 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaphael Tang
Rank-without-GPT: Building GPT-Independent Listwise Rerankers on Open-Source Large Language Models
Dec 05, 2023
Listwise rerankers based on large language models (LLM) are the zero-shot state-of-the-art. However, current works in this direction all depend on the GPT models, making it a single point of failure in scientific reproducibility. Moreover, it raises the concern that the current research findings only hold for GPT models but not LLM in general. In this work, we lift this pre-condition and build for the first time effective listwise rerankers without any form of dependency on GPT. Our passage retrieval experiments show that our best list se reranker surpasses the listwise rerankers based on GPT-3.5 by 13% and achieves 97% effectiveness of the ones built on GPT-4. Our results also show that the existing training datasets, which were expressly constructed for pointwise ranking, are insufficient for building such listwise rerankers. Instead, high-quality listwise ranking data is required and crucial, calling for further work on building human-annotated listwise data resources.
What Do Llamas Really Think? Revealing Preference Biases in Language Model Representations
Nov 30, 2023Do large language models (LLMs) exhibit sociodemographic biases, even when they decline to respond? To bypass their refusal to "speak," we study this research question by probing contextualized embeddings and exploring whether this bias is encoded in its latent representations. We propose a logistic Bradley-Terry probe which predicts word pair preferences of LLMs from the words' hidden vectors. We first validate our probe on three pair preference tasks and thirteen LLMs, where we outperform the word embedding association test (WEAT), a standard approach in testing for implicit association, by a relative 27% in error rate. We also find that word pair preferences are best represented in the middle layers. Next, we transfer probes trained on harmless tasks (e.g., pick the larger number) to controversial ones (compare ethnicities) to examine biases in nationality, politics, religion, and gender. We observe substantial bias for all target classes: for instance, the Mistral model implicitly prefers Europe to Africa, Christianity to Judaism, and left-wing to right-wing politics, despite declining to answer. This suggests that instruction fine-tuning does not necessarily debias contextualized embeddings. Our codebase is at https://github.com/castorini/biasprobe.
Found in the Middle: Permutation Self-Consistency Improves Listwise Ranking in Large Language Models
Oct 11, 2023Large language models (LLMs) exhibit positional bias in how they use context, which especially complicates listwise ranking. To address this, we propose permutation self-consistency, a form of self-consistency over ranking list outputs of black-box LLMs. Our key idea is to marginalize out different list orders in the prompt to produce an order-independent ranking with less positional bias. First, given some input prompt, we repeatedly shuffle the list in the prompt and pass it through the LLM while holding the instructions the same. Next, we aggregate the resulting sample of rankings by computing the central ranking closest in distance to all of them, marginalizing out prompt order biases in the process. Theoretically, we prove the robustness of our method, showing convergence to the true ranking in the presence of random perturbations. Empirically, on five list-ranking datasets in sorting and passage reranking, our approach improves scores from conventional inference by up to 7-18% for GPT-3.5 and 8-16% for LLaMA v2 (70B), surpassing the previous state of the art in passage reranking. Our code is at https://github.com/castorini/perm-sc.
Less is More: Parameter-Free Text Classification with Gzip
Dec 19, 2022
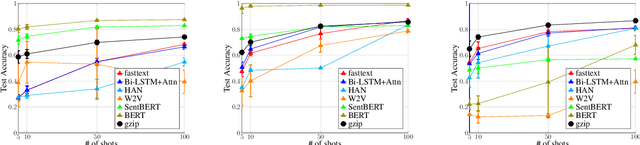
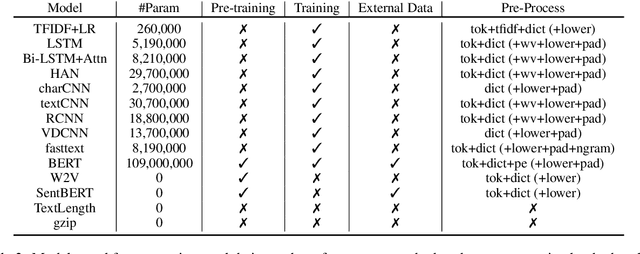

Deep neural networks (DNNs) are often used for text classification tasks as they usually achieve high levels of accuracy. However, DNNs can be computationally intensive with billions of parameters and large amounts of labeled data, which can make them expensive to use, to optimize and to transfer to out-of-distribution (OOD) cases in practice. In this paper, we propose a non-parametric alternative to DNNs that's easy, light-weight and universal in text classification: a combination of a simple compressor like gzip with a $k$-nearest-neighbor classifier. Without any training, pre-training or fine-tuning, our method achieves results that are competitive with non-pretrained deep learning methods on six in-distributed datasets. It even outperforms BERT on all five OOD datasets, including four low-resource languages. Our method also performs particularly well in few-shot settings where labeled data are too scarce for DNNs to achieve a satisfying accuracy.
