 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQingbin Liu
Can We Edit Multimodal Large Language Models?
Oct 13, 2023
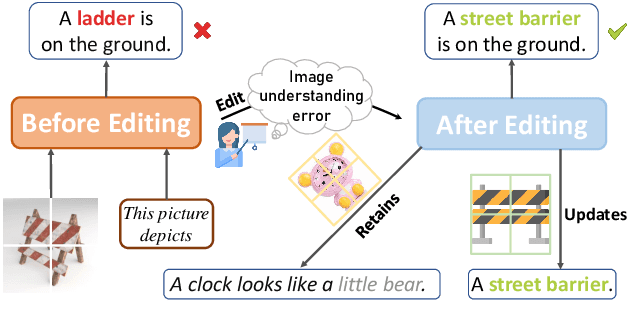
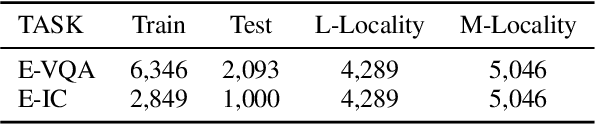
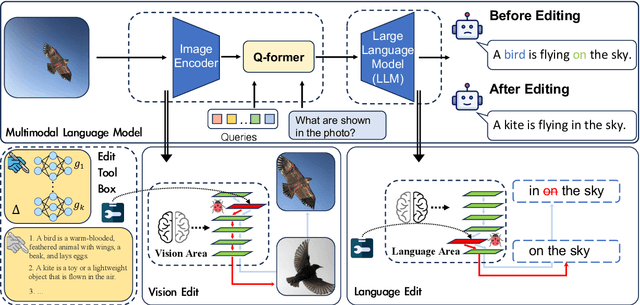

In this paper, we focus on editing Multimodal Large Language Models (MLLMs). Compared to editing single-modal LLMs, multimodal model editing is more challenging, which demands a higher level of scrutiny and careful consideration in the editing process. To facilitate research in this area, we construct a new benchmark, dubbed MMEdit, for editing multimodal LLMs and establishing a suite of innovative metrics for evaluation. We conduct comprehensive experiments involving various model editing baselines and analyze the impact of editing different components for multimodal LLMs. Empirically, we notice that previous baselines can implement editing multimodal LLMs to some extent, but the effect is still barely satisfactory, indicating the potential difficulty of this task. We hope that our work can provide the NLP community with insights. Code and dataset are available in https://github.com/zjunlp/EasyEdit.
Knowledge-augmented Few-shot Visual Relation Detection
Mar 09, 2023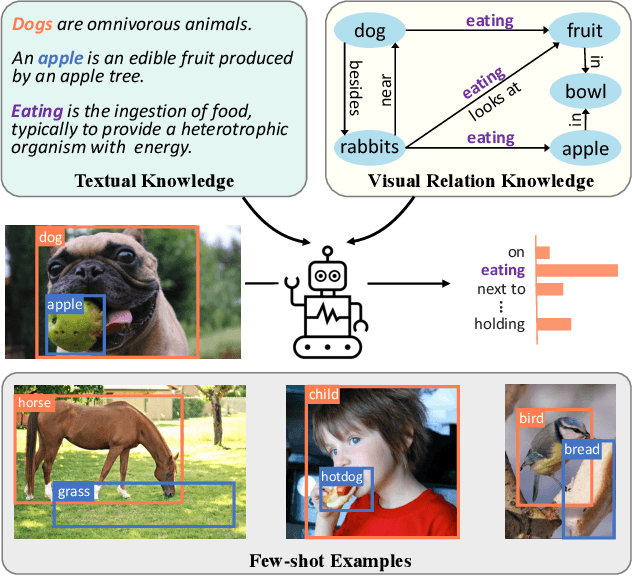

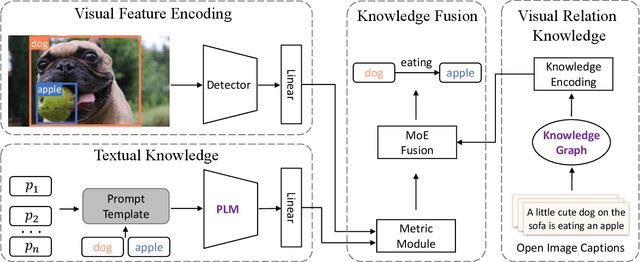
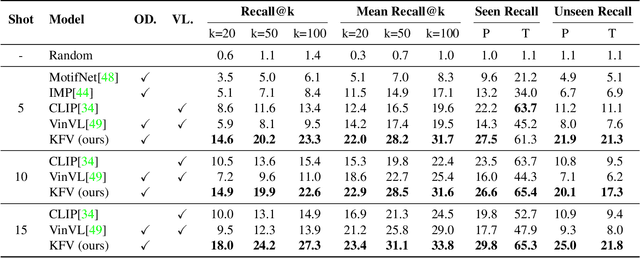
Visual Relation Detection (VRD) aims to detect relationships between objects for image understanding. Most existing VRD methods rely on thousands of training samples of each relationship to achieve satisfactory performance. Some recent papers tackle this problem by few-shot learning with elaborately designed pipelines and pre-trained word vectors. However, the performance of existing few-shot VRD models is severely hampered by the poor generalization capability, as they struggle to handle the vast semantic diversity of visual relationships. Nonetheless, humans have the ability to learn new relationships with just few examples based on their knowledge. Inspired by this, we devise a