 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiang Zhang
PM2: A New Prompting Multi-modal Model Paradigm for Few-shot Medical Image Classification
Apr 13, 2024
Few-shot learning has been successfully applied to medical image classification as only very few medical examples are available for training. Due to the challenging problem of limited number of annotated medical images, image representations should not be solely derived from a single image modality which is insufficient for characterizing concept classes. In this paper, we propose a new prompting multi-modal model paradigm on medical image classification based on multi-modal foundation models, called PM2. Besides image modality,PM2 introduces another supplementary text input, known as prompt, to further describe corresponding image or concept classes and facilitate few-shot learning across diverse modalities. To better explore the potential of prompt engineering, we empirically investigate five distinct prompt schemes under the new paradigm. Furthermore, linear probing in multi-modal models acts as a linear classification head taking as input only class token, which ignores completely merits of rich statistics inherent in high-level visual tokens. Thus, we alternatively perform a linear classification on feature distribution of visual tokens and class token simultaneously. To effectively mine such rich statistics, a global covariance pooling with efficient matrix power normalization is used to aggregate visual tokens. Then we study and combine two classification heads. One is shared for class token of image from vision encoder and prompt representation encoded by text encoder. The other is to classification on feature distribution of visual tokens from vision encoder. Extensive experiments on three medical datasets show that our PM2 significantly outperforms counterparts regardless of prompt schemes and achieves state-of-the-art performance.
Sample-Efficient Human Evaluation of Large Language Models via Maximum Discrepancy Competition
Apr 10, 2024The past years have witnessed a proliferation of large language models (LLMs). Yet, automated and unbiased evaluation of LLMs is challenging due to the inaccuracy of standard metrics in reflecting human preferences and the inefficiency in sampling informative and diverse test examples. While human evaluation remains the gold standard, it is expensive and time-consuming, especially when dealing with a large number of testing samples. To address this problem, we propose a sample-efficient human evaluation method based on MAximum Discrepancy (MAD) competition. MAD automatically selects a small set of informative and diverse instructions, each adapted to two LLMs, whose responses are subject to three-alternative forced choice by human subjects. The pairwise comparison results are then aggregated into a global ranking using the Elo rating system. We select eight representative LLMs and compare them in terms of four skills: knowledge understanding, mathematical reasoning, writing, and coding. Experimental results show that the proposed method achieves a reliable and sensible ranking of LLMs' capabilities, identifies their relative strengths and weaknesses, and offers valuable insights for further LLM advancement.
Weakly Supervised Deep Hyperspherical Quantization for Image Retrieval
Apr 07, 2024Deep quantization methods have shown high efficiency on large-scale image retrieval. However, current models heavily rely on ground-truth information, hindering the application of quantization in label-hungry scenarios. A more realistic demand is to learn from inexhaustible uploaded images that are associated with informal tags provided by amateur users. Though such sketchy tags do not obviously reveal the labels, they actually contain useful semantic information for supervising deep quantization. To this end, we propose Weakly-Supervised Deep Hyperspherical Quantization (WSDHQ), which is the first work to learn deep quantization from weakly tagged images. Specifically, 1) we use word embeddings to represent the tags and enhance their semantic information based on a tag correlation graph. 2) To better preserve semantic information in quantization codes and reduce quantization error, we jointly learn semantics-preserving embeddings and supervised quantizer on hypersphere by employing a well-designed fusion layer and tailor-made loss functions. Extensive experiments show that WSDHQ can achieve state-of-art performance on weakly-supervised compact coding. Code is available at https://github.com/gimpong/AAAI21-WSDHQ.
Prompting Multi-Modal Tokens to Enhance End-to-End Autonomous Driving Imitation Learning with LLMs
Apr 07, 2024The utilization of Large Language Models (LLMs) within the realm of reinforcement learning, particularly as planners, has garnered a significant degree of attention in recent scholarly literature. However, a substantial proportion of existing research predominantly focuses on planning models for robotics that transmute the outputs derived from perception models into linguistic forms, thus adopting a `pure-language' strategy. In this research, we propose a hybrid End-to-End learning framework for autonomous driving by combining basic driving imitation learning with LLMs based on multi-modality prompt tokens. Instead of simply converting perception results from the separated train model into pure language input, our novelty lies in two aspects. 1) The end-to-end integration of visual and LiDAR sensory input into learnable multi-modality tokens, thereby intrinsically alleviating description bias by separated pre-trained perception models. 2) Instead of directly letting LLMs drive, this paper explores a hybrid setting of letting LLMs help the driving model correct mistakes and complicated scenarios. The results of our experiments suggest that the proposed methodology can attain driving scores of 49.21%, coupled with an impressive route completion rate of 91.34% in the offline evaluation conducted via CARLA. These performance metrics are comparable to the most advanced driving models.
Hierarchical Information Enhancement Network for Cascade Prediction in Social Networks
Mar 22, 2024Understanding information cascades in networks is a fundamental issue in numerous applications. Current researches often sample cascade information into several independent paths or subgraphs to learn a simple cascade representation. However, these approaches fail to exploit the hierarchical semantic associations between different modalities, limiting their predictive performance. In this work, we propose a novel Hierarchical Information Enhancement Network (HIENet) for cascade prediction. Our approach integrates fundamental cascade sequence, user social graphs, and sub-cascade graph into a unified framework. Specifically, HIENet utilizes DeepWalk to sample cascades information into a series of sequences. It then gathers path information between users to extract the social relationships of propagators. Additionally, we employ a time-stamped graph convolutional network to aggregate sub-cascade graph information effectively. Ultimately, we introduce a Multi-modal Cascade Transformer to powerfully fuse these clues, providing a comprehensive understanding of cascading process. Extensive experiments have demonstrated the effectiveness of the proposed method.
