 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRie Johnson
Inconsistency, Instability, and Generalization Gap of Deep Neural Network Training
May 31, 2023

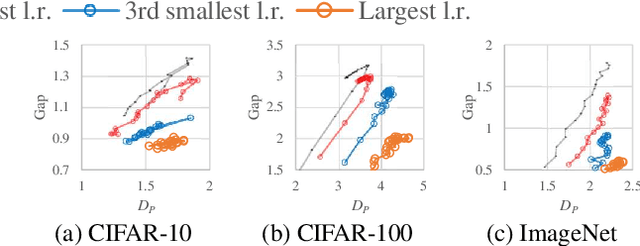
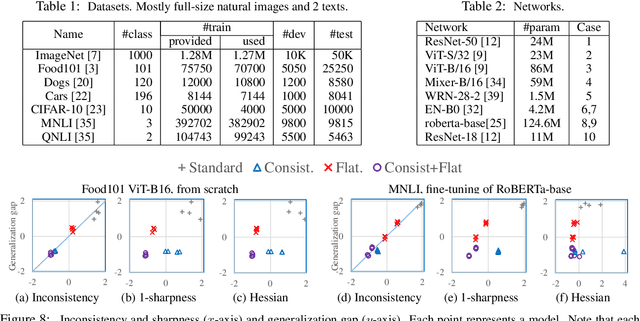
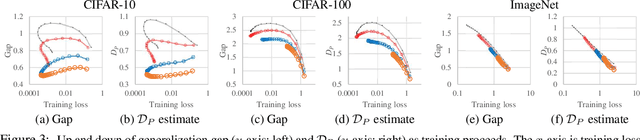
As deep neural networks are highly expressive, it is important to find solutions with small generalization gap (the difference between the performance on the training data and unseen data). Focusing on the stochastic nature of training, we first present a theoretical analysis in which the bound of generalization gap depends on what we call inconsistency and instability of model outputs, which can be estimated on unlabeled data. Our empirical study based on this analysis shows that instability and inconsistency are strongly predictive of generalization gap in various settings. In particular, our finding indicates that inconsistency is a more reliable indicator of generalization gap than the sharpness of the loss landscape. Furthermore, we show that algorithmic reduction of inconsistency leads to superior performance. The results also provide a theoretical basis for existing methods such as co-distillation and ensemble.
Guided Learning of Nonconvex Models through Successive Functional Gradient Optimization
Jun 30, 2020
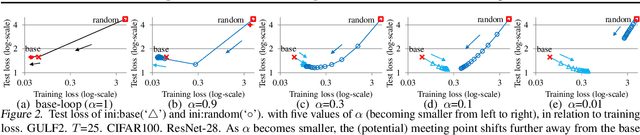
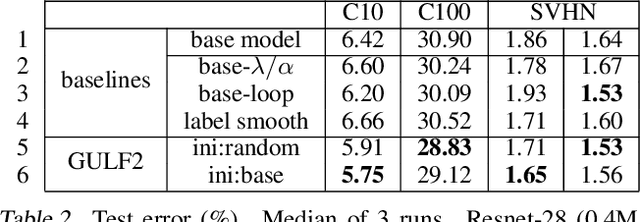
This paper presents a framework of successive functional gradient optimization for training nonconvex models such as neural networks, where training is driven by mirror descent in a function space. We provide a theoretical analysis and empirical study of the training method derived from this framework. It is shown that the method leads to better performance than that of standard training techniques.
Composite Functional Gradient Learning of Generative Adversarial Models
Jun 08, 2018



This paper first presents a theory for generative adversarial methods that does not rely on the traditional minimax formulation. It shows that with a strong discriminator, a good generator can be learned so that the KL divergence between the distributions of real data and generated data improves after each functional gradient step until it converges to zero. Based on the theory, we propose a new stable generative adversarial method. A theoretical insight into the original GAN from this new viewpoint is also provided. The experiments on image generation show the effectiveness of our new method.
Convolutional Neural Networks for Text Categorization: Shallow Word-level vs. Deep Character-level
Aug 31, 2016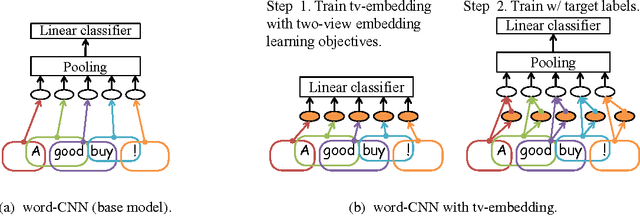



