 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQing Tian
SKGHOI: Spatial-Semantic Knowledge Graph for Human-Object Interaction Detection
Mar 15, 2023
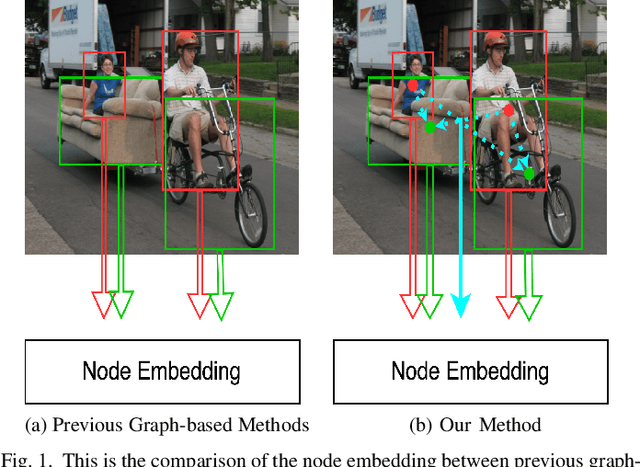
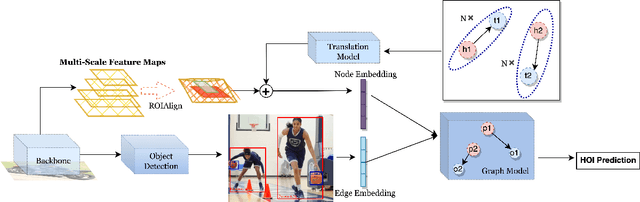
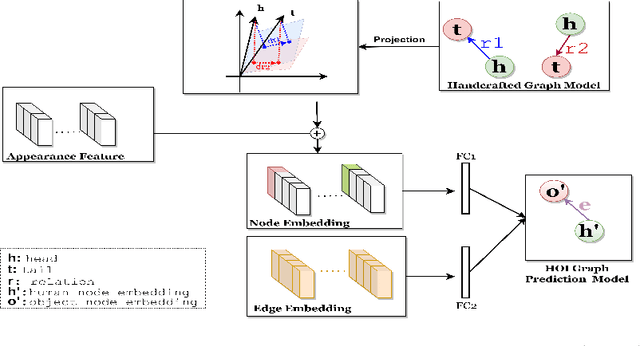
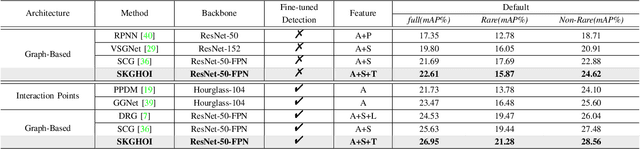
Detecting human-object interactions (HOIs) is a challenging problem in computer vision. Existing techniques for HOI detection heavily rely on appearance-based features, which may not capture other essential characteristics for accurate detection. Furthermore, the use of transformer-based models for sentiment representation of human-object pairs can be computationally expensive. To address these challenges, we propose a novel graph-based approach, SKGHOI (Spatial-Semantic Knowledge Graph for Human-Object Interaction Detection), that effectively captures the sentiment representation of HOIs by integrating both spatial and semantic knowledge. In a graph, SKGHOI takes the components of interaction as nodes, and the spatial relationships between them as edges. Our approach employs a spatial encoder and a semantic encoder to extract spatial and semantic information, respectively, and then combines these encodings to create a knowledge graph that captures the sentiment representation of HOIs. Compared to existing techniques, SKGHOI is computationally efficient and allows for the incorporation of prior knowledge, making it practical for use in real-world applications. We demonstrate the effectiveness of our proposed method on the widely-used HICO-DET datasets, where it outperforms existing state-of-the-art graph-based methods by a significant margin. Our results indicate that the SKGHOI approach has the potential to significantly improve the accuracy and efficiency of HOI detection, and we anticipate that it will be of great interest to researchers and practitioners working on this challenging task.
