 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRema Padman
On Curating Responsible and Representative Healthcare Video Recommendations for Patient Education and Health Literacy: An Augmented Intelligence Approach
Jul 13, 2022
Studies suggest that one in three US adults use the Internet to diagnose or learn about a health concern. However, such access to health information online could exacerbate the disparities in health information availability and use. Health information seeking behavior (HISB) refers to the ways in which individuals seek information about their health, risks, illnesses, and health-protective behaviors. For patients engaging in searches for health information on digital media platforms, health literacy divides can be exacerbated both by their own lack of knowledge and by algorithmic recommendations, with results that disproportionately impact disadvantaged populations, minorities, and low health literacy users. This study reports on an exploratory investigation of the above challenges by examining whether responsible and representative recommendations can be generated using advanced analytic methods applied to a large corpus of videos and their metadata on a chronic condition (diabetes) from the YouTube social media platform. The paper focusses on biases associated with demographic characters of actors using videos on diabetes that were retrieved and curated for multiple criteria such as encoded medical content and their understandability to address patient education and population health literacy needs. This approach offers an immense opportunity for innovation in human-in-the-loop, augmented-intelligence, bias-aware and responsible algorithmic recommendations by combining the perspectives of health professionals and patients into a scalable and generalizable machine learning framework for patient empowerment and improved health outcomes.
Limitations of ROC on Imbalanced Data: Evaluation of LVAD Mortality Risk Scores
Oct 29, 2020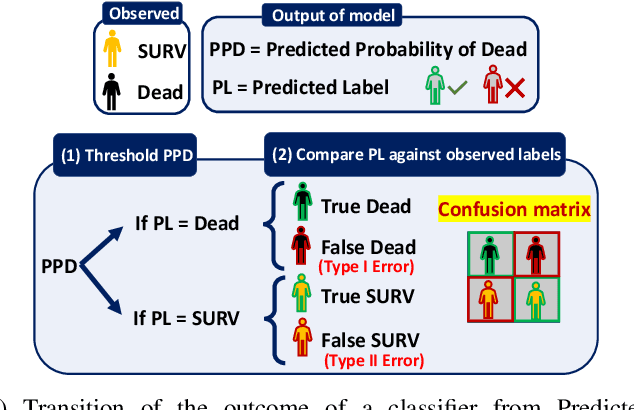
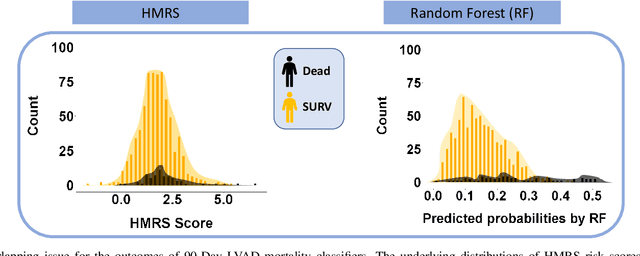
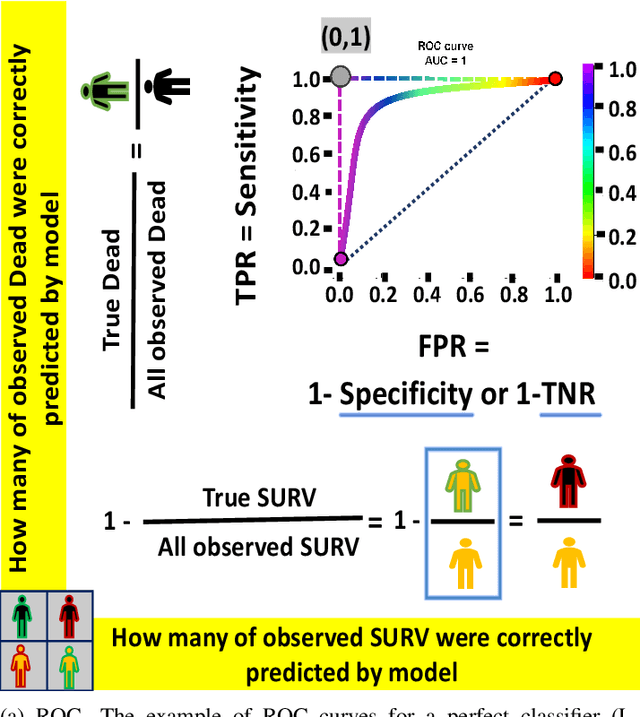
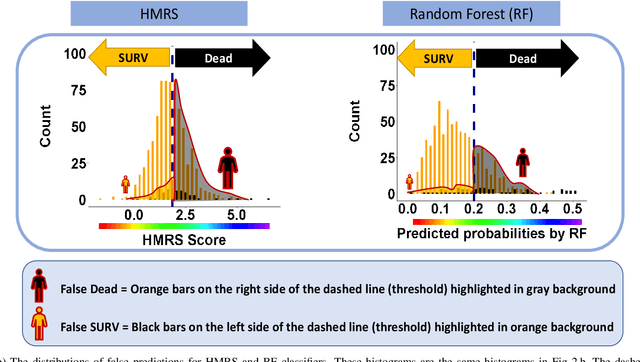
