 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQihan Huang
On the Concept Trustworthiness in Concept Bottleneck Models
Mar 21, 2024

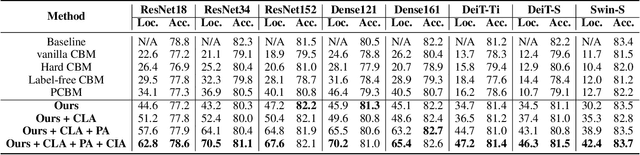
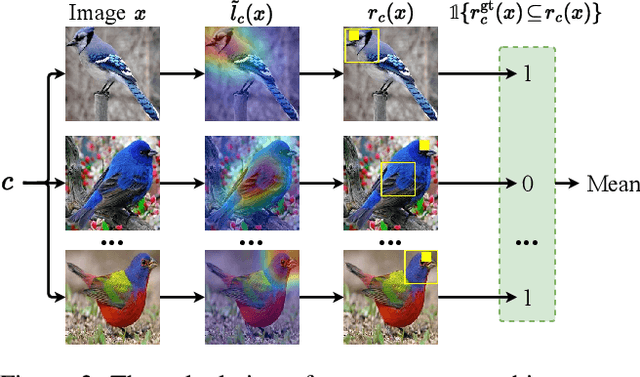

Concept Bottleneck Models (CBMs), which break down the reasoning process into the input-to-concept mapping and the concept-to-label prediction, have garnered significant attention due to their remarkable interpretability achieved by the interpretable concept bottleneck. However, despite the transparency of the concept-to-label prediction, the mapping from the input to the intermediate concept remains a black box, giving rise to concerns about the trustworthiness of the learned concepts (i.e., these concepts may be predicted based on spurious cues). The issue of concept untrustworthiness greatly hampers the interpretability of CBMs, thereby hindering their further advancement. To conduct a comprehensive analysis on this issue, in this study we establish a benchmark to assess the trustworthiness of concepts in CBMs. A pioneering metric, referred to as concept trustworthiness score, is proposed to gauge whether the concepts are derived from relevant regions. Additionally, an enhanced CBM is introduced, enabling concept predictions to be made specifically from distinct parts of the feature map, thereby facilitating the exploration of their related regions. Besides, we introduce three modules, namely the cross-layer alignment (CLA) module, the cross-image alignment (CIA) module, and the prediction alignment (PA) module, to further enhance the concept trustworthiness within the elaborated CBM. The experiments on five datasets across ten architectures demonstrate that without using any concept localization annotations during training, our model improves the concept trustworthiness by a large margin, meanwhile achieving superior accuracy to the state-of-the-arts. Our code is available at https://github.com/hqhQAQ/ProtoCBM.
Is ProtoPNet Really Explainable? Evaluating and Improving the Interpretability of Prototypes
Dec 12, 2022
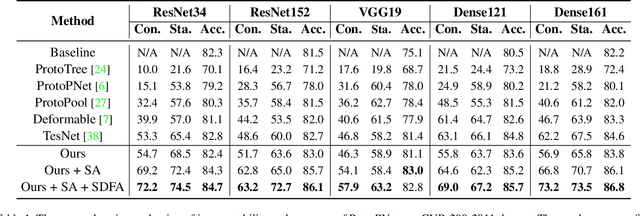
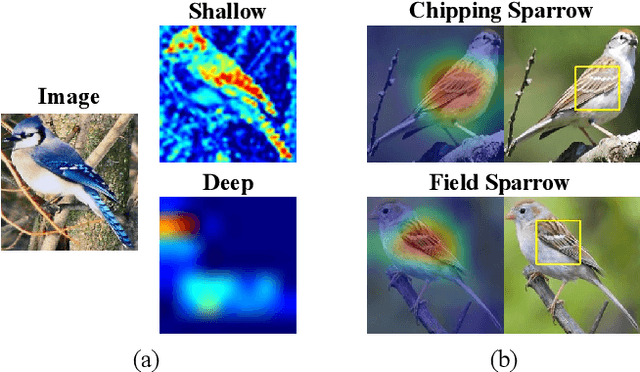
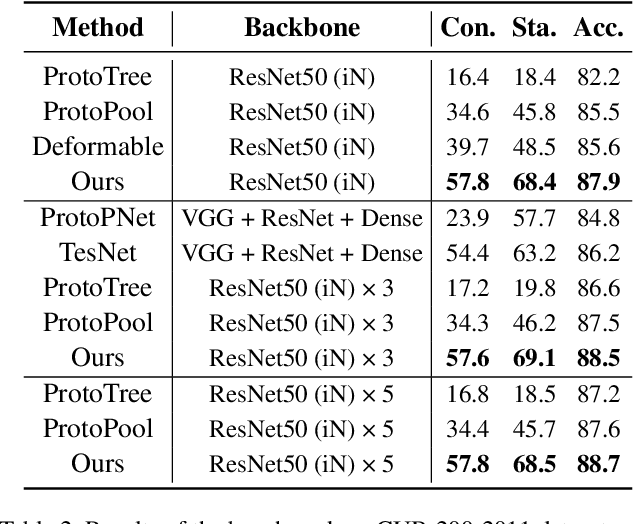
ProtoPNet and its follow-up variants (ProtoPNets) have attracted broad research interest for their intrinsic interpretability from prototypes and comparable accuracy to non-interpretable counterparts. However, it has been recently found that the interpretability of prototypes can be corrupted due to the semantic gap between similarity in latent space and that in input space. In this work, we make the first attempt to quantitatively evaluate the interpretability of prototype-based explanations, rather than solely qualitative evaluations by some visualization examples, which can be easily misled by cherry picks. To this end, we propose two evaluation metrics, termed consistency score and stability score, to evaluate the explanation consistency cross images and the explanation robustness against perturbations, both of which are essential for explanations taken into practice. Furthermore, we propose a shallow-deep feature alignment (SDFA) module and a score aggregation (SA) module to improve the interpretability of prototypes. We conduct systematical evaluation experiments and substantial discussions to uncover the interpretability of existing ProtoPNets. Experiments demonstrate that our method achieves significantly superior performance to the state-of-the-arts, under both the conventional qualitative evaluations and the proposed quantitative evaluations, in both accuracy and interpretability. Codes are available at https://github.com/hqhQAQ/EvalProtoPNet.
ProtoPFormer: Concentrating on Prototypical Parts in Vision Transformers for Interpretable Image Recognition
Aug 22, 2022
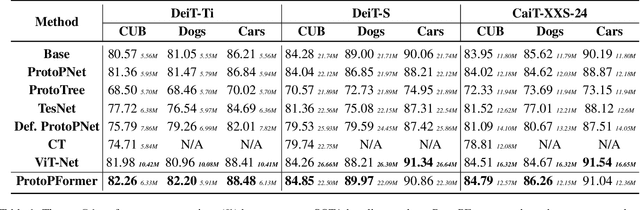

