 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaghuveer Thirukovalluru
Calibrating Long-form Generations from Large Language Models
Feb 09, 2024
To enhance Large Language Models' (LLMs) reliability, calibration is essential -- the model's assessed confidence scores should align with the actual likelihood of its responses being correct. However, current confidence elicitation methods and calibration metrics typically rely on a binary true/false assessment of response correctness. This approach does not apply to long-form generation, where an answer can be partially correct. Addressing this gap, we introduce a unified calibration framework, in which both the correctness of the LLMs' responses and their associated confidence levels are treated as distributions across a range of scores. Within this framework, we develop three metrics to precisely evaluate LLM calibration and further propose two confidence elicitation methods based on self-consistency and self-evaluation. Our experiments, which include long-form QA and summarization tasks, demonstrate that larger models don't necessarily guarantee better calibration, that calibration performance is found to be metric-dependent, and that self-consistency methods excel in factoid datasets. We also find that calibration can be enhanced through techniques such as fine-tuning, integrating relevant source documents, scaling the temperature, and combining self-consistency with self-evaluation. Lastly, we showcase a practical application of our system: selecting and cascading open-source models and ChatGPT to optimize correctness given a limited API budget. This research not only challenges existing notions of LLM calibration but also offers practical methodologies for improving trustworthiness in long-form generation.
Longtonotes: OntoNotes with Longer Coreference Chains
Oct 07, 2022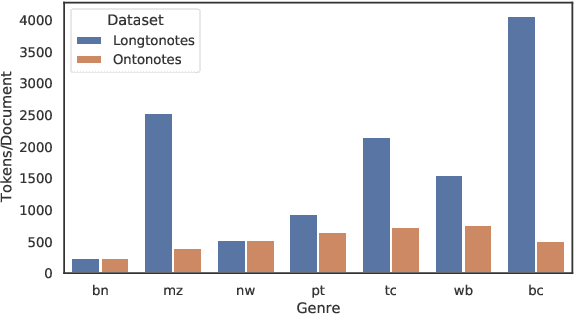
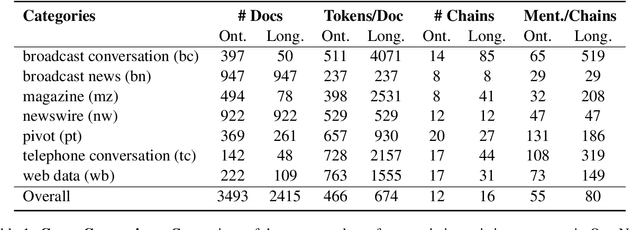
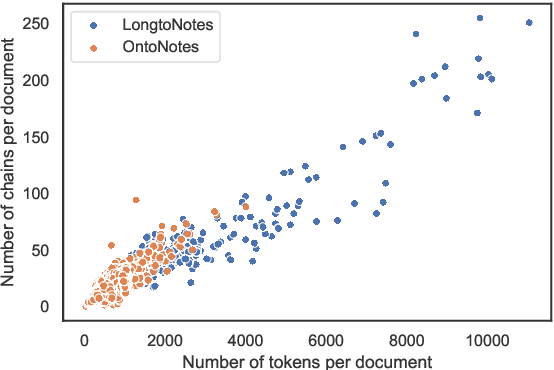
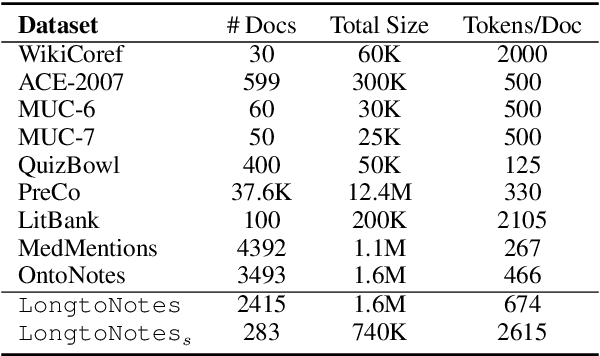
Ontonotes has served as the most important benchmark for coreference resolution. However, for ease of annotation, several long documents in Ontonotes were split into smaller parts. In this work, we build a corpus of coreference-annotated documents of significantly longer length than what is currently available. We do so by providing an accurate, manually-curated, merging of annotations from documents that were split into multiple parts in the original Ontonotes annotation process. The resulting corpus, which we call LongtoNotes contains documents in multiple genres of the English language with varying lengths, the longest of which are up to 8x the length of documents in Ontonotes, and 2x those in Litbank. We evaluate state-of-the-art neural coreference systems on this new corpus, analyze the relationships between model architectures/hyperparameters and document length on performance and efficiency of the models, and demonstrate areas of improvement in long-document coreference modeling revealed by our new corpus. Our data and code is available at: https://github.com/kumar-shridhar/LongtoNotes.