 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQiwei Peng
HumanEval-XL: A Multilingual Code Generation Benchmark for Cross-lingual Natural Language Generalization
Feb 26, 2024
Large language models (LLMs) have made significant progress in generating codes from textual prompts. However, existing benchmarks have mainly concentrated on translating English prompts to multilingual codes or have been constrained to very limited natural languages (NLs). These benchmarks have overlooked the vast landscape of massively multilingual NL to multilingual code, leaving a critical gap in the evaluation of multilingual LLMs. In response, we introduce HumanEval-XL, a massively multilingual code generation benchmark specifically crafted to address this deficiency. HumanEval-XL establishes connections between 23 NLs and 12 programming languages (PLs), and comprises of a collection of 22,080 prompts with an average of 8.33 test cases. By ensuring parallel data across multiple NLs and PLs, HumanEval-XL offers a comprehensive evaluation platform for multilingual LLMs, allowing the assessment of the understanding of different NLs. Our work serves as a pioneering step towards filling the void in evaluating NL generalization in the area of multilingual code generation. We make our evaluation code and data publicly available at \url{https://github.com/FloatAI/HumanEval-XL}.
Towards Structure-aware Paraphrase Identification with Phrase Alignment Using Sentence Encoders
Oct 11, 2022
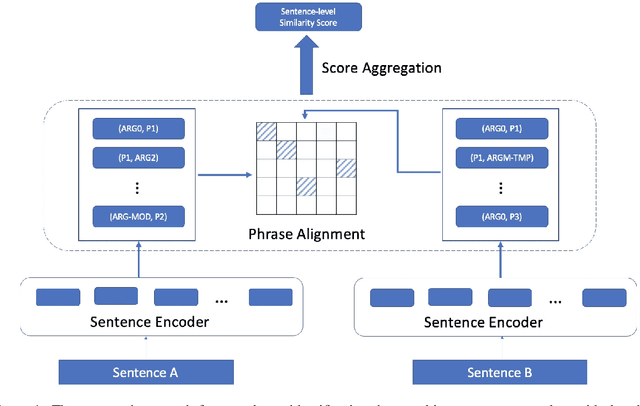
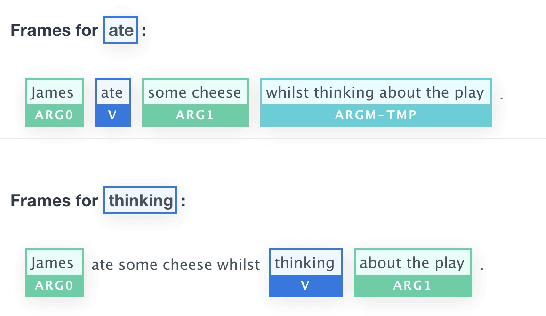
Previous works have demonstrated the effectiveness of utilising pre-trained sentence encoders based on their sentence representations for meaning comparison tasks. Though such representations are shown to capture hidden syntax structures, the direct similarity comparison between them exhibits weak sensitivity to word order and structural differences in given sentences. A single similarity score further makes the comparison process hard to interpret. Therefore, we here propose to combine sentence encoders with an alignment component by representing each sentence as a list of predicate-argument spans (where their span representations are derived from sentence encoders), and decomposing the sentence-level meaning comparison into the alignment between their spans for paraphrase identification tasks. Empirical results show that the alignment component brings in both improved performance and interpretability for various sentence encoders. After closer investigation, the proposed approach indicates increased sensitivity to structural difference and enhanced ability to distinguish non-paraphrases with high lexical overlap.
Representing Syntax and Composition with Geometric Transformations
Jun 03, 2021
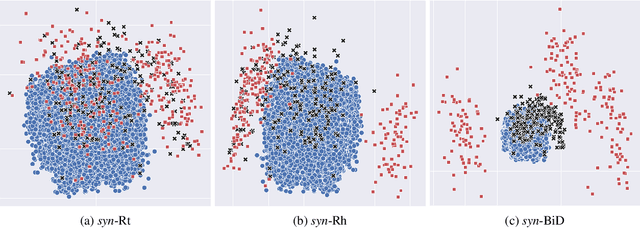
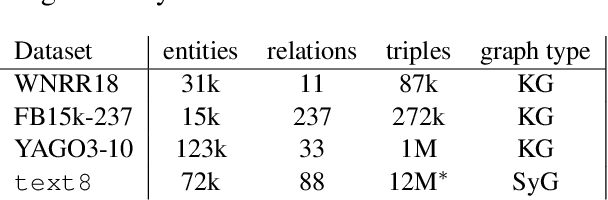
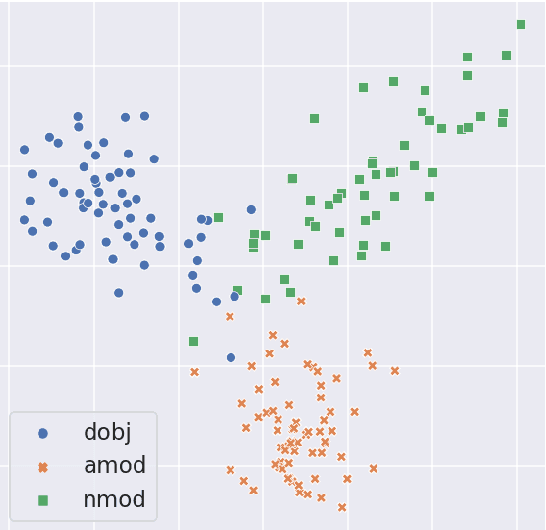
The exploitation of syntactic graphs (SyGs) as a word's context has been shown to be beneficial for distributional semantic models (DSMs), both at the level of individual word representations and in deriving phrasal representations via composition. However, notwithstanding the potential performance benefit, the syntactically-aware DSMs proposed to date have huge numbers of parameters (compared to conventional DSMs) and suffer from data sparsity. Furthermore, the encoding of the SyG links (i.e., the syntactic relations) has been largely limited to linear maps. The knowledge graphs' literature, on the other hand, has proposed light-weight models employing different geometric transformations (GTs) to encode edges in a knowledge graph (KG). Our work explores the possibility of adopting this family of models to encode SyGs. Furthermore, we investigate which GT better encodes syntactic relations, so that these representations can be used to enhance phrase-level composition via syntactic contextualisation.