knowledge-augmented, few-shot VRD framework leveraging both textual knowledge and visual relation knowledge to improve the generalization ability of few-shot VRD. The textual knowledge and visual relation knowledge are acquired from a pre-trained language model and an automatically constructed visual relation knowledge graph, respectively. We extensively validate the effectiveness of our framework. Experiments conducted on three benchmarks from the commonly used Visual Genome dataset show that our performance surpasses existing state-of-the-art models with a large improvement.
Lifelong Intent Detection via Multi-Strategy Rebalancing
Aug 10, 2021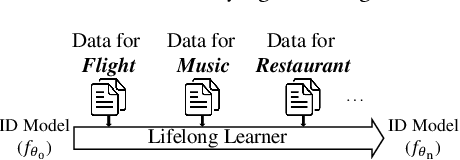
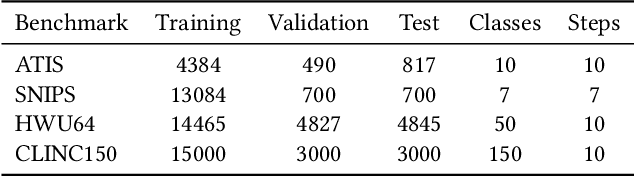
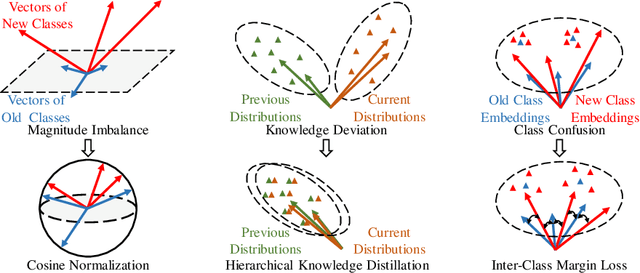
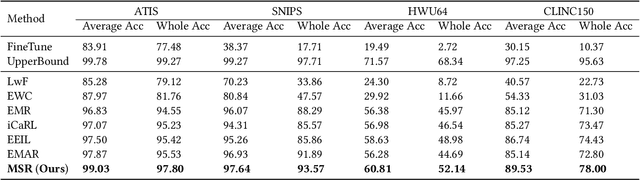
Conventional Intent Detection (ID) models are usually trained offline, which relies on a fixed dataset and a predefined set of intent classes. However, in real-world applications, online systems usually involve continually emerging new user intents, which pose a great challenge to the offline training paradigm. Recently, lifelong learning has received increasing attention and is considered to be the most promising solution to this challenge. In this paper, we propose Lifelong Intent Detection (LID), which continually trains an ID model on new data to learn newly emerging intents while avoiding catastrophically forgetting old data. Nevertheless, we find that existing lifelong learning methods usually suffer from a serious imbalance between old and new data in the LID task. Therefore, we propose a novel lifelong learning method, Multi-Strategy Rebalancing (MSR), which consists of cosine normalization, hierarchical knowledge distillation, and inter-class margin loss to alleviate the multiple negative effects of the imbalance problem. Experimental results demonstrate the effectiveness of our method, which significantly outperforms previous state-of-the-art lifelong learning methods on the ATIS, SNIPS, HWU64, and CLINC150 benchmarks.