Multi-perspective Memory Enhanced Network for Identifying Key Nodes in Social Networks
Mar 22, 2024Identifying key nodes in social networks plays a crucial role in timely blocking false information. Existing key node identification methods usually consider node influence only from the propagation structure perspective and have insufficient generalization ability to unknown scenarios. In this paper, we propose a novel Multi-perspective Memory Enhanced Network (MMEN) for identifying key nodes in social networks, which mines key nodes from multiple perspectives and utilizes memory networks to store historical information. Specifically, MMEN first constructs two propagation networks from the perspectives of user attributes and propagation structure and updates node feature representations using graph attention networks. Meanwhile, the memory network is employed to store information of similar subgraphs, enhancing the model's generalization performance in unknown scenarios. Finally, MMEN applies adaptive weights to combine the node influence of the two propagation networks to select the ultimate key nodes. Extensive experiments demonstrate that our method significantly outperforms previous methods.
TriHelper: Zero-Shot Object Navigation with Dynamic Assistance
Mar 22, 2024Navigating toward specific objects in unknown environments without additional training, known as Zero-Shot object navigation, poses a significant challenge in the field of robotics, which demands high levels of auxiliary information and strategic planning. Traditional works have focused on holistic solutions, overlooking the specific challenges agents encounter during navigation such as collision, low exploration efficiency, and misidentification of targets. To address these challenges, our work proposes TriHelper, a novel framework designed to assist agents dynamically through three primary navigation challenges: collision, exploration, and detection. Specifically, our framework consists of three innovative components: (i) Collision Helper, (ii) Exploration Helper, and (iii) Detection Helper. These components work collaboratively to solve these challenges throughout the navigation process. Experiments on the Habitat-Matterport 3D (HM3D) and Gibson datasets demonstrate that TriHelper significantly outperforms all existing baseline methods in Zero-Shot object navigation, showcasing superior success rates and exploration efficiency. Our ablation studies further underscore the effectiveness of each helper in addressing their respective challenges, notably enhancing the agent's navigation capabilities. By proposing TriHelper, we offer a fresh perspective on advancing the object navigation task, paving the way for future research in the domain of Embodied AI and visual-based navigation.
Decode Neural signal as Speech
Mar 04, 2024
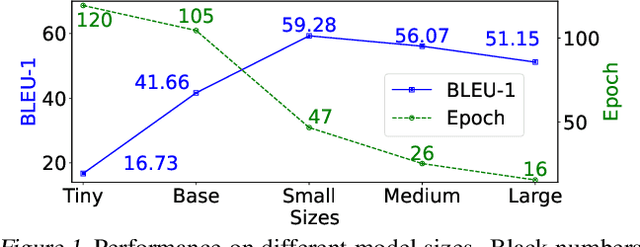


Decoding language from brain dynamics is an important open direction in the realm of brain-computer interface (BCI), especially considering the rapid growth of large language models. Compared to invasive-based signals which require electrode implantation surgery, non-invasive neural signals (e.g. EEG, MEG) have attracted increasing attention considering their safety and generality. However, the exploration is not adequate in three aspects: 1) previous methods mainly focus on EEG but none of the previous works address this problem on MEG with better signal quality; 2) prior works have predominantly used ``teacher-forcing" during generative decoding, which is impractical; 3) prior works are mostly ``BART-based" not fully auto-regressive, which performs better in other sequence tasks. In this paper, we explore the brain-to-text translation of MEG signals in a speech-decoding formation. Here we are the first to investigate a cross-attention-based ``whisper" model for generating text directly from MEG signals without teacher forcing. Our model achieves impressive BLEU-1 scores of 60.30 and 52.89 without pretraining \& teacher-forcing on two major datasets (\textit{GWilliams} and \textit{Schoffelen}). This paper conducts a comprehensive review to understand how speech decoding formation performs on the neural decoding tasks, including pretraining initialization, training \& evaluation set splitting, augmentation, and scaling law.
Whole-body Humanoid Robot Locomotion with Human Reference
Mar 01, 2024Recently, humanoid robots have made significant advances in their ability to perform challenging tasks due to the deployment of Reinforcement Learning (RL), however, the inherent complexity of humanoid robots, including the difficulty of designing complicated reward functions and training entire sophisticated systems, still poses a notable challenge. To conquer these challenges, after many iterations and in-depth investigations, we have meticulously developed a full-size humanoid robot, "Adam", whose innovative structural design greatly improves the efficiency and effectiveness of the imitation learning process. In addition, we have developed a novel imitation learning framework based on an adversarial motion prior, which applies not only to Adam but also to humanoid robots in general. Using the framework, Adam can exhibit unprecedented human-like characteristics in locomotion tasks. Our experimental results demonstrate that the proposed framework enables Adam to achieve human-comparable performance in complex locomotion tasks, marking the first time that human locomotion data has been used for imitation learning in a full-size humanoid robot.