Gradient-Guided Knowledge Distillation for Object Detectors
Mar 07, 2023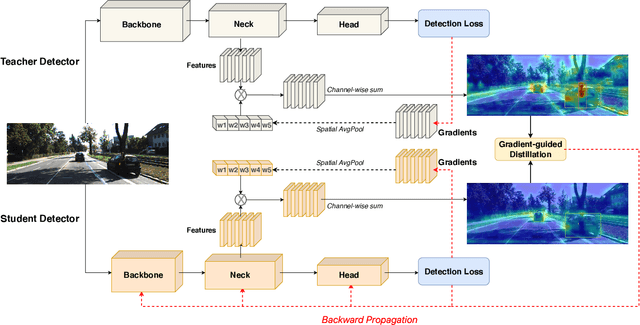
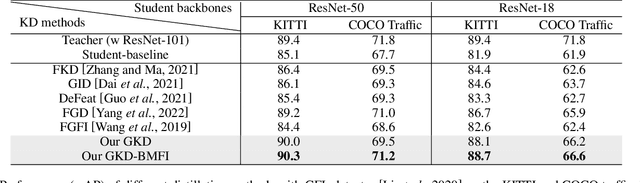

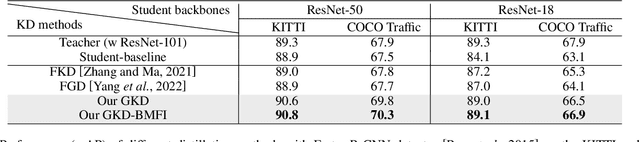
Deep learning models have demonstrated remarkable success in object detection, yet their complexity and computational intensity pose a barrier to deploying them in real-world applications (e.g., self-driving perception). Knowledge Distillation (KD) is an effective way to derive efficient models. However, only a small number of KD methods tackle object detection. Also, most of them focus on mimicking the plain features of the teacher model but rarely consider how the features contribute to the final detection. In this paper, we propose a novel approach for knowledge distillation in object detection, named Gradient-guided Knowledge Distillation (GKD). Our GKD uses gradient information to identify and assign more weights to features that significantly impact the detection loss, allowing the student to learn the most relevant features from the teacher. Furthermore, we present bounding-box-aware multi-grained feature imitation (BMFI) to further improve the KD performance. Experiments on the KITTI and COCO-Traffic datasets demonstrate our method's efficacy in knowledge distillation for object detection. On one-stage and two-stage detectors, our GKD-BMFI leads to an average of 5.1% and 3.8% mAP improvement, respectively, beating various state-of-the-art KD methods.
Visual Saliency-Guided Channel Pruning for Deep Visual Detectors in Autonomous Driving
Mar 04, 2023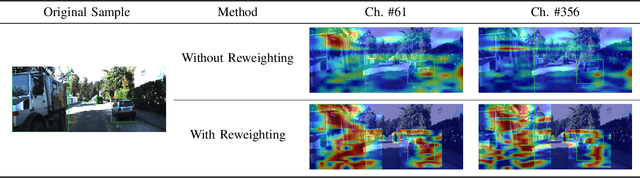
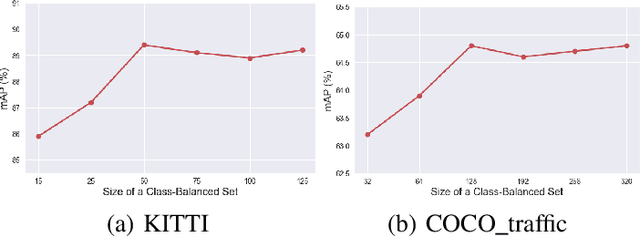


Deep neural network (DNN) pruning has become a de facto component for deploying on resource-constrained devices since it can reduce memory requirements and computation costs during inference. In particular, channel pruning gained more popularity due to its structured nature and direct savings on general hardware. However, most existing pruning approaches utilize importance measures that are not directly related to the task utility. Moreover, few in the literature focus on visual detection models. To fill these gaps, we propose a novel gradient-based saliency measure for visual detection and use it to guide our channel pruning. Experiments on the KITTI and COCO traffic datasets demonstrate our pruning method's efficacy and superiority over state-of-the-art competing approaches. It can even achieve better performance with fewer parameters than the original model. Our pruning also demonstrates great potential in handling small-scale objects.