Copy-Enhanced Heterogeneous Information Learning for Dialogue State Tracking
Aug 21, 2019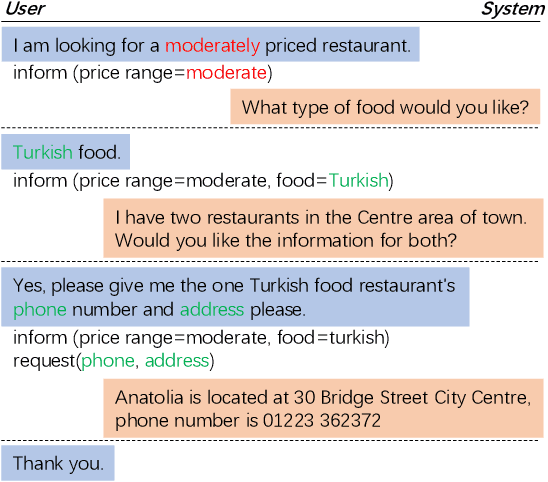
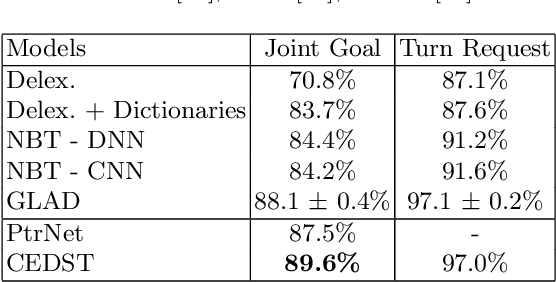
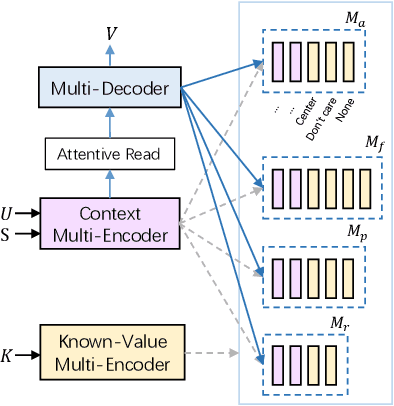
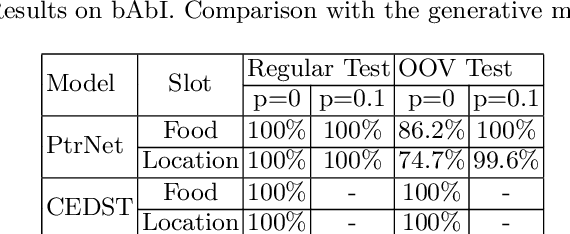
Dialogue state tracking (DST) is an essential component in task-oriented dialogue systems, which estimates user goals at every dialogue turn. However, most previous approaches usually suffer from the following problems. Many discriminative models, especially end-to-end (E2E) models, are difficult to extract unknown values that are not in the candidate ontology; previous generative models, which can extract unknown values from utterances, degrade the performance due to ignoring the semantic information of pre-defined ontology. Besides, previous generative models usually need a hand-crafted list to normalize the generated values. How to integrate the semantic information of pre-defined ontology and dialogue text (heterogeneous texts) to generate unknown values and improve performance becomes a severe challenge. In this paper, we propose a Copy-Enhanced Heterogeneous Information Learning model with multiple encoder-decoder for DST (CEDST), which can effectively generate all possible values including unknown values by copying values from heterogeneous texts. Meanwhile, CEDST can effectively decompose the large state space into several small state spaces through multi-encoder, and employ multi-decoder to make full use of the reduced spaces to generate values. Multi-encoder-decoder architecture can significantly improve performance. Experiments show that CEDST can achieve state-of-the-art results on two datasets and our constructed datasets with many unknown values.