 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRasha Alshawi
Dual Attention U-Net with Feature Infusion: Pushing the Boundaries of Multiclass Defect Segmentation
Dec 21, 2023
The proposed architecture, Dual Attentive U-Net with Feature Infusion (DAU-FI Net), addresses challenges in semantic segmentation, particularly on multiclass imbalanced datasets with limited samples. DAU-FI Net integrates multiscale spatial-channel attention mechanisms and feature injection to enhance precision in object localization. The core employs a multiscale depth-separable convolution block, capturing localized patterns across scales. This block is complemented by a spatial-channel squeeze and excitation (scSE) attention unit, modeling inter-dependencies between channels and spatial regions in feature maps. Additionally, additive attention gates refine segmentation by connecting encoder-decoder pathways. To augment the model, engineered features using Gabor filters for textural analysis, Sobel and Canny filters for edge detection are injected guided by semantic masks to expand the feature space strategically. Comprehensive experiments on a challenging sewer pipe and culvert defect dataset and a benchmark dataset validate DAU-FI Net's capabilities. Ablation studies highlight incremental benefits from attention blocks and feature injection. DAU-FI Net achieves state-of-the-art mean Intersection over Union (IoU) of 95.6% and 98.8% on the defect test set and benchmark respectively, surpassing prior methods by 8.9% and 12.6%, respectively. Ablation studies highlight incremental benefits from attention blocks and feature injection. The proposed architecture provides a robust solution, advancing semantic segmentation for multiclass problems with limited training data. Our sewer-culvert defects dataset, featuring pixel-level annotations, opens avenues for further research in this crucial domain. Overall, this work delivers key innovations in architecture, attention, and feature engineering to elevate semantic segmentation efficacy.
A Novel Dataset Towards Extracting Virus-Host Interactions
May 11, 2023
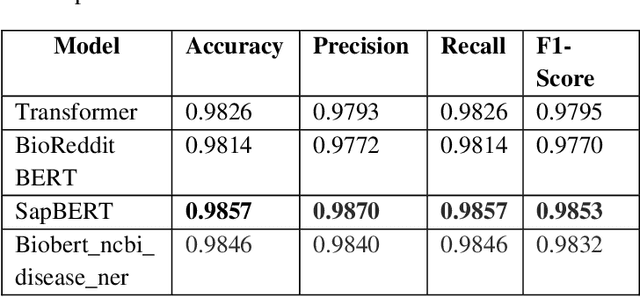


We describe a novel dataset for the automated recognition of named taxonomic and other entities relevant to the association of viruses with their hosts. We further describe some initial results using pre-trained models on the named-entity recognition (NER) task on this novel dataset. We propose that our dataset of manually annotated abstracts now offers a Gold Standard Corpus for training future NER models in the automated extraction of host-pathogen detection methods from scientific publications, and further explain how our work makes first steps towards predicting the important human health-related concept of viral spillover risk automatically from the scientific literature.