Comparison Of Deep Object Detectors On A New Vulnerable Pedestrian Dataset
Dec 12, 2022

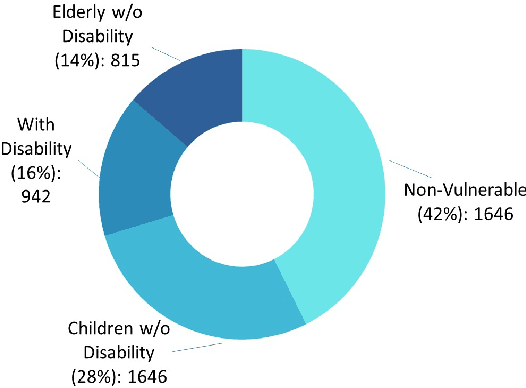
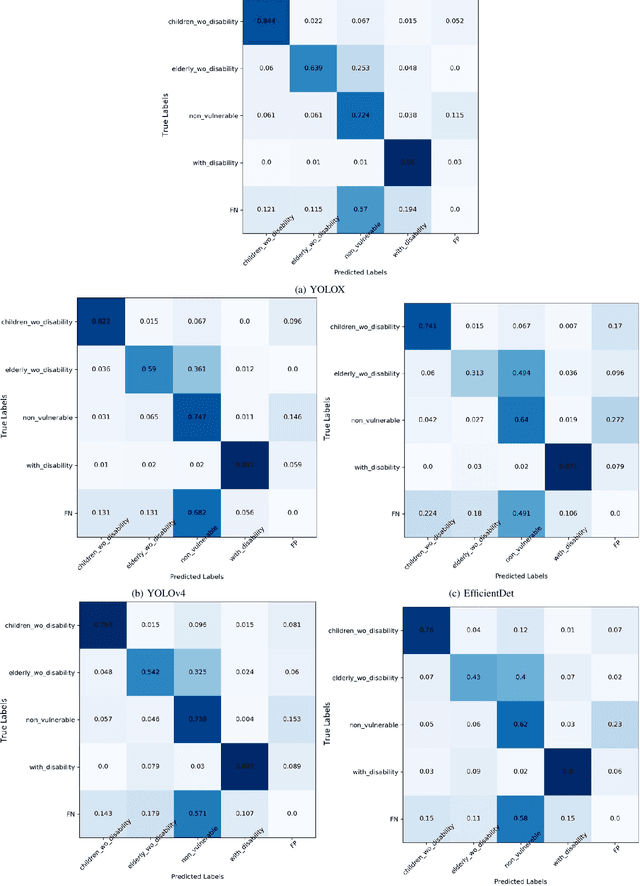
Pedestrian safety is one primary concern in autonomous driving. The under-representation of vulnerable groups in today's pedestrian datasets points to an urgent need for a dataset of vulnerable road users. In this paper, we first introduce a new vulnerable pedestrian detection dataset, BG Vulnerable Pedestrian (BGVP) dataset to help train well-rounded models and thus induce research to increase the efficacy of vulnerable pedestrian detection. The dataset includes four classes, i.e., Children Without Disability, Elderly without Disability, With Disability, and Non-Vulnerable. This dataset consists of images collected from the public domain and manually-annotated bounding boxes. In addition, on the proposed dataset, we have trained and tested five state-of-the-art object detection models, i.e., YOLOv4, YOLOv5, YOLOX, Faster R-CNN, and EfficientDet. Our results indicate that YOLOX and YOLOv4 perform the best on our dataset, YOLOv4 scoring 0.7999 and YOLOX scoring 0.7779 on the mAP 0.5 metric, while YOLOX outperforms YOLOv4 by 3.8 percent on the mAP 0.5:0.95 metric. Generally speaking, all five detectors do well predicting the With Disability class and perform poorly in the Elderly Without Disability class. YOLOX consistently outperforms all other detectors on the mAP (0.5:0.95) per class metric, obtaining 0.5644, 0.5242, 0.4781, and 0.6796 for Children Without Disability, Elderly Without Disability, Non-vulnerable, and With Disability, respectively. Our dataset and codes are available at https://github.com/devvansh1997/BGVP.
