 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiuyu Zhu
Multi-stage feature decorrelation constraints for improving CNN classification performance
Aug 24, 2023

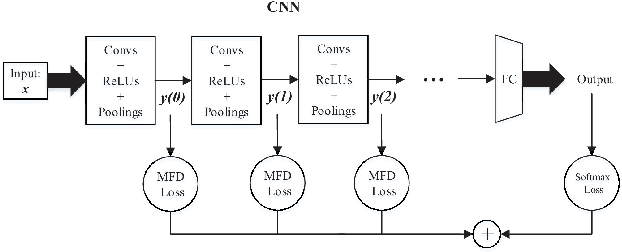
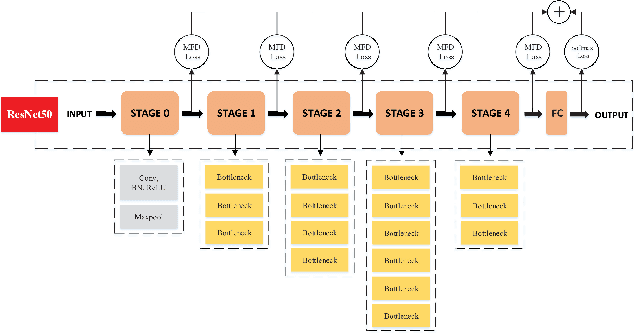

For the convolutional neural network (CNN) used for pattern classification, the training loss function is usually applied to the final output of the network, except for some regularization constraints on the network parameters. However, with the increasing of the number of network layers, the influence of the loss function on the network front layers gradually decreases, and the network parameters tend to fall into local optimization. At the same time, it is found that the trained network has significant information redundancy at all stages of features, which reduces the effectiveness of feature mapping at all stages and is not conducive to the change of the subsequent parameters of the network in the direction of optimality. Therefore, it is possible to obtain a more optimized solution of the network and further improve the classification accuracy of the network by designing a loss function for restraining the front stage features and eliminating the information redundancy of the front stage features .For CNN, this article proposes a multi-stage feature decorrelation loss (MFD Loss), which refines effective features and eliminates information redundancy by constraining the correlation of features at all stages. Considering that there are many layers in CNN, through experimental comparison and analysis, MFD Loss acts on multiple front layers of CNN, constrains the output features of each layer and each channel, and performs supervision training jointly with classification loss function during network training. Compared with the single Softmax Loss supervised learning, the experiments on several commonly used datasets on several typical CNNs prove that the classification performance of Softmax Loss+MFD Loss is significantly better. Meanwhile, the comparison experiments before and after the combination of MFD Loss and some other typical loss functions verify its good universality.
Effective Out-of-Distribution Detection in Classifier Based on PEDCC-Loss
Apr 10, 2022
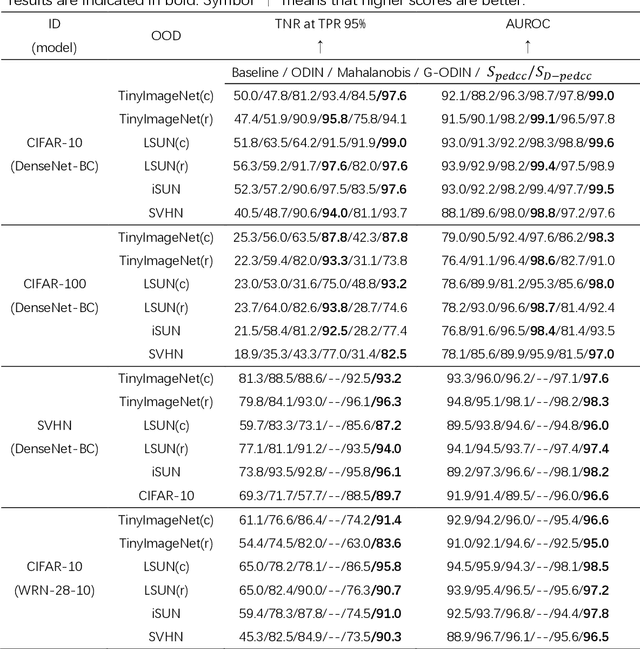


Deep neural networks suffer from the overconfidence issue in the open world, meaning that classifiers could yield confident, incorrect predictions for out-of-distribution (OOD) samples. Thus, it is an urgent and challenging task to detect these samples drawn far away from training distribution based on the security considerations of artificial intelligence. Many current methods based on neural networks mainly rely on complex processing strategies, such as temperature scaling and input preprocessing, to obtain satisfactory results. In this paper, we propose an effective algorithm for detecting out-of-distribution examples utilizing PEDCC-Loss. We mathematically analyze the nature of the confidence score output by the PEDCC (Predefined Evenly-Distribution Class Centroids) classifier, and then construct a more effective scoring function to distinguish in-distribution (ID) and out-of-distribution. In this method, there is no need to preprocess the input samples and the computational burden of the algorithm is reduced. Experiments demonstrate that our method can achieve better OOD detection performance.