Objective: This study illustrates the ambiguity of ROC in evaluating two classifiers of 90-day LVAD mortality. This paper also introduces the precision recall curve (PRC) as a supplemental metric that is more representative of LVAD classifiers performance in predicting the minority class. Background: In the LVAD domain, the receiver operating characteristic (ROC) is a commonly applied metric of performance of classifiers. However, ROC can provide a distorted view of classifiers ability to predict short-term mortality due to the overwhelmingly greater proportion of patients who survive, i.e. imbalanced data. Methods: This study compared the ROC and PRC for the outcome of two classifiers for 90-day LVAD mortality for 800 patients (test group) recorded in INTERMACS who received a continuous-flow LVAD between 2006 and 2016 (mean age of 59 years; 146 females vs. 654 males) in which mortality rate is only %8 at 90-day (imbalanced data). The two classifiers were HeartMate Risk Score (HMRS) and a Random Forest (RF). Results: The ROC indicates fairly good performance of RF and HRMS classifiers with Area Under Curves (AUC) of 0.77 vs. 0.63, respectively. This is in contrast with their PRC with AUC of 0.43 vs. 0.16 for RF and HRMS, respectively. The PRC for HRMS showed the precision rapidly dropped to only 10% with slightly increasing sensitivity. Conclusion: The ROC can portray an overly-optimistic performance of a classifier or risk score when applied to imbalanced data. The PRC provides better insight about the performance of a classifier by focusing on the minority class.
Early Stratification of Patients at Risk for Postoperative Complications after Elective Colectomy
Nov 29, 2018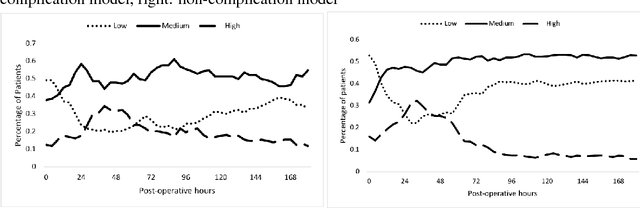
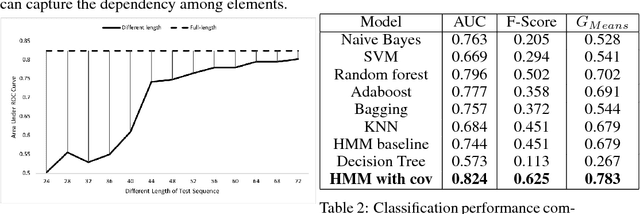
Stratifying patients at risk for postoperative complications may facilitate timely and accurate workups and reduce the burden of adverse events on patients and the health system. Currently, a widely-used surgical risk calculator created by the American College of Surgeons, NSQIP, uses 21 preoperative covariates to assess risk of postoperative complications, but lacks dynamic, real-time capabilities to accommodate postoperative information. We propose a new Hidden Markov Model sequence classifier for analyzing patients' postoperative temperature sequences that incorporates their time-invariant characteristics in both transition probability and initial state probability in order to develop a postoperative "real-time" complication detector. Data from elective Colectomy surgery indicate that our method has improved classification performance compared to 8 other machine learning classifiers when using the full temperature sequence associated with the patients' length of stay. Additionally, within 44 hours after surgery, the performance of the model is close to that of full-length temperature sequence.
