%. In this way, we show that statistical properties of adversarial examples are essential to their detection.
Adversarial Perturbations Against Deep Neural Networks for Malware Classification
Jun 16, 2016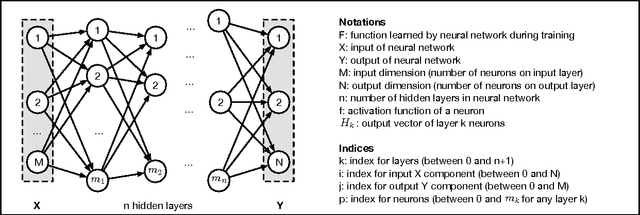
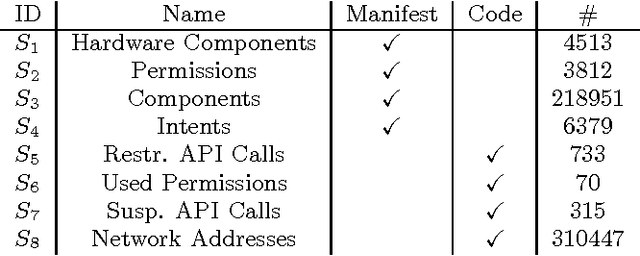
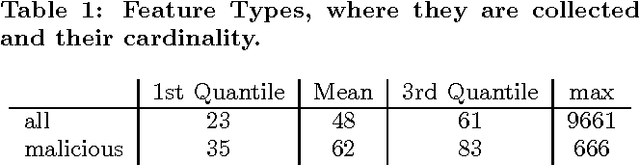
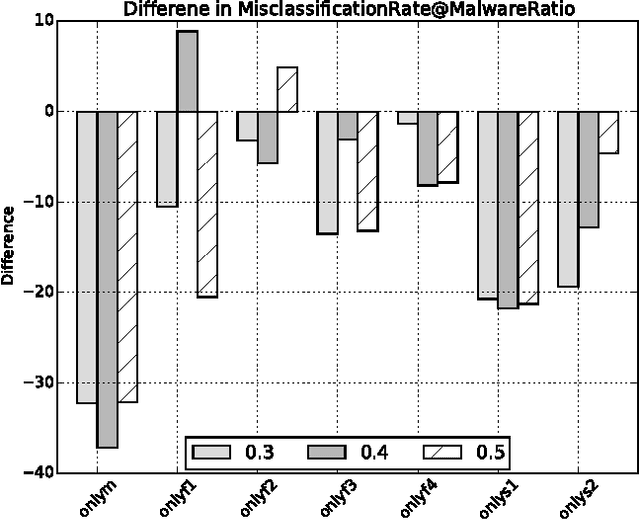
Deep neural networks, like many other machine learning models, have recently been shown to lack robustness against adversarially crafted inputs. These inputs are derived from regular inputs by minor yet carefully selected perturbations that deceive machine learning models into desired misclassifications. Existing work in this emerging field was largely specific to the domain of image classification, since the high-entropy of images can be conveniently manipulated without changing the images' overall visual appearance. Yet, it remains unclear how such attacks translate to more security-sensitive applications such as malware detection - which may pose significant challenges in sample generation and arguably grave consequences for failure. In this paper, we show how to construct highly-effective adversarial sample crafting attacks for neural networks used as malware classifiers. The application domain of malware classification introduces additional constraints in the adversarial sample crafting problem when compared to the computer vision domain: (i) continuous, differentiable input domains are replaced by discrete, often binary inputs; and (ii) the loose condition of leaving visual appearance unchanged is replaced by requiring equivalent functional behavior. We demonstrate the feasibility of these attacks on many different instances of malware classifiers that we trained using the DREBIN Android malware data set. We furthermore evaluate to which extent potential defensive mechanisms against adversarial crafting can be leveraged to the setting of malware classification. While feature reduction did not prove to have a positive impact, distillation and re-training on adversarially crafted samples show promising results.