A Softmax-free Loss Function Based on Predefined Optimal-distribution of Latent Features for CNN Classifier
Nov 25, 2021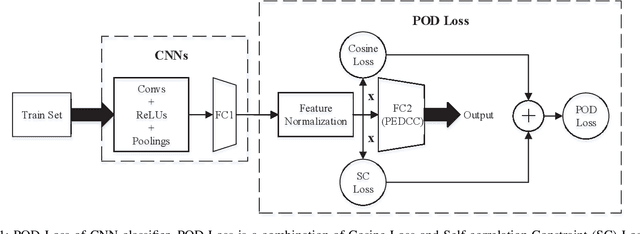
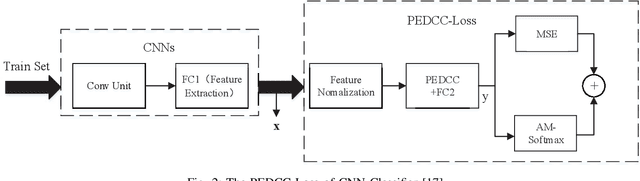
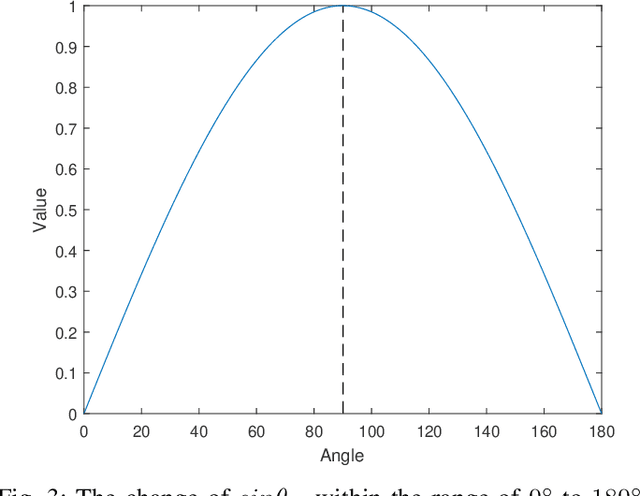
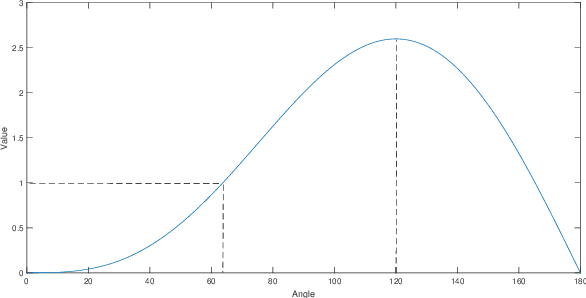
In the field of pattern classification, the training of convolutional neural network classifiers is mostly end-to-end learning, and the loss function is the constraint on the final output (posterior probability) of the network, so the existence of Softmax is essential. In the case of end-to-end learning, there is usually no effective loss function that completely relies on the features of the middle layer to restrict learning, resulting in the distribution of sample latent features is not optimal, so there is still room for improvement in classification accuracy. Based on the concept of Predefined Evenly-Distributed Class Centroids (PEDCC), this article proposes a Softmax-free loss function (POD Loss) based on predefined optimal-distribution of latent features. The loss function only restricts the latent features of the samples, including the cosine distance between the latent feature vector of the sample and the center of the predefined evenly-distributed class, and the correlation between the latent features of the samples. Finally, cosine distance is used for classification. Compared with the commonly used Softmax Loss and the typical Softmax related AM-Softmax Loss, COT-Loss and PEDCC-Loss, experiments on several commonly used datasets on a typical network show that the classification performance of POD Loss is always better and easier to converge. Code is available in https://github.com/TianYuZu/POD-Loss.
