 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReyhane Askari Hemmat
QGen: On the Ability to Generalize in Quantization Aware Training
Apr 19, 2024
Quantization lowers memory usage, computational requirements, and latency by utilizing fewer bits to represent model weights and activations. In this work, we investigate the generalization properties of quantized neural networks, a characteristic that has received little attention despite its implications on model performance. In particular, first, we develop a theoretical model for quantization in neural networks and demonstrate how quantization functions as a form of regularization. Second, motivated by recent work connecting the sharpness of the loss landscape and generalization, we derive an approximate bound for the generalization of quantized models conditioned on the amount of quantization noise. We then validate our hypothesis by experimenting with over 2000 models trained on CIFAR-10, CIFAR-100, and ImageNet datasets on convolutional and transformer-based models.
Feedback-guided Data Synthesis for Imbalanced Classification
Sep 29, 2023Current status quo in machine learning is to use static datasets of real images for training, which often come from long-tailed distributions. With the recent advances in generative models, researchers have started augmenting these static datasets with synthetic data, reporting moderate performance improvements on classification tasks. We hypothesize that these performance gains are limited by the lack of feedback from the classifier to the generative model, which would promote the usefulness of the generated samples to improve the classifier's performance. In this work, we introduce a framework for augmenting static datasets with useful synthetic samples, which leverages one-shot feedback from the classifier to drive the sampling of the generative model. In order for the framework to be effective, we find that the samples must be close to the support of the real data of the task at hand, and be sufficiently diverse. We validate three feedback criteria on a long-tailed dataset (ImageNet-LT) as well as a group-imbalanced dataset (NICO++). On ImageNet-LT, we achieve state-of-the-art results, with over 4 percent improvement on underrepresented classes while being twice efficient in terms of the number of generated synthetic samples. NICO++ also enjoys marked boosts of over 5 percent in worst group accuracy. With these results, our framework paves the path towards effectively leveraging state-of-the-art text-to-image models as data sources that can be queried to improve downstream applications.
QReg: On Regularization Effects of Quantization
Jun 27, 2022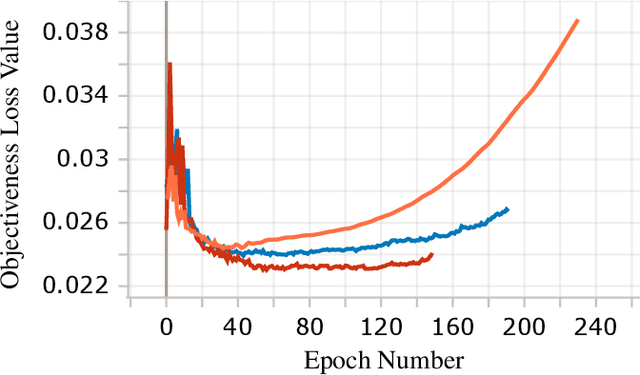
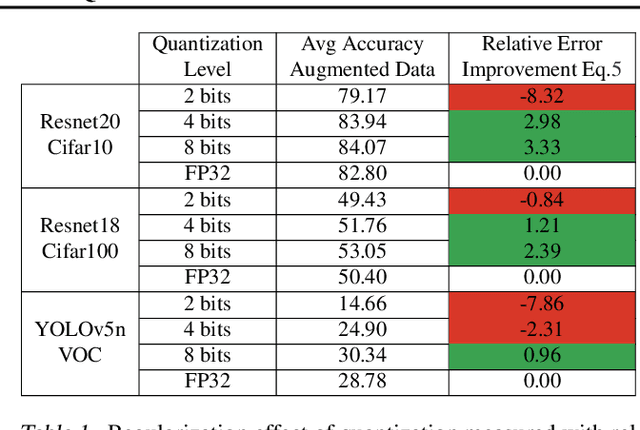
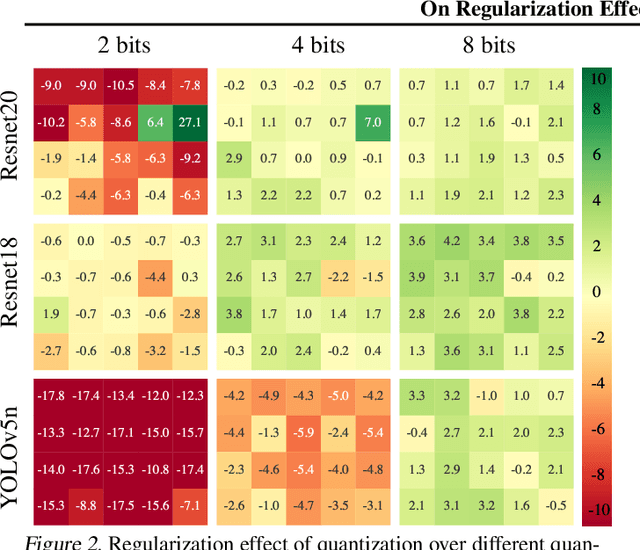
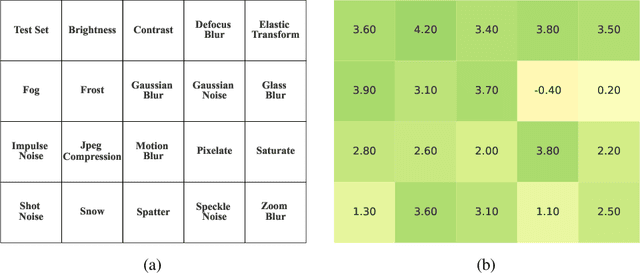
In this paper we study the effects of quantization in DNN training. We hypothesize that weight quantization is a form of regularization and the amount of regularization is correlated with the quantization level (precision). We confirm our hypothesis by providing analytical study and empirical results. By modeling weight quantization as a form of additive noise to weights, we explore how this noise propagates through the network at training time. We then show that the magnitude of this noise is correlated with the level of quantization. To confirm our analytical study, we performed an extensive list of experiments summarized in this paper in which we show that the regularization effects of quantization can be seen in various vision tasks and models, over various datasets. Based on our study, we propose that 8-bit quantization provides a reliable form of regularization in different vision tasks and models.
LEAD: Least-Action Dynamics for Min-Max Optimization
Oct 26, 2020