Towards Greener Solutions for Steering Angle Prediction
Nov 21, 2022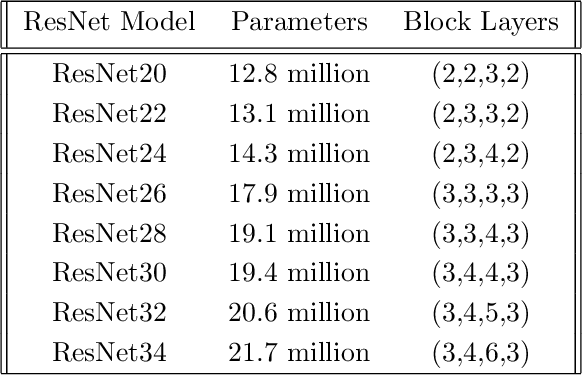
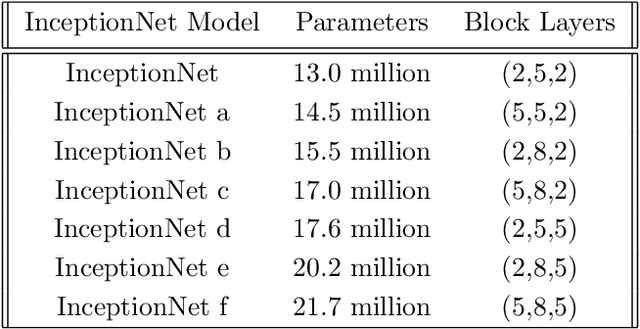
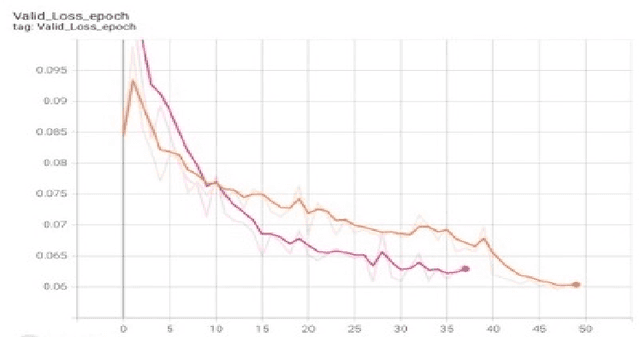

In this paper, we investigate the two most popular families of deep neural architectures (i.e., ResNets and Inception nets) for the autonomous driving task of steering angle prediction. This work provides preliminary evidence that Inception architectures can perform as well or better than ResNet architectures with less complexity for the autonomous driving task. Primary motivation includes support for further research in smaller, more efficient neural network architectures such that can not only accomplish complex tasks, such as steering angle predictions, but also produce less carbon emissions, or, more succinctly, neural networks that are more environmentally friendly. We look at various sizes of ResNet and InceptionNet models to compare results. Our derived models can achieve state-of-the-art results in terms of steering angle MSE.
