 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRada Mihalcea
MAiDE-up: Multilingual Deception Detection of GPT-generated Hotel Reviews
Apr 19, 2024
Deceptive reviews are becoming increasingly common, especially given the increase in performance and the prevalence of LLMs. While work to date has addressed the development of models to differentiate between truthful and deceptive human reviews, much less is known about the distinction between real reviews and AI-authored fake reviews. Moreover, most of the research so far has focused primarily on English, with very little work dedicated to other languages. In this paper, we compile and make publicly available the MAiDE-up dataset, consisting of 10,000 real and 10,000 AI-generated fake hotel reviews, balanced across ten languages. Using this dataset, we conduct extensive linguistic analyses to (1) compare the AI fake hotel reviews to real hotel reviews, and (2) identify the factors that influence the deception detection model performance. We explore the effectiveness of several models for deception detection in hotel reviews across three main dimensions: sentiment, location, and language. We find that these dimensions influence how well we can detect AI-generated fake reviews.
Cross-cultural Inspiration Detection and Analysis in Real and LLM-generated Social Media Data
Apr 19, 2024Inspiration is linked to various positive outcomes, such as increased creativity, productivity, and happiness. Although inspiration has great potential, there has been limited effort toward identifying content that is inspiring, as opposed to just engaging or positive. Additionally, most research has concentrated on Western data, with little attention paid to other cultures. This work is the first to study cross-cultural inspiration through machine learning methods. We aim to identify and analyze real and AI-generated cross-cultural inspiring posts. To this end, we compile and make publicly available the InspAIred dataset, which consists of 2,000 real inspiring posts, 2,000 real non-inspiring posts, and 2,000 generated inspiring posts evenly distributed across India and the UK. The real posts are sourced from Reddit, while the generated posts are created using the GPT-4 model. Using this dataset, we conduct extensive computational linguistic analyses to (1) compare inspiring content across cultures, (2) compare AI-generated inspiring posts to real inspiring posts, and (3) determine if detection models can accurately distinguish between inspiring content across cultures and data sources.
On the Causal Nature of Sentiment Analysis
Apr 17, 2024Sentiment analysis (SA) aims to identify the sentiment expressed in a text, such as a product review. Given a review and the sentiment associated with it, this paper formulates SA as a combination of two tasks: (1) a causal discovery task that distinguishes whether a review "primes" the sentiment (Causal Hypothesis C1), or the sentiment "primes" the review (Causal Hypothesis C2); and (2) the traditional prediction task to model the sentiment using the review as input. Using the peak-end rule in psychology, we classify a sample as C1 if its overall sentiment score approximates an average of all the sentence-level sentiments in the review, and C2 if the overall sentiment score approximates an average of the peak and end sentiments. For the prediction task, we use the discovered causal mechanisms behind the samples to improve the performance of LLMs by proposing causal prompts that give the models an inductive bias of the underlying causal graph, leading to substantial improvements by up to 32.13 F1 points on zero-shot five-class SA. Our code is at https://github.com/cogito233/causal-sa
Tango 2: Aligning Diffusion-based Text-to-Audio Generations through Direct Preference Optimization
Apr 16, 2024Generative multimodal content is increasingly prevalent in much of the content creation arena, as it has the potential to allow artists and media personnel to create pre-production mockups by quickly bringing their ideas to life. The generation of audio from text prompts is an important aspect of such processes in the music and film industry. Many of the recent diffusion-based text-to-audio models focus on training increasingly sophisticated diffusion models on a large set of datasets of prompt-audio pairs. These models do not explicitly focus on the presence of concepts or events and their temporal ordering in the output audio with respect to the input prompt. Our hypothesis is focusing on how these aspects of audio generation could improve audio generation performance in the presence of limited data. As such, in this work, using an existing text-to-audio model Tango, we synthetically create a preference dataset where each prompt has a winner audio output and some loser audio outputs for the diffusion model to learn from. The loser outputs, in theory, have some concepts from the prompt missing or in an incorrect order. We fine-tune the publicly available Tango text-to-audio model using diffusion-DPO (direct preference optimization) loss on our preference dataset and show that it leads to improved audio output over Tango and AudioLDM2, in terms of both automatic- and manual-evaluation metrics.
The Generation Gap:Exploring Age Bias in Large Language Models
Apr 12, 2024In this paper, we explore the alignment of values in Large Language Models (LLMs) with specific age groups, leveraging data from the World Value Survey across thirteen categories. Through a diverse set of prompts tailored to ensure response robustness, we find a general inclination of LLM values towards younger demographics. Additionally, we explore the impact of incorporating age identity information in prompts and observe challenges in mitigating value discrepancies with different age cohorts. Our findings highlight the age bias in LLMs and provide insights for future work.