Adversarial formulations in machine learning have rekindled interest in differentiable games. The development of efficient optimization methods for two-player min-max games is an active area of research with a timely impact on adversarial formulations including generative adversarial networks (GANs). Existing methods for this type of problem typically employ intuitive, carefully hand-designed mechanisms for controlling the problematic rotational dynamics commonly encountered during optimization. In this work, we take a novel approach to address this issue by casting min-max optimization as a physical system. We propose LEAD (Least-Action Dynamics), a second-order optimizer that uses the principle of least-action from physics to discover an efficient optimizer for min-max games. We subsequently provide convergence analysis of our optimizer in quadratic min-max games using the Lyapunov theory. Finally, we empirically test our method on synthetic problems and GANs to demonstrate improvements over baseline methods.
Negative Momentum for Improved Game Dynamics
Jul 12, 2018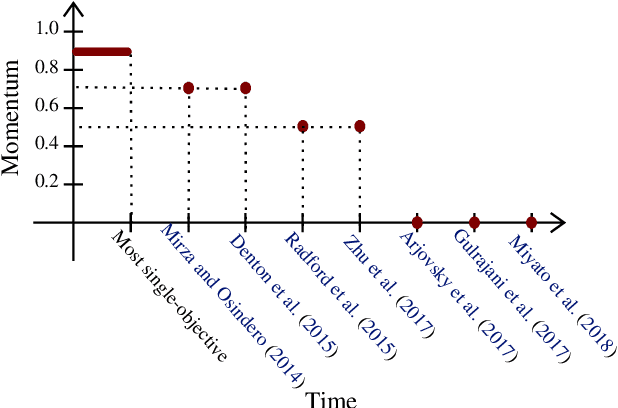

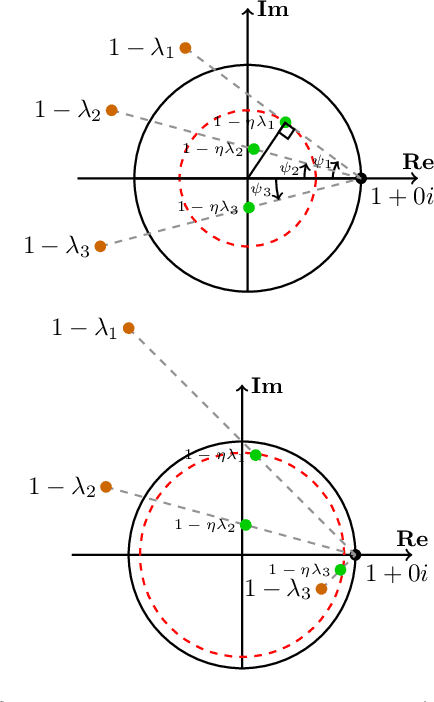
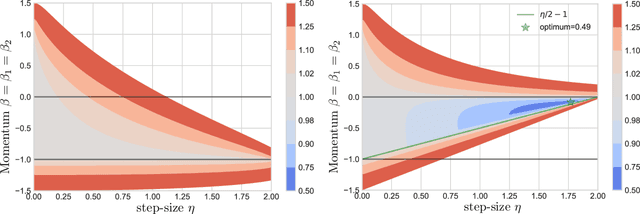
Games generalize the optimization paradigm by introducing different objective functions for different optimizing agents, known as players. Generative Adversarial Networks (GANs) are arguably the most popular game formulation in recent machine learning literature. GANs achieve great results on generating realistic natural images, however they are known for being difficult to train. Training them involves finding a Nash equilibrium, typically performed using gradient descent on the two players' objectives. Game dynamics can induce rotations that slow down convergence to a Nash equilibrium, or prevent it altogether. We provide a theoretical analysis of the game dynamics. Our analysis, supported by experiments, shows that gradient descent with a negative momentum term can improve the convergence properties of some GANs.
SLA Violation Prediction In Cloud Computing: A Machine Learning Perspective
Nov 30, 2016



Service level agreement (SLA) is an essential part of cloud systems to ensure maximum availability of services for customers. With a violation of SLA, the provider has to pay penalties. In this paper, we explore two machine learning models: Naive Bayes and Random Forest Classifiers to predict SLA violations. Since SLA violations are a rare event in the real world (~0.2 %), the classification task becomes more challenging. In order to overcome these challenges, we use several re-sampling methods. We find that random forests with SMOTE-ENN re-sampling have the best performance among other methods with the accuracy of 99.88 % and F_1 score of 0.9980.