Multi-view information fusion using multi-view variational autoencoders to predict proximal femoral strength
Oct 03, 2022
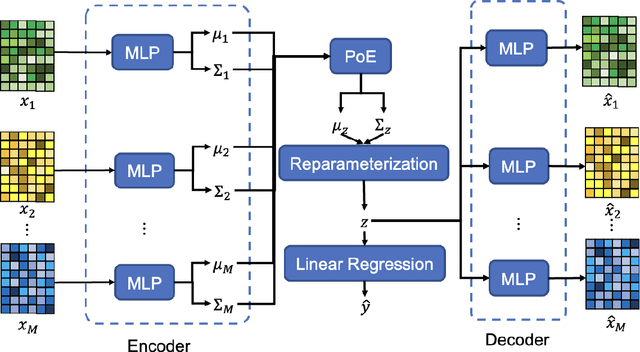
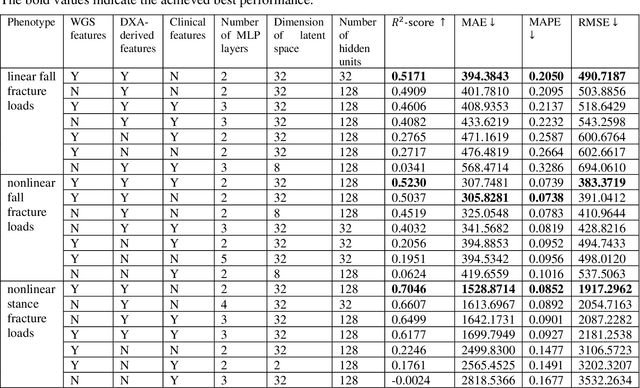
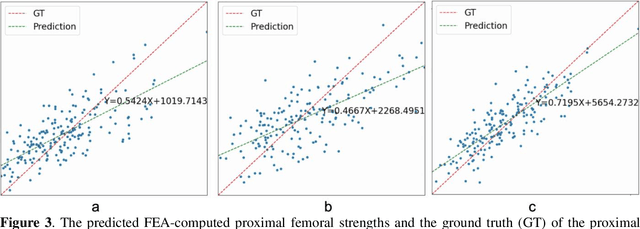
Background and aim: Hip fracture can be devastating. The proximal femoral strength can be computed by subject-specific finite element (FE) analysis (FEA) using quantitative CT images. The aim of this paper is to design a deep learning-based model for hip fracture prediction with multi-view information fusion. Method: We developed a multi-view variational autoencoder (MMVAE) for feature representation learning and designed the product of expert model (PoE) for multi-view information fusion.We performed genome-wide association studies (GWAS) to select the most relevant genetic features with proximal femoral strengths and integrated genetic features with DXA-derived imaging features and clinical variables for proximal femoral strength prediction. Results: The designed model achieved the mean absolute percentage error of 0.2050,0.0739 and 0.0852 for linear fall, nonlinear fall and nonlinear stance fracture load prediction, respectively. For linear fall and nonlinear stance fracture load prediction, integrating genetic and DXA-derived imaging features were beneficial; while for nonlinear fall fracture load prediction, integrating genetic features, DXA-derived imaging features as well as clinical variables, the model achieved the best performance. Conclusion: The proposed model is capable of predicting proximal femoral strengths using genetic features, DXA-derived imaging features as well as clinical variables. Compared to performing FEA using QCT images to calculate proximal femoral strengths, the presented method is time-efficient and cost effective, and radiation dosage is limited. From the technique perspective, the final models can be applied to other multi-view information integration tasks.