Single Underwater Image Enhancement Using an Analysis-Synthesis Network
Aug 20, 2021



Most deep models for underwater image enhancement resort to training on synthetic datasets based on underwater image formation models. Although promising performances have been achieved, they are still limited by two problems: (1) existing underwater image synthesis models have an intrinsic limitation, in which the homogeneous ambient light is usually randomly generated and many important dependencies are ignored, and thus the synthesized training data cannot adequately express characteristics of real underwater environments; (2) most of deep models disregard lots of favorable underwater priors and heavily rely on training data, which extensively limits their application ranges. To address these limitations, a new underwater synthetic dataset is first established, in which a revised ambient light synthesis equation is embedded. The revised equation explicitly defines the complex mathematical relationship among intensity values of the ambient light in RGB channels and many dependencies such as surface-object depth, water types, etc, which helps to better simulate real underwater scene appearances. Secondly, a unified framework is proposed, named ANA-SYN, which can effectively enhance underwater images under collaborations of priors (underwater domain knowledge) and data information (underwater distortion distribution). The proposed framework includes an analysis network and a synthesis network, one for priors exploration and another for priors integration. To exploit more accurate priors, the significance of each prior for the input image is explored in the analysis network and an adaptive weighting module is designed to dynamically recalibrate them. Meanwhile, a novel prior guidance module is introduced in the synthesis network, which effectively aggregates the prior and data features and thus provides better hybrid information to perform the more reasonable image enhancement.
Generation and frame characteristics of predefined evenly-distributed class centroids for pattern classification
May 02, 2021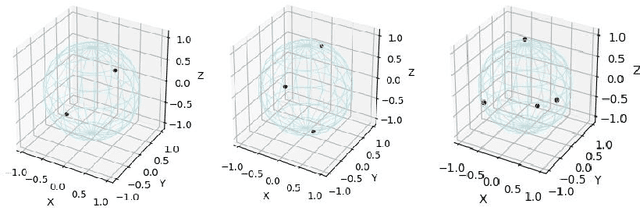
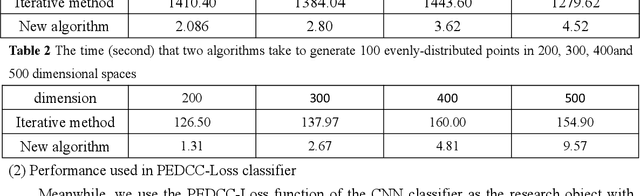
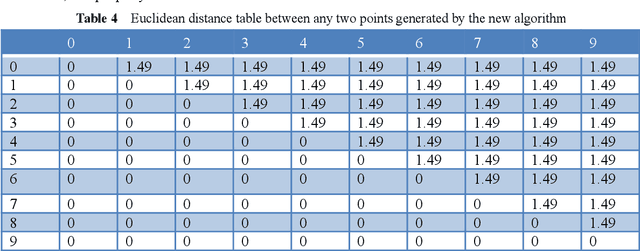

Predefined evenly-distributed class centroids (PEDCC) can be widely used in models and algorithms of pattern classification, such as CNN classifiers, classification autoencoders, clustering, and semi-supervised learning, etc. Its basic idea is to predefine the class centers, which are evenly-distributed on the unit hypersphere in feature space, to maximize the inter-class distance. The previous method of generating PEDCC uses an iterative algorithm based on a charge model, that is, the initial values of various centers (charge positions) are randomly set from the normal distribution, and the charge positions are updated iteratively with the help of the repulsive force between charges of the same polarity. The class centers generated by the algorithm will produce some errors with the theoretically evenly-distributed points, and the generation time will be longer. This paper takes advantage of regular polyhedron in high-dimensional space and the evenly distribution of points on the n dimensional hypersphere to generate PEDCC mathematically. Then, we discussed the basic and extensive characteristics of the frames formed by PEDCC. Finally, experiments show that new algorithm is not only faster than the iterative method, but also more accurate in position. The mathematical analysis and experimental results of this paper can provide a theoretical tool for using PEDCC to solve the key problems in the field of pattern recognition, such as interpretable supervised/unsupervised learning, incremental learning, uncertainty analysis and so on.