SpeechNet: Weakly Supervised, End-to-End Speech Recognition at Industrial Scale
Nov 21, 2022

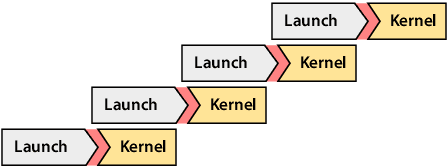
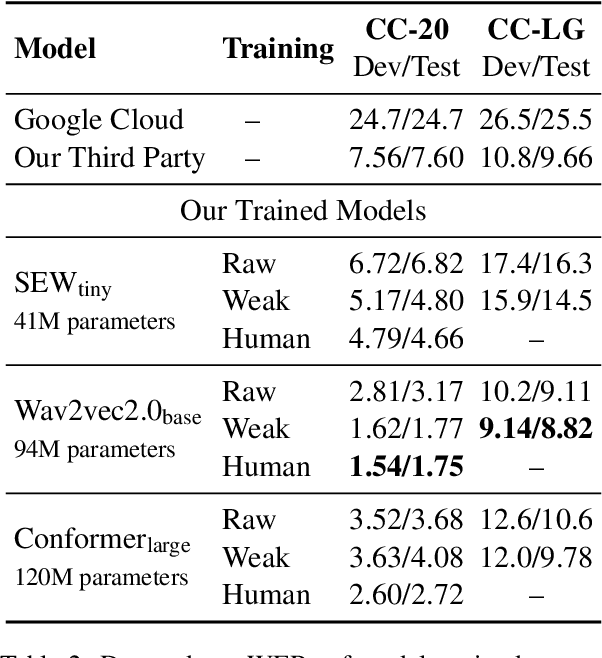
End-to-end automatic speech recognition systems represent the state of the art, but they rely on thousands of hours of manually annotated speech for training, as well as heavyweight computation for inference. Of course, this impedes commercialization since most companies lack vast human and computational resources. In this paper, we explore training and deploying an ASR system in the label-scarce, compute-limited setting. To reduce human labor, we use a third-party ASR system as a weak supervision source, supplemented with labeling functions derived from implicit user feedback. To accelerate inference, we propose to route production-time queries across a pool of CUDA graphs of varying input lengths, the distribution of which best matches the traffic's. Compared to our third-party ASR, we achieve a relative improvement in word-error rate of 8% and a speedup of 600%. Our system, called SpeechNet, currently serves 12 million queries per day on our voice-enabled smart television. To our knowledge, this is the first time a large-scale, Wav2vec-based deployment has been described in the academic literature.
What the DAAM: Interpreting Stable Diffusion Using Cross Attention
Oct 11, 2022
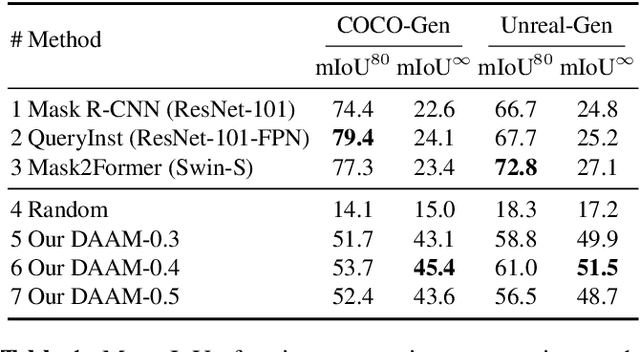
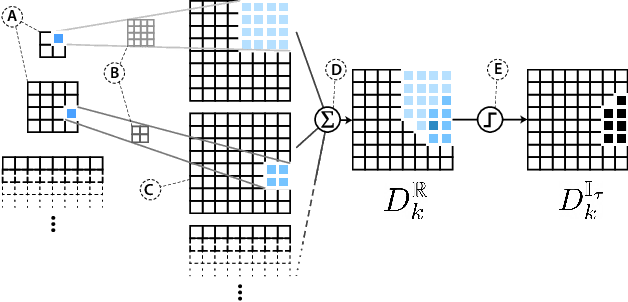

Large-scale diffusion neural networks represent a substantial milestone in text-to-image generation, with some performing similar to real photographs in human evaluation. However, they remain poorly understood, lacking explainability and interpretability analyses, largely due to their proprietary, closed-source nature. In this paper, to shine some much-needed light on text-to-image diffusion models, we perform a text-image attribution analysis on Stable Diffusion, a recently open-sourced large diffusion model. To produce pixel-level attribution maps, we propose DAAM, a novel method based on upscaling and aggregating cross-attention activations in the latent denoising subnetwork. We support its correctness by evaluating its unsupervised semantic segmentation quality on its own generated imagery, compared to supervised segmentation models. We show that DAAM performs strongly on COCO caption-generated images, achieving an mIoU of 61.0, and it outperforms supervised models on open-vocabulary segmentation, for an mIoU of 51.5. We further find that certain parts of speech, like punctuation and conjunctions, influence the generated imagery most, which agrees with the prior literature, while determiners and numerals the least, suggesting poor numeracy. To our knowledge, we are the first to propose and study word-pixel attribution for large-scale text-to-image diffusion models. Our code and data are at https://github.com/castorini/daam.
