 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRansalu Senanayake
The Role of Predictive Uncertainty and Diversity in Embodied AI and Robot Learning
May 06, 2024
Uncertainty has long been a critical area of study in robotics, particularly when robots are equipped with analytical models. As we move towards the widespread use of deep neural networks in robots, which have demonstrated remarkable performance in research settings, understanding the nuances of uncertainty becomes crucial for their real-world deployment. This guide offers an overview of the importance of uncertainty and provides methods to quantify and evaluate it from an applications perspective.
Graph Attention Multi-Agent Fleet Autonomy for Advanced Air Mobility
Feb 16, 2023



Autonomous mobility is emerging as a new mode of urban transportation for moving cargo and passengers. However, such fleet coordination schemes face significant challenges in scaling to accommodate fast-growing fleet sizes that vary in their operational range, capacity, and communication capabilities. We introduce the concept of partially observable advanced air mobility games to coordinate a fleet of aerial vehicle agents accounting for their heterogeneity and self-interest inherent to commercial mobility fleets. We propose a novel heterogeneous graph attention-based encoder-decoder (HetGAT Enc-Dec) neural network to construct a generalizable stochastic policy stemming from the inter- and intra-agent relations within the mobility system. We train our policy by leveraging deep multi-agent reinforcement learning, allowing decentralized decision-making for the agents using their local observations. Through extensive experimentation, we show that the fleets operating under the HetGAT Enc-Dec policy outperform other state-of-the-art graph neural network-based policies by achieving the highest fleet reward and fulfillment ratios in an on-demand mobility network.
Uncertainty-Aware Online Merge Planning with Learned Driver Behavior
Jul 11, 2022



Safe and reliable autonomy solutions are a critical component of next-generation intelligent transportation systems. Autonomous vehicles in such systems must reason about complex and dynamic driving scenes in real time and anticipate the behavior of nearby drivers. Human driving behavior is highly nuanced and specific to individual traffic participants. For example, drivers might display cooperative or non-cooperative behaviors in the presence of merging vehicles. These behaviors must be estimated and incorporated in the planning process for safe and efficient driving. In this work, we present a framework for estimating the cooperation level of drivers on a freeway and plan merging maneuvers with the drivers' latent behaviors explicitly modeled. The latent parameter estimation problem is solved using a particle filter to approximate the probability distribution over the cooperation level. A partially observable Markov decision process (POMDP) that includes the latent state estimate is solved online to extract a policy for a merging vehicle. We evaluate our method in a high-fidelity automotive simulator against methods that are agnostic to latent states or rely on $\textit{a priori}$ assumptions about actor behavior.
Renaissance Robot: Optimal Transport Policy Fusion for Learning Diverse Skills
Jul 03, 2022



Deep reinforcement learning (RL) is a promising approach to solving complex robotics problems. However, the process of learning through trial-and-error interactions is often highly time-consuming, despite recent advancements in RL algorithms. Additionally, the success of RL is critically dependent on how well the reward-shaping function suits the task, which is also time-consuming to design. As agents trained on a variety of robotics problems continue to proliferate, the ability to reuse their valuable learning for new domains becomes increasingly significant. In this paper, we propose a post-hoc technique for policy fusion using Optimal Transport theory as a robust means of consolidating the knowledge of multiple agents that have been trained on distinct scenarios. We further demonstrate that this provides an improved weights initialisation of the neural network policy for learning new tasks, requiring less time and computational resources than either retraining the parent policies or training a new policy from scratch. Ultimately, our results on diverse agents commonly used in deep RL show that specialised knowledge can be unified into a "Renaissance agent", allowing for quicker learning of new skills.
Disentangling Epistemic and Aleatoric Uncertainty in Reinforcement Learning
Jun 03, 2022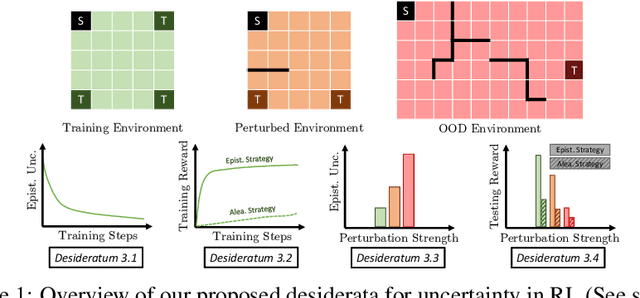

