 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQi Bi
Modeling Weather Uncertainty for Multi-weather Co-Presence Estimation
Mar 29, 2024
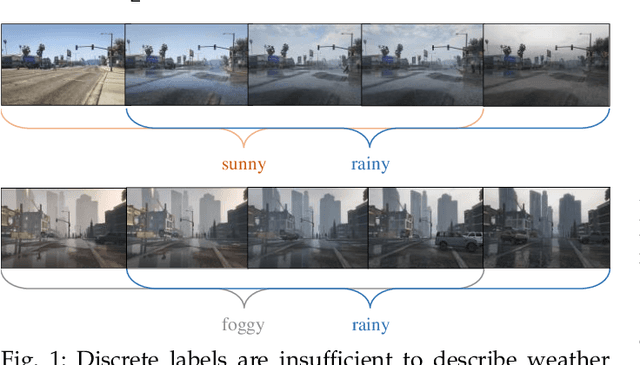
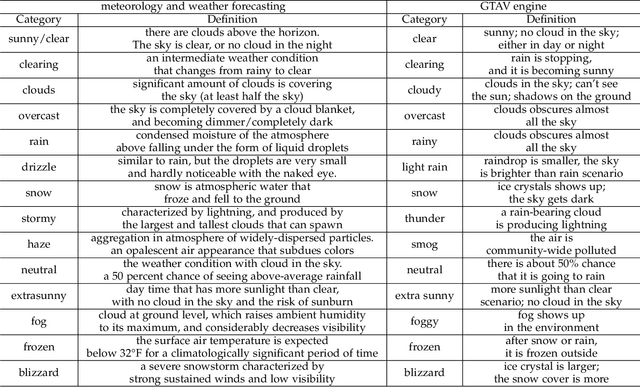

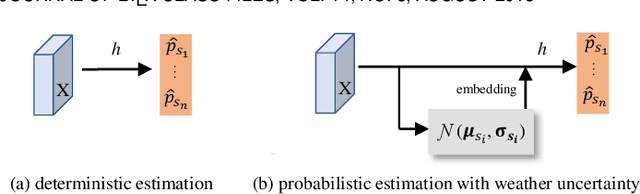
Images from outdoor scenes may be taken under various weather conditions. It is well studied that weather impacts the performance of computer vision algorithms and needs to be handled properly. However, existing algorithms model weather condition as a discrete status and estimate it using multi-label classification. The fact is that, physically, specifically in meteorology, weather are modeled as a continuous and transitional status. Instead of directly implementing hard classification as existing multi-weather classification methods do, we consider the physical formulation of multi-weather conditions and model the impact of physical-related parameter on learning from the image appearance. In this paper, we start with solid revisit of the physics definition of weather and how it can be described as a continuous machine learning and computer vision task. Namely, we propose to model the weather uncertainty, where the level of probability and co-existence of multiple weather conditions are both considered. A Gaussian mixture model is used to encapsulate the weather uncertainty and a uncertainty-aware multi-weather learning scheme is proposed based on prior-posterior learning. A novel multi-weather co-presence estimation transformer (MeFormer) is proposed. In addition, a new multi-weather co-presence estimation (MePe) dataset, along with 14 fine-grained weather categories and 16,078 samples, is proposed to benchmark both conventional multi-label weather classification task and multi-weather co-presence estimation task. Large scale experiments show that the proposed method achieves state-of-the-art performance and substantial generalization capabilities on both the conventional multi-label weather classification task and the proposed multi-weather co-presence estimation task. Besides, modeling weather uncertainty also benefits adverse-weather semantic segmentation.