Adversarial Attack and Defense of YOLO Detectors in Autonomous Driving Scenarios
Feb 10, 2022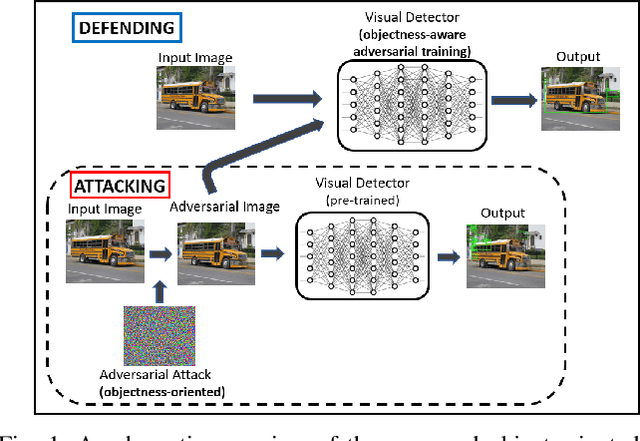
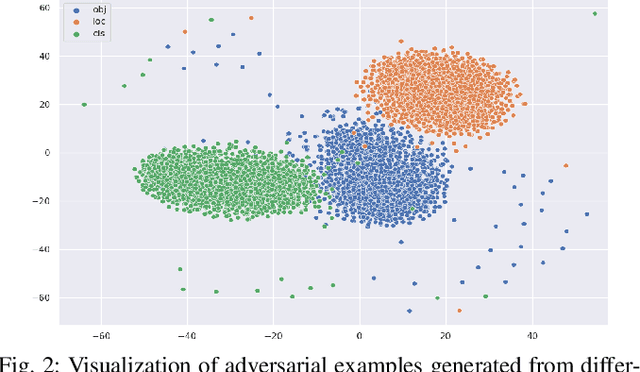


Visual detection is a key task in autonomous driving, and it serves as one foundation for self-driving planning and control. Deep neural networks have achieved promising results in various computer vision tasks, but they are known to be vulnerable to adversarial attacks. A comprehensive understanding of deep visual detectors' vulnerability is required before people can improve their robustness. However, only a few adversarial attack/defense works have focused on object detection, and most of them employed only classification and/or localization losses, ignoring the objectness aspect. In this paper, we identify a serious objectness-related adversarial vulnerability in YOLO detectors and present an effective attack strategy aiming the objectness aspect of visual detection in autonomous vehicles. Furthermore, to address such vulnerability, we propose a new objectness-aware adversarial training approach for visual detection. Experiments show that the proposed attack targeting the objectness aspect is 45.17% and 43.50% more effective than those generated from classification and/or localization losses on the KITTI and COCO_traffic datasets, respectively. Also, the proposed adversarial defense approach can improve the detectors' robustness against objectness-oriented attacks by up to 21% and 12% mAP on KITTI and COCO_traffic, respectively.
Adaptive Instance Distillation for Object Detection in Autonomous Driving
Jan 26, 2022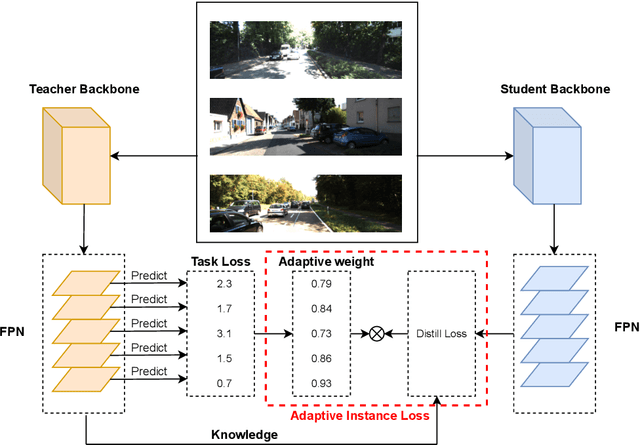


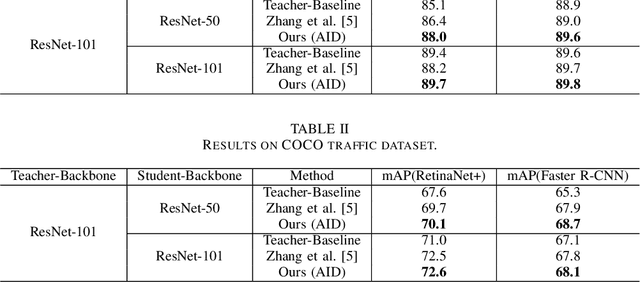
In recent years, knowledge distillation (KD) has been widely used as an effective way to derive efficient models. Through imitating a large teacher model, a lightweight student model can achieve comparable performance with more efficiency. However, most existing knowledge distillation methods are focused on classification tasks. Only a limited number of studies have applied knowledge distillation to object detection, especially in time-sensitive autonomous driving scenarios. We propose the Adaptive Instance Distillation (AID) method to selectively impart knowledge from the teacher to the student for improving the performance of knowledge distillation. Unlike previous KD methods that treat all instances equally, our AID can attentively adjust the distillation weights of instances based on the teacher model's prediction loss. We verified the effectiveness of our AID method through experiments on the KITTI and the COCO traffic datasets. The results show that our method improves the performance of existing state-of-the-art attention-guided and non-local distillation methods and achieves better distillation results on both single-stage and two-stage detectors. Compared to the baseline, our AID led to an average of 2.7% and 2.05% mAP increases for single-stage and two-stage detectors, respectively. Furthermore, our AID is also shown to be useful for self-distillation to improve the teacher model's performance.