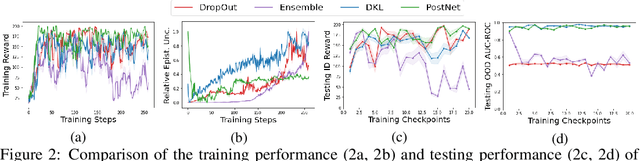
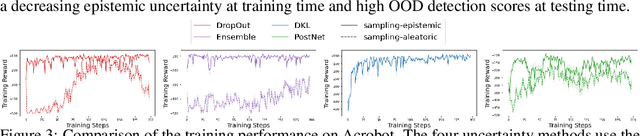
Characterizing aleatoric and epistemic uncertainty on the predicted rewards can help in building reliable reinforcement learning (RL) systems. Aleatoric uncertainty results from the irreducible environment stochasticity leading to inherently risky states and actions. Epistemic uncertainty results from the limited information accumulated during learning to make informed decisions. Characterizing aleatoric and epistemic uncertainty can be used to speed up learning in a training environment, improve generalization to similar testing environments, and flag unfamiliar behavior in anomalous testing environments. In this work, we introduce a framework for disentangling aleatoric and epistemic uncertainty in RL. (1) We first define four desiderata that capture the desired behavior for aleatoric and epistemic uncertainty estimation in RL at both training and testing time. (2) We then present four RL models inspired by supervised learning (i.e. Monte Carlo dropout, ensemble, deep kernel learning models, and evidential networks) to instantiate aleatoric and epistemic uncertainty. Finally, (3) we propose a practical evaluation method to evaluate uncertainty estimation in model-free RL based on detection of out-of-distribution environments and generalization to perturbed environments. We present theoretical and experimental evidence to validate that carefully equipping model-free RL agents with supervised learning uncertainty methods can fulfill our desiderata.
Graphical Games for UAV Swarm Control Under Time-Varying Communication Networks
May 04, 2022

We propose a unified framework for coordinating Unmanned Aerial Vehicle (UAV) swarms operating under time-varying communication networks. Our framework builds on the concept of graphical games, which we argue provides a compelling paradigm to subsume the interaction structures found in networked UAV swarms thanks to the shared local neighborhood properties. We present a general-sum, factorizable payoff function for cooperative UAV swarms based on the aggregated local states and yield a Nash equilibrium for the stage games. Further, we propose a decomposition-based approach to solve stage-graphical games in a scalable and decentralized fashion by approximating virtual, mean neighborhoods. Finally, we discuss extending the proposed framework toward general-sum stochastic games by leveraging deep Q-learning and model-predictive control.
Model Predictive Optimized Path Integral Strategies
Mar 30, 2022



We generalize the derivation of model predictive path integral control (MPPI) to allow for a single joint distribution across controls in the control sequence. This reformation allows for the implementation of adaptive importance sampling (AIS) algorithms into the original importance sampling step while still maintaining the benefits of MPPI such as working with arbitrary system dynamics and cost functions. The benefit of optimizing the proposal distribution by integrating AIS at each control step is demonstrated in simulated environments including controlling multiple cars around a track. The new algorithm is more sample efficient than MPPI, achieving better performance with fewer samples. This performance disparity grows as the dimension of the action space increases. Results from simulations suggest the new algorithm can be used as an anytime algorithm, increasing the value of control at each iteration versus relying on a large set of samples.
How Do We Fail? Stress Testing Perception in Autonomous Vehicles
Mar 26, 2022