Constraint Latent Space Matters: An Anti-anomalous Waveform Transformation Solution from Photoplethysmography to Arterial Blood Pressure
Feb 23, 2024Arterial blood pressure (ABP) holds substantial promise for proactive cardiovascular health management. Notwithstanding its potential, the invasive nature of ABP measurements confines their utility primarily to clinical environments, limiting their applicability for continuous monitoring beyond medical facilities. The conversion of photoplethysmography (PPG) signals into ABP equivalents has garnered significant attention due to its potential in revolutionizing cardiovascular disease management. Recent strides in PPG-to-ABP prediction encompass the integration of generative and discriminative models. Despite these advances, the efficacy of these models is curtailed by the latent space shift predicament, stemming from alterations in PPG data distribution across disparate hardware and individuals, potentially leading to distorted ABP waveforms. To tackle this problem, we present an innovative solution named the Latent Space Constraint Transformer (LSCT), leveraging a quantized codebook to yield robust latent spaces by employing multiple discretizing bases. To facilitate improved reconstruction, the Correlation-boosted Attention Module (CAM) is introduced to systematically query pertinent bases on a global scale. Furthermore, to enhance expressive capacity, we propose the Multi-Spectrum Enhancement Knowledge (MSEK), which fosters local information flow within the channels of latent code and provides additional embedding for reconstruction. Through comprehensive experimentation on both publicly available datasets and a private downstream task dataset, the proposed approach demonstrates noteworthy performance enhancements compared to existing methods. Extensive ablation studies further substantiate the effectiveness of each introduced module.
GOOD: Towards Domain Generalized Orientated Object Detection
Feb 20, 2024Oriented object detection has been rapidly developed in the past few years, but most of these methods assume the training and testing images are under the same statistical distribution, which is far from reality. In this paper, we propose the task of domain generalized oriented object detection, which intends to explore the generalization of oriented object detectors on arbitrary unseen target domains. Learning domain generalized oriented object detectors is particularly challenging, as the cross-domain style variation not only negatively impacts the content representation, but also leads to unreliable orientation predictions. To address these challenges, we propose a generalized oriented object detector (GOOD). After style hallucination by the emerging contrastive language-image pre-training (CLIP), it consists of two key components, namely, rotation-aware content consistency learning (RAC) and style consistency learning (SEC). The proposed RAC allows the oriented object detector to learn stable orientation representation from style-diversified samples. The proposed SEC further stabilizes the generalization ability of content representation from different image styles. Extensive experiments on multiple cross-domain settings show the state-of-the-art performance of GOOD. Source code will be publicly available.
Cross-Level Multi-Instance Distillation for Self-Supervised Fine-Grained Visual Categorization
Jan 16, 2024High-quality annotation of fine-grained visual categories demands great expert knowledge, which is taxing and time consuming. Alternatively, learning fine-grained visual representation from enormous unlabeled images (e.g., species, brands) by self-supervised learning becomes a feasible solution. However, recent researches find that existing self-supervised learning methods are less qualified to represent fine-grained categories. The bottleneck lies in that the pre-text representation is built from every patch-wise embedding, while fine-grained categories are only determined by several key patches of an image. In this paper, we propose a Cross-level Multi-instance Distillation (CMD) framework to tackle the challenge. Our key idea is to consider the importance of each image patch in determining the fine-grained pre-text representation by multiple instance learning. To comprehensively learn the relation between informative patches and fine-grained semantics, the multi-instance knowledge distillation is implemented on both the region/image crop pairs from the teacher and student net, and the region-image crops inside the teacher / student net, which we term as intra-level multi-instance distillation and inter-level multi-instance distillation. Extensive experiments on CUB-200-2011, Stanford Cars and FGVC Aircraft show that the proposed method outperforms the contemporary method by upto 10.14% and existing state-of-the-art self-supervised learning approaches by upto 19.78% on both top-1 accuracy and Rank-1 retrieval metric.