Risk-Constrained Thompson Sampling for CVaR Bandits
Nov 17, 2020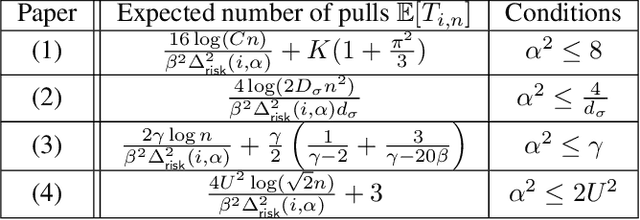



The multi-armed bandit (MAB) problem is a ubiquitous decision-making problem that exemplifies the exploration-exploitation tradeoff. Standard formulations exclude risk in decision making. Risk notably complicates the basic reward-maximising objective, in part because there is no universally agreed definition of it. In this paper, we consider a popular risk measure in quantitative finance known as the Conditional Value at Risk (CVaR). We explore the performance of a Thompson Sampling-based algorithm CVaR-TS under this risk measure. We provide comprehensive comparisons between our regret bounds with state-of-the-art L/UCB-based algorithms in comparable settings and demonstrate their clear improvement in performance. We also include numerical simulations to empirically verify that CVaR-TS outperforms other L/UCB-based algorithms.
Thompson Sampling Algorithms for Mean-Variance Bandits
Feb 01, 2020
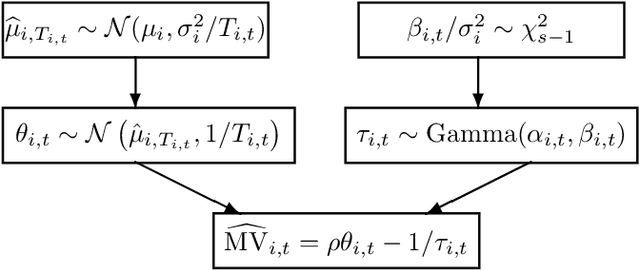
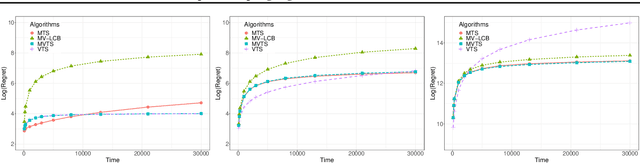
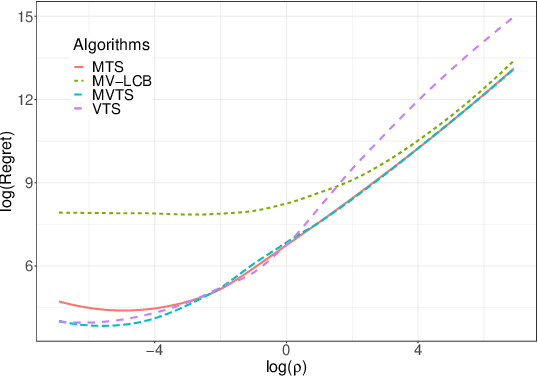
The multi-armed bandit (MAB) problem is a classical learning task that exemplifies the exploration-exploitation tradeoff. However, standard formulations do not take into account risk. In online decision making systems, risk is a primary concern. In this regard, the mean-variance risk measure is one of the most common objective functions. Existing algorithms for mean-variance optimization in the context of MAB problems have unrealistic assumptions on the reward distributions. We develop Thompson Sampling-style algorithms for mean-variance MAB and provide comprehensive regret analyses for Gaussian and Bernoulli bandits with fewer assumptions. Our algorithms achieve the best known regret bounds for mean-variance MABs and also attain the information-theoretic bounds in some parameter regimes. Empirical simulations show that our algorithms significantly outperform existing LCB-based algorithms for all risk tolerances.