Towards Algorithmic Fidelity: Mental Health Representation across Demographics in Synthetic vs. Human-generated Data
Mar 25, 2024Synthetic data generation has the potential to impact applications and domains with scarce data. However, before such data is used for sensitive tasks such as mental health, we need an understanding of how different demographics are represented in it. In our paper, we analyze the potential of producing synthetic data using GPT-3 by exploring the various stressors it attributes to different race and gender combinations, to provide insight for future researchers looking into using LLMs for data generation. Using GPT-3, we develop HEADROOM, a synthetic dataset of 3,120 posts about depression-triggering stressors, by controlling for race, gender, and time frame (before and after COVID-19). Using this dataset, we conduct semantic and lexical analyses to (1) identify the predominant stressors for each demographic group; and (2) compare our synthetic data to a human-generated dataset. We present the procedures to generate queries to develop depression data using GPT-3, and conduct analyzes to uncover the types of stressors it assigns to demographic groups, which could be used to test the limitations of LLMs for synthetic data generation for depression data. Our findings show that synthetic data mimics some of the human-generated data distribution for the predominant depression stressors across diverse demographics.
Dynamic Reward Adjustment in Multi-Reward Reinforcement Learning for Counselor Reflection Generation
Mar 20, 2024
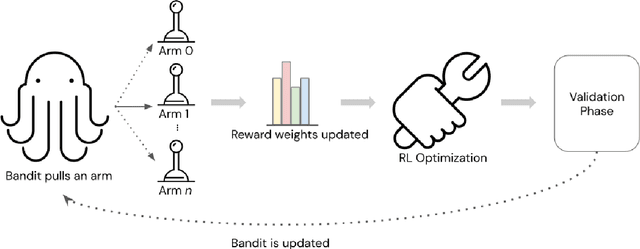

In this paper, we study the problem of multi-reward reinforcement learning to jointly optimize for multiple text qualities for natural language generation. We focus on the task of counselor reflection generation, where we optimize the generators to simultaneously improve the fluency, coherence, and reflection quality of generated counselor responses. We introduce two novel bandit methods, DynaOpt and C-DynaOpt, which rely on the broad strategy of combining rewards into a single value and optimizing them simultaneously. Specifically, we employ non-contextual and contextual multi-arm bandits to dynamically adjust multiple reward weights during training. Through automatic and manual evaluations, we show that our proposed techniques, DynaOpt and C-DynaOpt, outperform existing naive and bandit baselines, showcasing their potential for enhancing language models.
Annotations on a Budget: Leveraging Geo-Data Similarity to Balance Model Performance and Annotation Cost
Mar 12, 2024


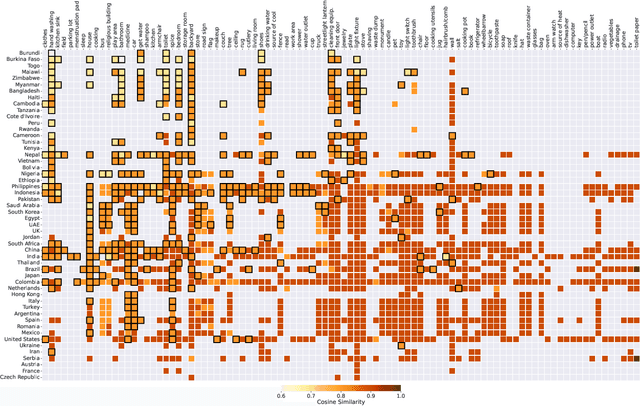
Current foundation models have shown impressive performance across various tasks. However, several studies have revealed that these models are not effective for everyone due to the imbalanced geographical and economic representation of the data used in the training process. Most of this data comes from Western countries, leading to poor results for underrepresented countries. To address this issue, more data needs to be collected from these countries, but the cost of annotation can be a significant bottleneck. In this paper, we propose methods to identify the data to be annotated to balance model performance and annotation costs. Our approach first involves finding the countries with images of topics (objects and actions) most visually distinct from those already in the training datasets used by current large vision-language foundation models. Next, we identify countries with higher visual similarity for these topics and show that using data from these countries to supplement the training data improves model performance and reduces annotation costs. The resulting lists of countries and corresponding topics are made available at https://github.com/MichiganNLP/visual_diversity_budget.
CLoVe: Encoding Compositional Language in Contrastive Vision-Language Models
Mar 01, 2024Recent years have witnessed a significant increase in the performance of Vision and Language tasks. Foundational Vision-Language Models (VLMs), such as CLIP, have been leveraged in multiple settings and demonstrated remarkable performance across several tasks. Such models excel at object-centric recognition yet learn text representations that seem invariant to word order, failing to compose known concepts in novel ways. However, no evidence exists that any VLM, including large-scale single-stream models such as GPT-4V, identifies compositions successfully. In this paper, we introduce a framework to significantly improve the ability of existing models to encode compositional language, with over 10% absolute improvement on compositionality benchmarks, while maintaining or improving the performance on standard object-recognition and retrieval benchmarks. Our code and pre-trained models are publicly available at https://github.com/netflix/clove.
Tables as Images? Exploring the Strengths and Limitations of LLMs on Multimodal Representations of Tabular Data
Feb 23, 2024In this paper, we investigate the effectiveness of various LLMs in interpreting tabular data through different prompting strategies and data formats. Our analysis extends across six benchmarks for table-related tasks such as question-answering and fact-checking. We introduce for the first time the assessment of LLMs' performance on image-based table representations. Specifically, we compare five text-based and three image-based table representations, demonstrating the influence of representation and prompting on LLM performance. Our study provides insights into the effective use of LLMs on table-related tasks.