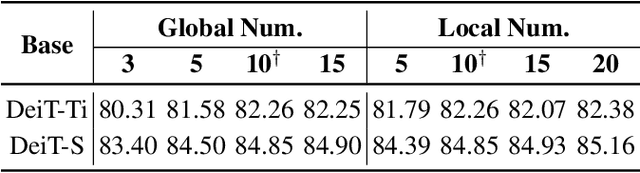
Prototypical part network (ProtoPNet) has drawn wide attention and boosted many follow-up studies due to its self-explanatory property for explainable artificial intelligence (XAI). However, when directly applying ProtoPNet on vision transformer (ViT) backbones, learned prototypes have a ''distraction'' problem: they have a relatively high probability of being activated by the background and pay less attention to the foreground. The powerful capability of modeling long-term dependency makes the transformer-based ProtoPNet hard to focus on prototypical parts, thus severely impairing its inherent interpretability. This paper proposes prototypical part transformer (ProtoPFormer) for appropriately and effectively applying the prototype-based method with ViTs for interpretable image recognition. The proposed method introduces global and local prototypes for capturing and highlighting the representative holistic and partial features of targets according to the architectural characteristics of ViTs. The global prototypes are adopted to provide the global view of objects to guide local prototypes to concentrate on the foreground while eliminating the influence of the background. Afterwards, local prototypes are explicitly supervised to concentrate on their respective prototypical visual parts, increasing the overall interpretability. Extensive experiments demonstrate that our proposed global and local prototypes can mutually correct each other and jointly make final decisions, which faithfully and transparently reason the decision-making processes associatively from the whole and local perspectives, respectively. Moreover, ProtoPFormer consistently achieves superior performance and visualization results over the state-of-the-art (SOTA) prototype-based baselines. Our code has been released at https://github.com/zju-vipa/ProtoPFormer.
A Survey of Deep Learning for Low-Shot Object Detection
Dec 10, 2021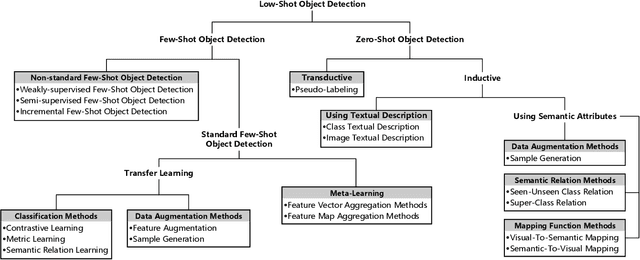



Object detection is a fundamental task in computer vision and image processing. Current deep learning based object detectors have been highly successful with abundant labeled data. But in real life, it is not guaranteed that each object category has enough labeled samples for training. These large object detectors are easy to overfit when the training data is limited. Therefore, it is necessary to introduce few-shot learning and zero-shot learning into object detection, which can be named low-shot object detection together. Low-Shot Object Detection (LSOD) aims to detect objects from a few or even zero labeled data, which can be categorized into few-shot object detection (FSOD) and zero-shot object detection (ZSD), respectively. This paper conducts a comprehensive survey for deep learning based FSOD and ZSD. First, this survey classifies methods for FSOD and ZSD into different categories and discusses the pros and cons of them. Second, this survey reviews dataset settings and evaluation metrics for FSOD and ZSD, then analyzes the performance of different methods on these benchmarks. Finally, this survey discusses future challenges and promising directions for FSOD and ZSD.