Semi-supervised learning method based on predefined evenly-distributed class centroids
Jan 13, 2020
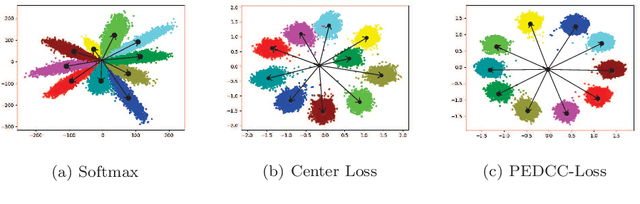

Compared to supervised learning, semi-supervised learning reduces the dependence of deep learning on a large number of labeled samples. In this work, we use a small number of labeled samples and perform data augmentation on unlabeled samples to achieve image classification. Our method constrains all samples to the predefined evenly-distributed class centroids (PEDCC) by the corresponding loss function. Specifically, the PEDCC-Loss for labeled samples, and the maximum mean discrepancy loss for unlabeled samples are used to make the feature distribution closer to the distribution of PEDCC. Our method ensures that the inter-class distance is large and the intra-class distance is small enough to make the classification boundaries between different classes clearer. Meanwhile, for unlabeled samples, we also use KL divergence to constrain the consistency of the network predictions between unlabeled and augmented samples. Our semi-supervised learning method achieves the state-of-the-art results, with 4000 labeled samples on CIFAR10 and 1000 labeled samples on SVHN, and the accuracy is 95.10% and 97.58% respectively.
Incremental Classifier Learning Based on PEDCC-Loss and Cosine Distance
Jun 11, 2019
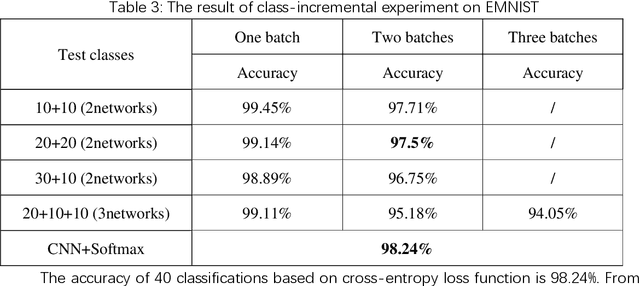
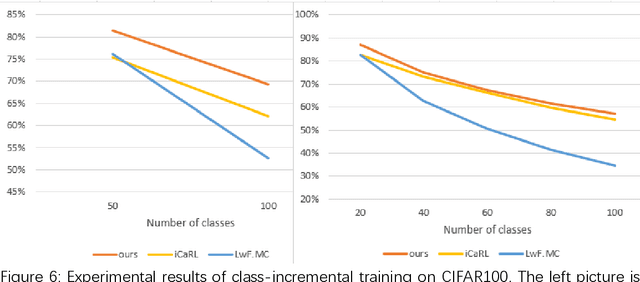
The main purpose of incremental learning is to learn new knowledge while not forgetting the knowledge which have been learned before. At present, the main challenge in this area is the catastrophe forgetting, namely the network will lose their performance in the old tasks after training for new tasks. In this paper, we introduce an ensemble method of incremental classifier to alleviate this problem, which is based on the cosine distance between the output feature and the pre-defined center, and can let each task to be preserved in different networks. During training, we make use of PEDCC-Loss to train the CNN network. In the stage of testing, the prediction is determined by the cosine distance between the network latent features and pre-defined center. The experimental results on EMINST and CIFAR100 show that our method outperforms the recent LwF method, which use the knowledge distillation, and iCaRL method, which keep some old samples while training for new task. The method can achieve the goal of not forgetting old knowledge while training new classes, and solve the problem of catastrophic forgetting better.