Learning Content-enhanced Mask Transformer for Domain Generalized Urban-Scene Segmentation
Jul 01, 2023
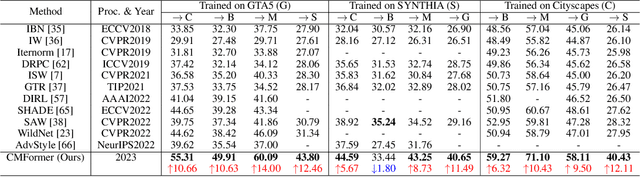
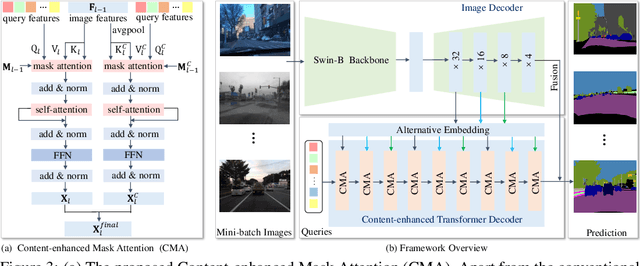

Domain-generalized urban-scene semantic segmentation (USSS) aims to learn generalized semantic predictions across diverse urban-scene styles. Unlike domain gap challenges, USSS is unique in that the semantic categories are often similar in different urban scenes, while the styles can vary significantly due to changes in urban landscapes, weather conditions, lighting, and other factors. Existing approaches typically rely on convolutional neural networks (CNNs) to learn the content of urban scenes. In this paper, we propose a Content-enhanced Mask TransFormer (CMFormer) for domain-generalized USSS. The main idea is to enhance the focus of the fundamental component, the mask attention mechanism, in Transformer segmentation models on content information. To achieve this, we introduce a novel content-enhanced mask attention mechanism. It learns mask queries from both the image feature and its down-sampled counterpart, as lower-resolution image features usually contain more robust content information and are less sensitive to style variations. These features are fused into a Transformer decoder and integrated into a multi-resolution content-enhanced mask attention learning scheme. Extensive experiments conducted on various domain-generalized urban-scene segmentation datasets demonstrate that the proposed CMFormer significantly outperforms existing CNN-based methods for domain-generalized semantic segmentation, achieving improvements of up to 14.00\% in terms of mIoU (mean intersection over union). The source code for CMFormer will be made available at this \href{https://github.com/BiQiWHU/domain-generalized-urban-scene-segmentation}{repository}.
Segment Anything Is Not Always Perfect: An Investigation of SAM on Different Real-world Applications
Apr 13, 2023



Recently, Meta AI Research approaches a general, promptable Segment Anything Model (SAM) pre-trained on an unprecedentedly large segmentation dataset (SA-1B). Without a doubt, the emergence of SAM will yield significant benefits for a wide array of practical image segmentation applications. In this study, we conduct a series of intriguing investigations into the performance of SAM across various applications, particularly in the fields of natural images, agriculture, manufacturing, remote sensing, and healthcare. We analyze and discuss the benefits and limitations of SAM and provide an outlook on future development of segmentation tasks. Note that our work does not intend to propose new algorithms or theories, but rather provide a comprehensive view of SAM in practice. This work is expected to provide insights that facilitate future research activities toward generic segmentation.
Promoting Saliency From Depth: Deep Unsupervised RGB-D Saliency Detection
May 15, 2022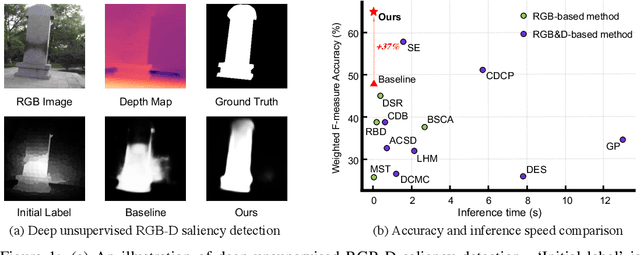
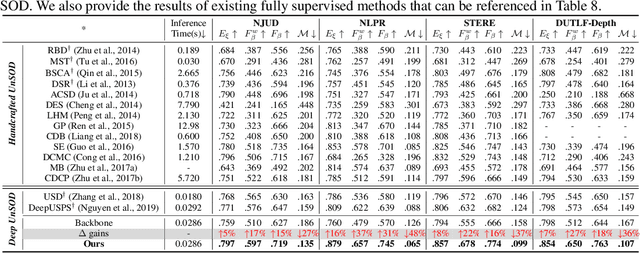
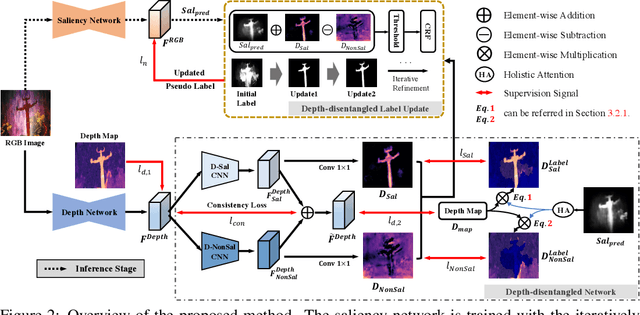
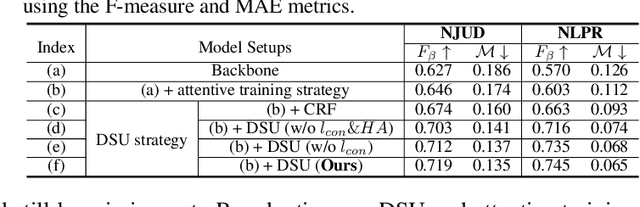