Building an Efficiency Pipeline: Commutativity and Cumulativeness of Efficiency Operators for Transformers
Jul 31, 2022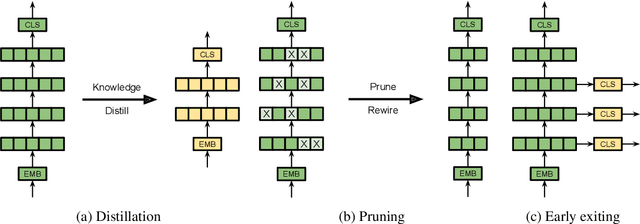
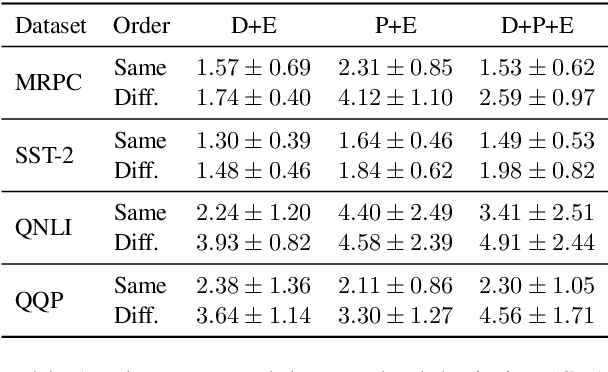
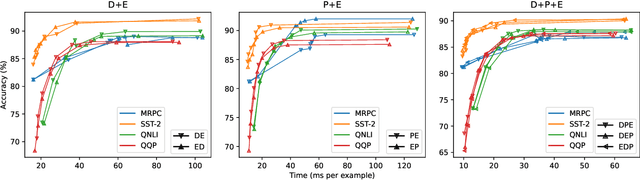
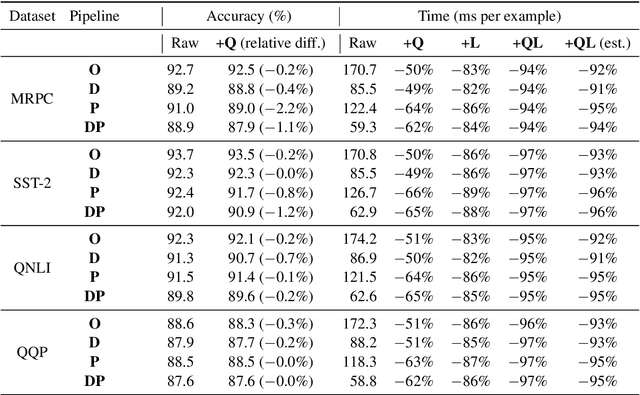
There exists a wide variety of efficiency methods for natural language processing (NLP) tasks, such as pruning, distillation, dynamic inference, quantization, etc. We can consider an efficiency method as an operator applied on a model. Naturally, we may construct a pipeline of multiple efficiency methods, i.e., to apply multiple operators on the model sequentially. In this paper, we study the plausibility of this idea, and more importantly, the commutativity and cumulativeness of efficiency operators. We make two interesting observations: (1) Efficiency operators are commutative -- the order of efficiency methods within the pipeline has little impact on the final results; (2) Efficiency operators are also cumulative -- the final results of combining several efficiency methods can be estimated by combining the results of individual methods. These observations deepen our understanding of efficiency operators and provide useful guidelines for their real-world applications.
Inserting Information Bottlenecks for Attribution in Transformers
Dec 27, 2020
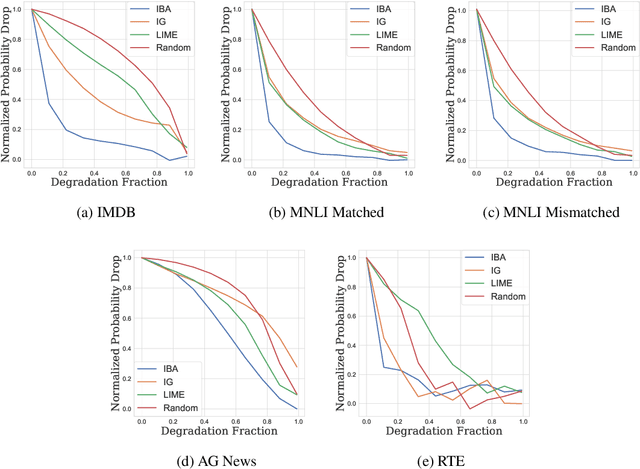

Pretrained transformers achieve the state of the art across tasks in natural language processing, motivating researchers to investigate their inner mechanisms. One common direction is to understand what features are important for prediction. In this paper, we apply information bottlenecks to analyze the attribution of each feature for prediction on a black-box model. We use BERT as the example and evaluate our approach both quantitatively and qualitatively. We show the effectiveness of our method in terms of attribution and the ability to provide insight into how information flows through layers. We demonstrate that our technique outperforms two competitive methods in degradation tests on four datasets. Code is available at https://github.com/bazingagin/IBA.