An Image Clustering Auto-Encoder Based on Predefined Evenly-Distributed Class Centroids and MMD Distance
Jun 10, 2019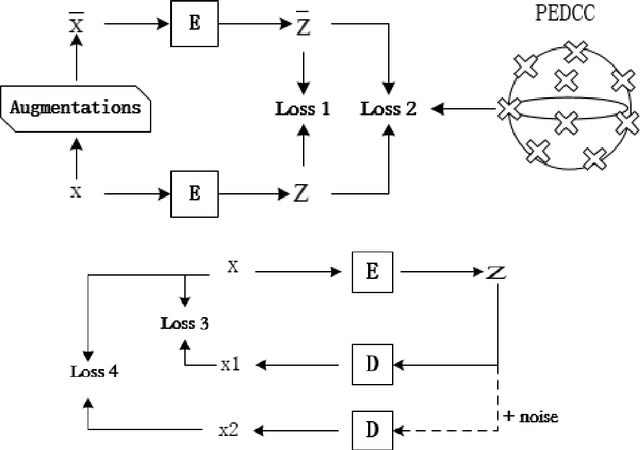
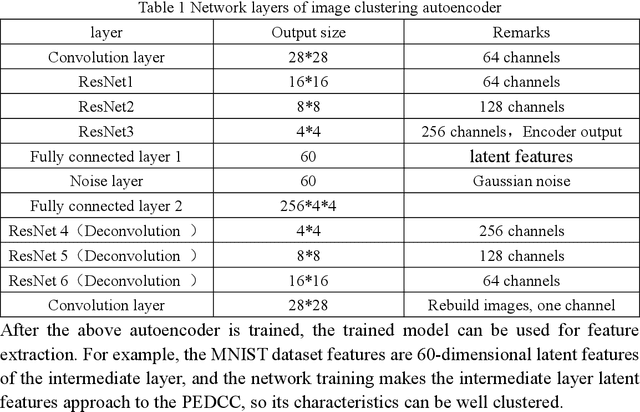

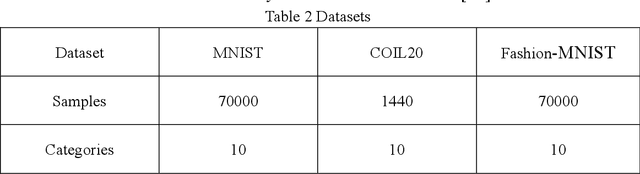
In this paper, we propose an end-to-end image clustering auto-encoder algorithm: ICAE. The algorithm uses PEDCC (Predefined Evenly-Distributed Class Centroids) as the clustering centers of the images, which ensures the inter-class distance of latent features is maximal, and adds data distribution constraint, data augmentation constraint, auto-encoder reconstruction loss constraint and latent features plus noise constraint to improve clustering performance. Specifically, we perform one-to-one data augmentation such as rotation, shear, and shift before data is input to the encoder to learn the more effective features. The data and the enhanced data are simultaneously input into the auto-encoder to obtain latent features and augmented latent features whose similarity are constrained by an augmentation loss. Then, making use of the MMD distance, we combine the latent features and augmented latent features to make their distribution close to the PEDCC distribution (uniform distribution between classes, Dirac distribution within the class) to further learn the features used for clustering. At the same time, the MSE of the original input image and reconstructed image is used as reconstruction constraint, and the noise is added to the latent features to build generalization constraint to improve the generalization ability. Finally, extensive experiments on three common datasets MNIST, Fashion-MNIST, COIL20 are conducted. The experimental results show that the algorithm has achieved the best clustering results so far, and also has good generalization ability. In addition, we can use the pre-defined PEDCC class centers, and the decoding module of the auto-encoder to clearly generate the samples of each class. The code can be downloaded at xxx!