A Deep Learning Architecture for De-identification of Patient Notes: Implementation and Evaluation
Oct 03, 2018
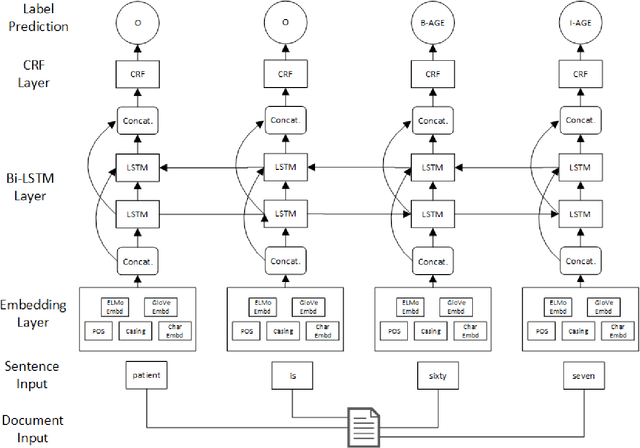

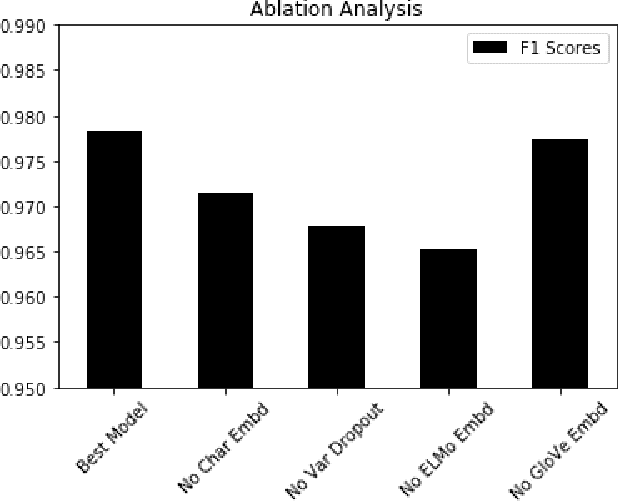
De-identification is the process of removing 18 protected health information (PHI) from clinical notes in order for the text to be considered not individually identifiable. Recent advances in natural language processing (NLP) has allowed for the use of deep learning techniques for the task of de-identification. In this paper, we present a deep learning architecture that builds on the latest NLP advances by incorporating deep contextualized word embeddings and variational drop out Bi-LSTMs. We test this architecture on two gold standard datasets and show that the architecture achieves state-of-the-art performance on both data sets while also converging faster than other systems without the use of dictionaries or other knowledge sources.