Autonomous vehicles (AVs) rely on environment perception and behavior prediction to reason about agents in their surroundings. These perception systems must be robust to adverse weather such as rain, fog, and snow. However, validation of these systems is challenging due to their complexity and dependence on observation histories. This paper presents a method for characterizing failures of LiDAR-based perception systems for AVs in adverse weather conditions. We develop a methodology based in reinforcement learning to find likely failures in object tracking and trajectory prediction due to sequences of disturbances. We apply disturbances using a physics-based data augmentation technique for simulating LiDAR point clouds in adverse weather conditions. Experiments performed across a wide range of driving scenarios from a real-world driving dataset show that our proposed approach finds high likelihood failures with smaller input disturbances compared to baselines while remaining computationally tractable. Identified failures can inform future development of robust perception systems for AVs.
FIG-OP: Exploring Large-Scale Unknown Environments on a Fixed Time Budget
Mar 12, 2022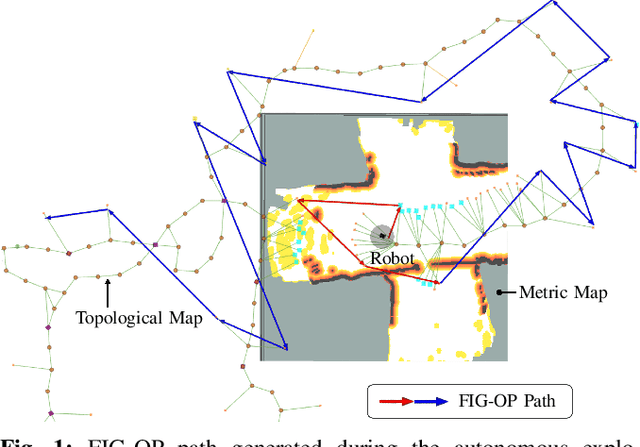
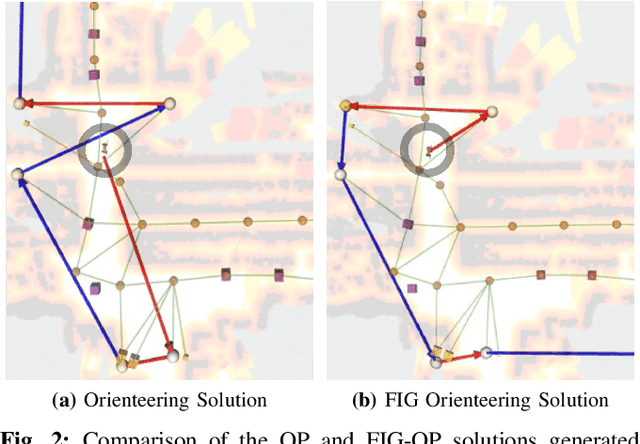
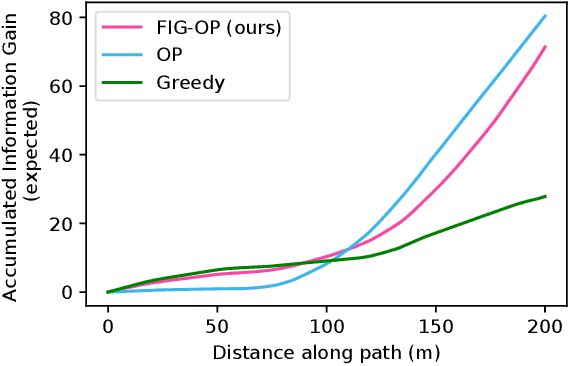
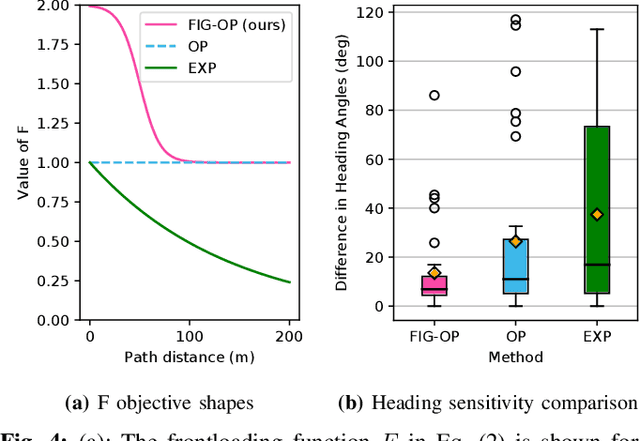
We present a method for autonomous exploration of large-scale unknown environments under mission time constraints. We start by proposing the Frontloaded Information Gain Orienteering Problem (FIG-OP) -- a generalization of the traditional orienteering problem where the assumption of a reliable environmental model no longer holds. The FIG-OP addresses model uncertainty by frontloading expected information gain through the addition of a greedy incentive, effectively expediting the moment in which new area is uncovered. In order to reason across multi-kilometre environments, we solve FIG-OP over an information-efficient world representation, constructed through the aggregation of information from a topological and metric map. Our method was extensively tested and field-hardened across various complex environments, ranging from subway systems to mines. In comparative simulations, we observe that the FIG-OP solution exhibits improved coverage efficiency over solutions generated by greedy and traditional orienteering-based approaches (i.e. severe and minimal model uncertainty assumptions, respectively).
CoCo Games: Graphical Game-Theoretic Swarm Control for Communication-Aware Coverage
Nov 08, 2021



We present a novel approach to maximize the communication-aware coverage for robots operating over large-scale geographical regions of interest (ROIs). Our approach complements the underlying network topology in neighborhood selection and control, rendering it highly robust in dynamic environments. We formulate the coverage as a multi-stage, cooperative graphical game and employ Variational Inference (VI) to reach the equilibrium. We experimentally validate our approach in an mobile ad-hoc wireless network scenario using Unmanned Aerial Vehicles (UAV) and User Equipment (UE) robots. We show that it can cater to ROIs defined by stationary and moving User Equipment (UE) robots under realistic network conditions.