Growing interests in RGB-D salient object detection (RGB-D SOD) have been witnessed in recent years, owing partly to the popularity of depth sensors and the rapid progress of deep learning techniques. Unfortunately, existing RGB-D SOD methods typically demand large quantity of training images being thoroughly annotated at pixel-level. The laborious and time-consuming manual annotation has become a real bottleneck in various practical scenarios. On the other hand, current unsupervised RGB-D SOD methods still heavily rely on handcrafted feature representations. This inspires us to propose in this paper a deep unsupervised RGB-D saliency detection approach, which requires no manual pixel-level annotation during training. It is realized by two key ingredients in our training pipeline. First, a depth-disentangled saliency update (DSU) framework is designed to automatically produce pseudo-labels with iterative follow-up refinements, which provides more trustworthy supervision signals for training the saliency network. Second, an attentive training strategy is introduced to tackle the issue of noisy pseudo-labels, by properly re-weighting to highlight the more reliable pseudo-labels. Extensive experiments demonstrate the superior efficiency and effectiveness of our approach in tackling the challenging unsupervised RGB-D SOD scenarios. Moreover, our approach can also be adapted to work in fully-supervised situation. Empirical studies show the incorporation of our approach gives rise to notably performance improvement in existing supervised RGB-D SOD models.
All Grains, One Scheme (AGOS): Learning Multi-grain Instance Representation for Aerial Scene Classification
May 06, 2022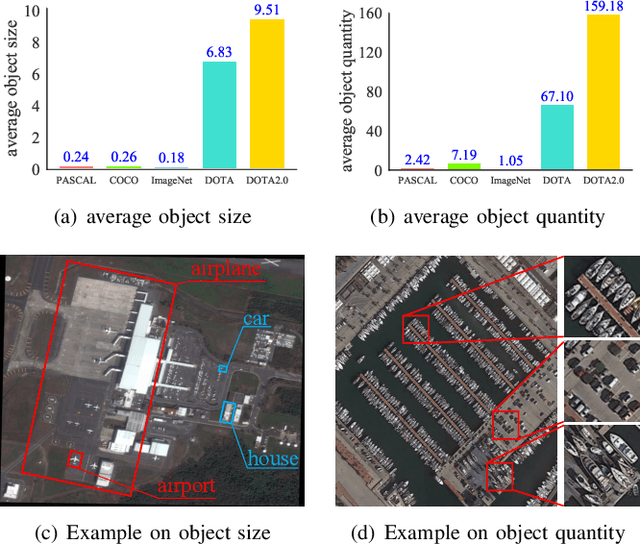
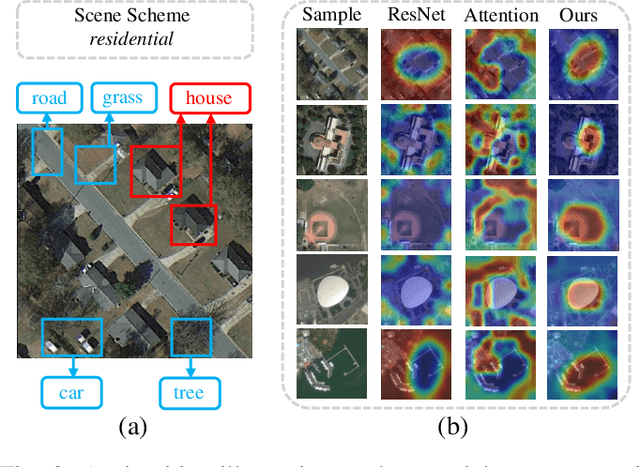
Aerial scene classification remains challenging as: 1) the size of key objects in determining the scene scheme varies greatly; 2) many objects irrelevant to the scene scheme are often flooded in the image. Hence, how to effectively perceive the region of interests (RoIs) from a variety of sizes and build more discriminative representation from such complicated object distribution is vital to understand an aerial scene. In this paper, we propose a novel all grains, one scheme (AGOS) framework to tackle these challenges. To the best of our knowledge, it is the first work to extend the classic multiple instance learning into multi-grain formulation. Specially, it consists of a multi-grain perception module (MGP), a multi-branch multi-instance representation module (MBMIR) and a self-aligned semantic fusion (SSF) module. Firstly, our MGP preserves the differential dilated convolutional features from the backbone, which magnifies the discriminative information from multi-grains. Then, our MBMIR highlights the key instances in the multi-grain representation under the MIL formulation. Finally, our SSF allows our framework to learn the same scene scheme from multi-grain instance representations and fuses them, so that the entire framework is optimized as a whole. Notably, our AGOS is flexible and can be easily adapted to existing CNNs in a plug-and-play manner. Extensive experiments on UCM, AID and NWPU benchmarks demonstrate that our AGOS achieves a comparable performance against the state-of-the-art methods.