YouTube for Patient Education: A Deep Learning Approach for Understanding Medical Knowledge from User-Generated Videos
Jul 06, 2018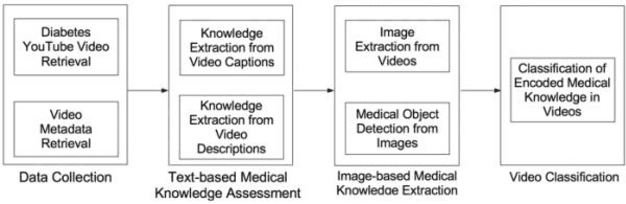
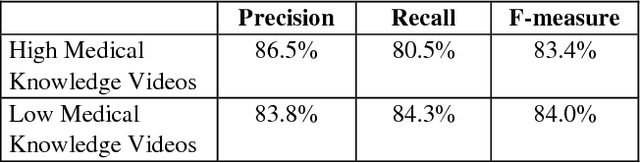
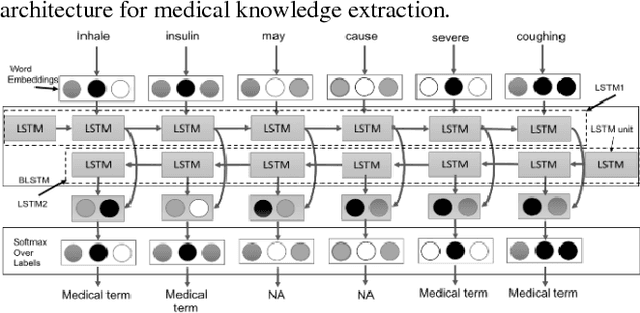
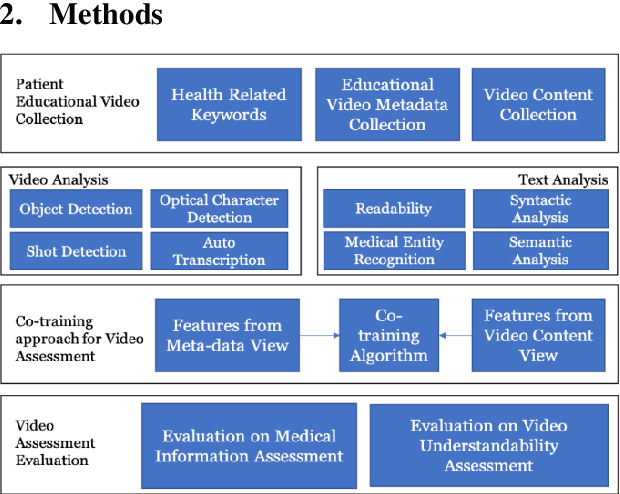
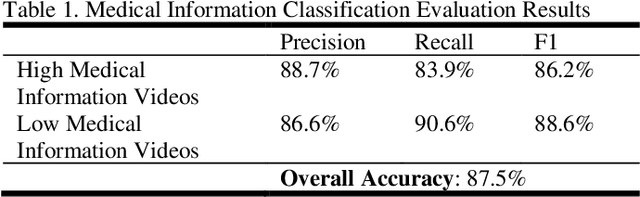
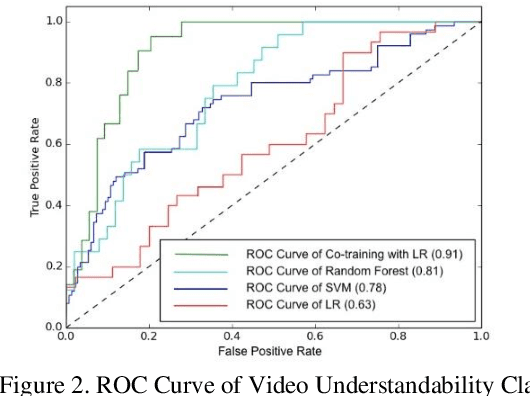
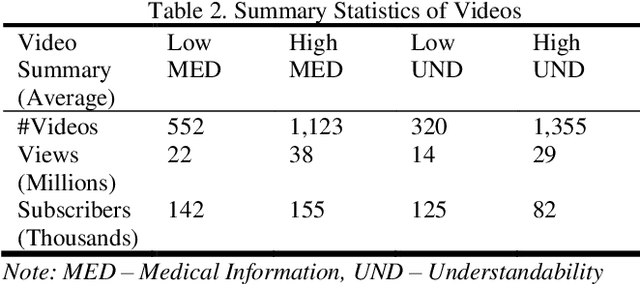
YouTube presents an unprecedented opportunity to explore how machine learning methods can improve healthcare information dissemination. We propose an interdisciplinary lens that synthesizes machine learning methods with healthcare informatics themes to address the critical issue of developing a scalable algorithmic solution to evaluate videos from a health literacy and patient education perspective. We develop a deep learning method to understand the level of medical knowledge encoded in YouTube videos. Preliminary results suggest that we can extract medical knowledge from YouTube videos and classify videos according to the embedded knowledge with satisfying performance. Deep learning methods show great promise in knowledge extraction, natural language understanding, and image classification, especially in an era of patient-centric care and precision medicine.