Howl: A Deployed, Open-Source Wake Word Detection System
Aug 21, 2020

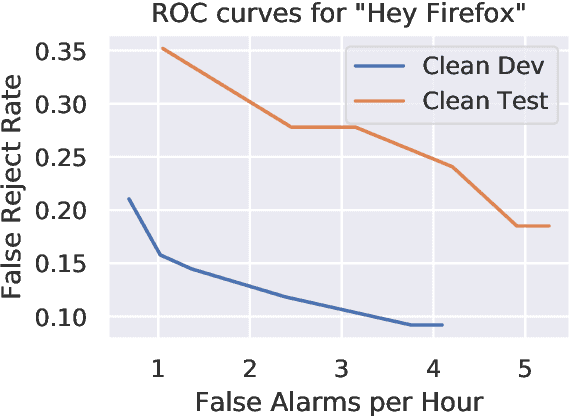
We describe Howl, an open-source wake word detection toolkit with native support for open speech datasets, like Mozilla Common Voice and Google Speech Commands. We report benchmark results on Speech Commands and our own freely available wake word detection dataset, built from MCV. We operationalize our system for Firefox Voice, a plugin enabling speech interactivity for the Firefox web browser. Howl represents, to the best of our knowledge, the first fully productionized yet open-source wake word detection toolkit with a web browser deployment target. Our codebase is at https://github.com/castorini/howl.
Covidex: Neural Ranking Models and Keyword Search Infrastructure for the COVID-19 Open Research Dataset
Jul 14, 2020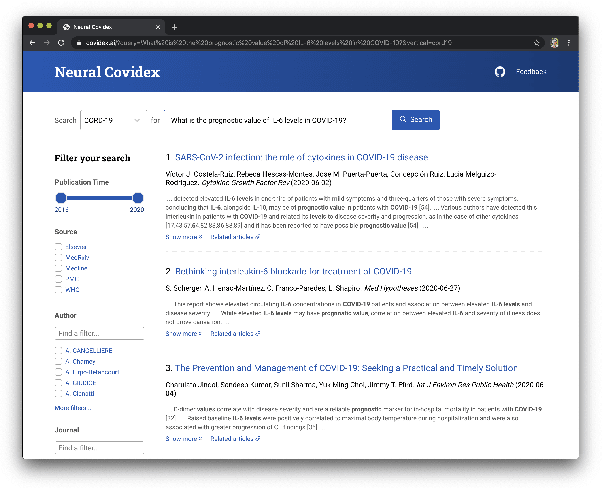
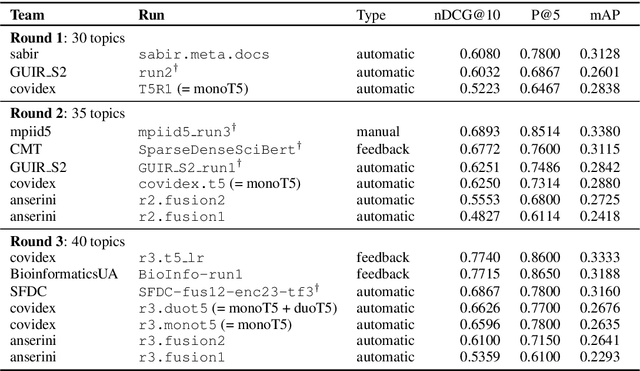
We present Covidex, a search engine that exploits the latest neural ranking models to provide information access to the COVID-19 Open Research Dataset curated by the Allen Institute for AI. Our system has been online and serving users since late March 2020. The Covidex is the user application component of our three-pronged strategy to develop technologies for helping domain experts tackle the ongoing global pandemic. In addition, we provide robust and easy-to-use keyword search infrastructure that exploits mature fusion-based methods as well as standalone neural ranking models that can be incorporated into other applications. These techniques have been evaluated in the ongoing TREC-COVID challenge: Our infrastructure and baselines have been adopted by many participants, including some of the highest-scoring runs in rounds 1, 2, and 3. In round 3, we report the highest-scoring run that takes advantage of previous training data and the second-highest fully automatic run.