Improving Apparel Detection with Category Grouping and Multi-grained Branches
Jan 17, 2021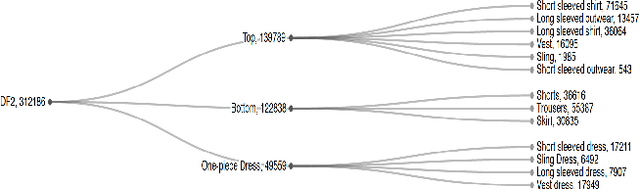
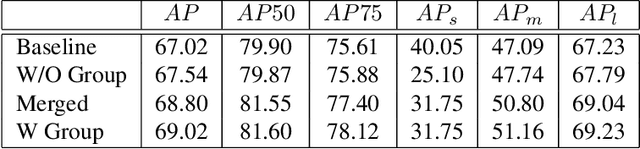
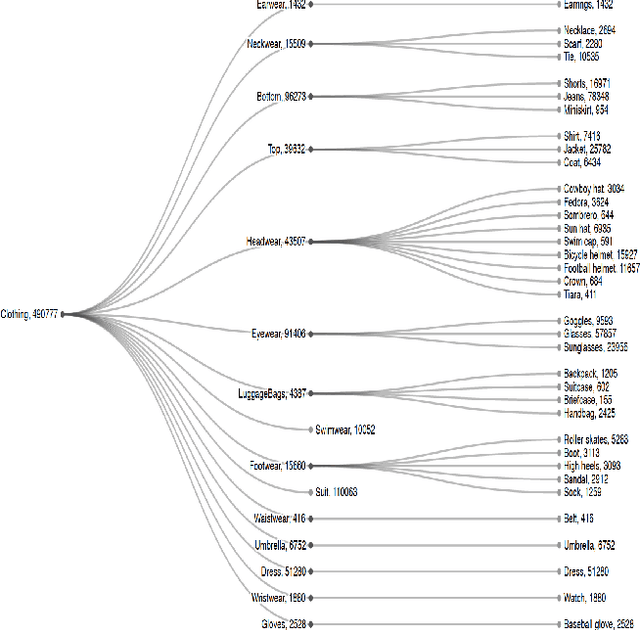
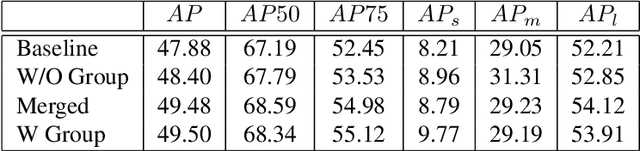
Training an accurate object detector is expensive and time-consuming. One main reason lies in the laborious labeling process, i.e., annotating category and bounding box information for all instances in every image. In this paper, we examine ways to improve performance of deep object detectors without extra labeling. We first explore to group existing categories of high visual and semantic similarities together as one super category (or, a superclass). Then, we study how this knowledge of hierarchical categories can be exploited to better detect object using multi-grained RCNN top branches. Experimental results on DeepFashion2 and OpenImagesV4-Clothing reveal that the proposed detection heads with multi-grained branches can boost the overall performance by 2.3 mAP for DeepFashion2 and 2.5 mAP for OpenImagesV4-Clothing with no additional time-consuming annotations. More importantly, classes that have fewer training samples tend to benefit more from the proposed multi-grained heads with superclass grouping. In particular, we improve the mAP for last 30% categories (in terms of training sample number) by 2.6 and 4.6 for DeepFashion2 and OpenImagesV4-Clothing, respectively.