Label-efficient Hybrid-supervised Learning for Medical Image Segmentation
Mar 10, 2022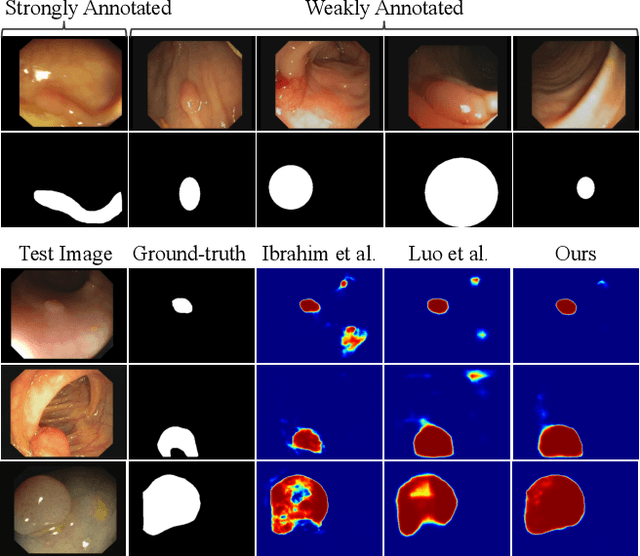

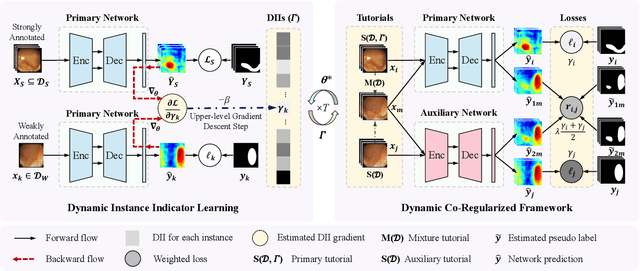

Due to the lack of expertise for medical image annotation, the investigation of label-efficient methodology for medical image segmentation becomes a heated topic. Recent progresses focus on the efficient utilization of weak annotations together with few strongly-annotated labels so as to achieve comparable segmentation performance in many unprofessional scenarios. However, these approaches only concentrate on the supervision inconsistency between strongly- and weakly-annotated instances but ignore the instance inconsistency inside the weakly-annotated instances, which inevitably leads to performance degradation. To address this problem, we propose a novel label-efficient hybrid-supervised framework, which considers each weakly-annotated instance individually and learns its weight guided by the gradient direction of the strongly-annotated instances, so that the high-quality prior in the strongly-annotated instances is better exploited and the weakly-annotated instances are depicted more precisely. Specially, our designed dynamic instance indicator (DII) realizes the above objectives, and is adapted to our dynamic co-regularization (DCR) framework further to alleviate the erroneous accumulation from distortions of weak annotations. Extensive experiments on two hybrid-supervised medical segmentation datasets demonstrate that with only 10% strong labels, the proposed framework can leverage the weak labels efficiently and achieve competitive performance against the 100% strong-label supervised scenario.
Building change detection based on multi-scale filtering and grid partition
Aug 22, 2019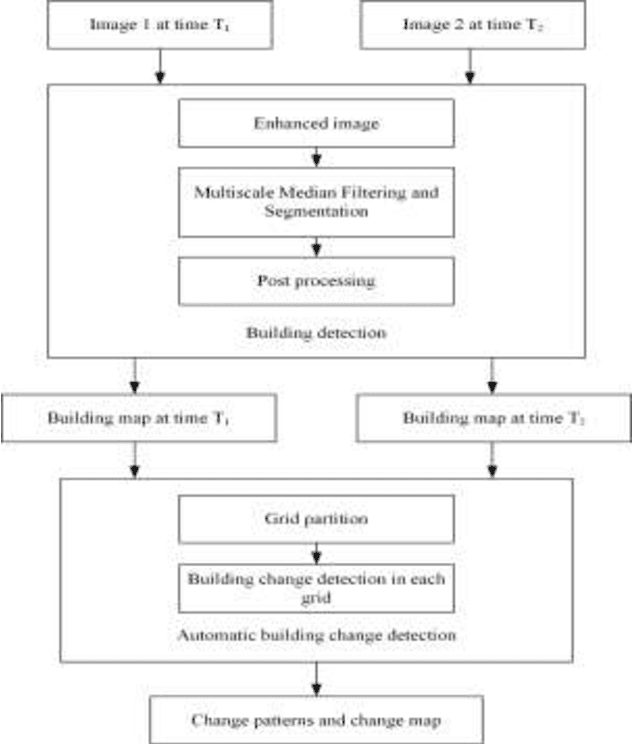


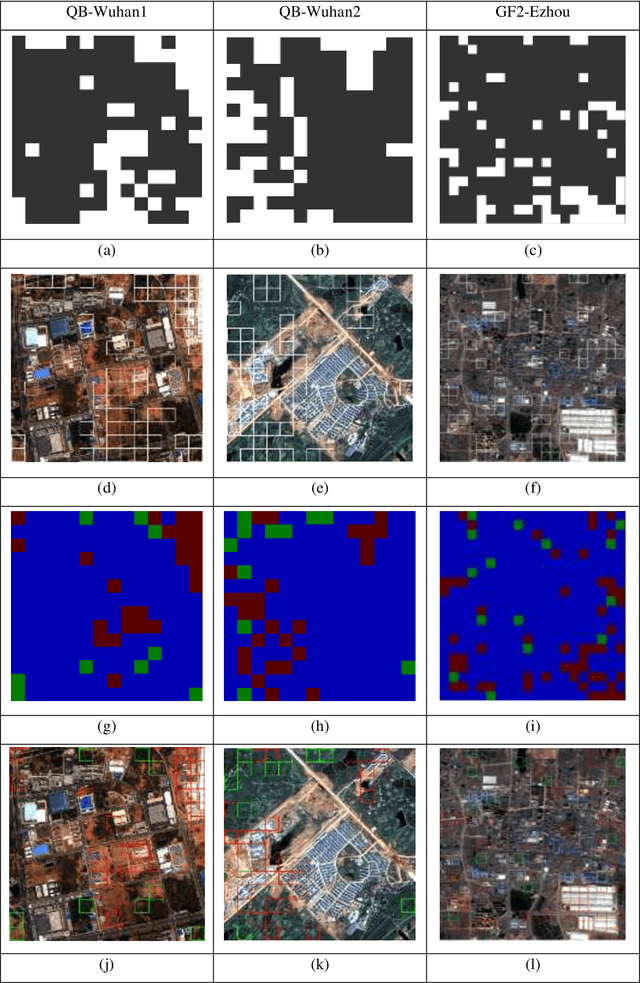
Building change detection is of great significance in high resolution remote sensing applications. Multi-index learning, one of the state-of-the-art building change detection methods, still has drawbacks like incapability to find change types directly and heavy computation consumption of MBI. In this paper, a two-stage building change detection method is proposed to address these problems. In the first stage, a multi-scale filtering building index (MFBI) is calculated to detect building areas in each temporal with fast speed and moderate accuracy. In the second stage, images and the corresponding building maps are partitioned into grids. In each grid, the ratio of building areas in time T2 and time T1 is calculated. Each grid is classified into one of the three change patterns, i.e., significantly increase, significantly decrease and approximately unchanged. Exhaustive experiments indicate that the proposed method can detect building change types directly and outperform the current multi-index learning method.
* 8 pages, 6 figures, conference paper