Deep discriminant analysis for task-dependent compact network search
Sep 29, 2020
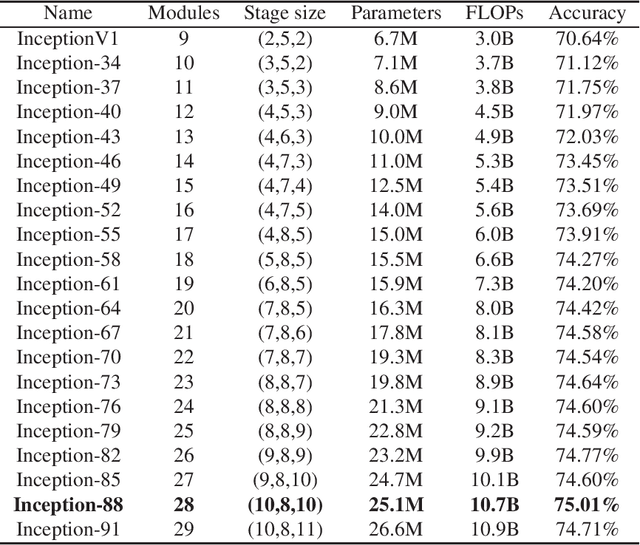
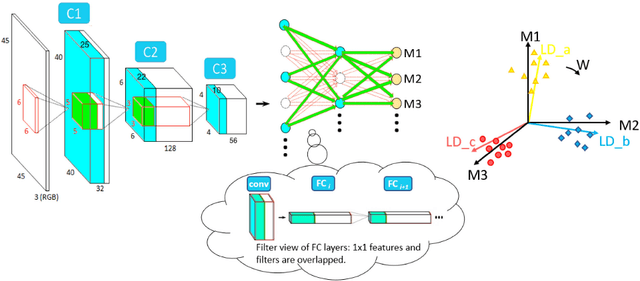
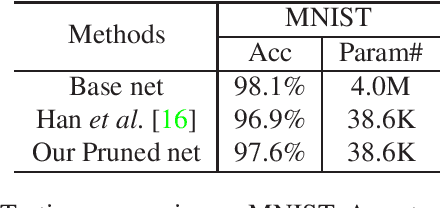
Most of today's popular deep architectures are hand-engineered for general purpose applications. However, this design procedure usually leads to massive redundant, useless, or even harmful features for specific tasks. Such unnecessarily high complexities render deep nets impractical for many real-world applications, especially those without powerful GPU support. In this paper, we attempt to derive task-dependent compact models from a deep discriminant analysis perspective. We propose an iterative and proactive approach for classification tasks which alternates between (1) a pushing step, with an objective to simultaneously maximize class separation, penalize co-variances, and push deep discriminants into alignment with a compact set of neurons, and (2) a pruning step, which discards less useful or even interfering neurons. Deconvolution is adopted to reverse `unimportant' filters' effects and recover useful contributing sources. A simple network growing strategy based on the basic Inception module is proposed for challenging tasks requiring larger capacity than what the base net can offer. Experiments on the MNIST, CIFAR10, and ImageNet datasets demonstrate our approach's efficacy. On ImageNet, by pushing and pruning our grown Inception-88 model, we achieve better-performing models than smaller deep Inception nets grown, residual nets, and famous compact nets at similar sizes. We also show that our grown deep Inception nets (without hard-coded dimension alignment) can beat residual nets of similar complexities.