This paper reports the performances of shallow word-level convolutional neural networks (CNN), our earlier work (2015), on the eight datasets with relatively large training data that were used for testing the very deep character-level CNN in Conneau et al. (2016). Our findings are as follows. The shallow word-level CNNs achieve better error rates than the error rates reported in Conneau et al., though the results should be interpreted with some consideration due to the unique pre-processing of Conneau et al. The shallow word-level CNN uses more parameters and therefore requires more storage than the deep character-level CNN; however, the shallow word-level CNN computes much faster.
Supervised and Semi-Supervised Text Categorization using LSTM for Region Embeddings
May 26, 2016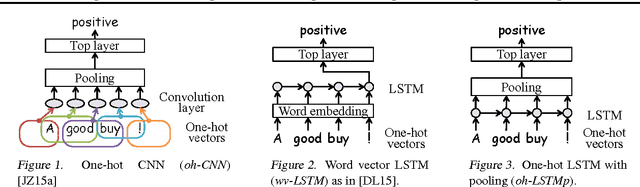
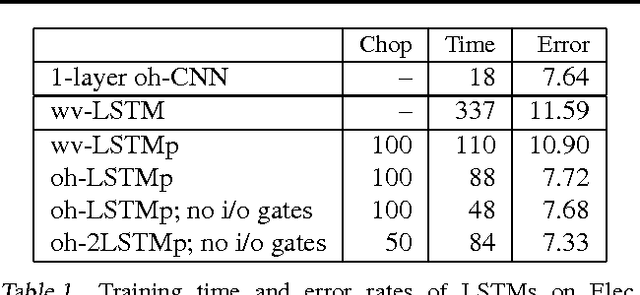
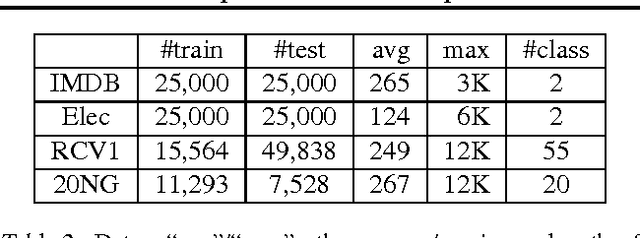
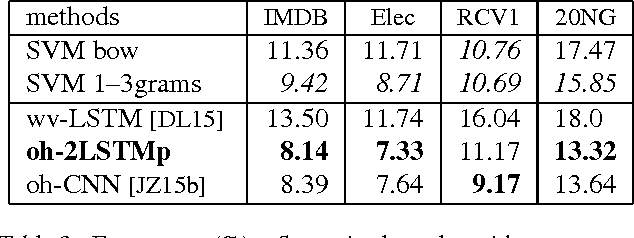
One-hot CNN (convolutional neural network) has been shown to be effective for text categorization (Johnson & Zhang, 2015). We view it as a special case of a general framework which jointly trains a linear model with a non-linear feature generator consisting of `text region embedding + pooling'. Under this framework, we explore a more sophisticated region embedding method using Long Short-Term Memory (LSTM). LSTM can embed text regions of variable (and possibly large) sizes, whereas the region size needs to be fixed in a CNN. We seek effective and efficient use of LSTM for this purpose in the supervised and semi-supervised settings. The best results were obtained by combining region embeddings in the form of LSTM and convolution layers trained on unlabeled data. The results indicate that on this task, embeddings of text regions, which can convey complex concepts, are more useful than embeddings of single words in isolation. We report performances exceeding the previous best results on four benchmark datasets.
Semi-supervised Convolutional Neural Networks for Text Categorization via Region Embedding
Nov 01, 2015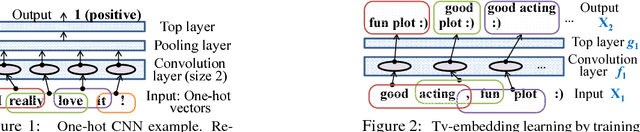

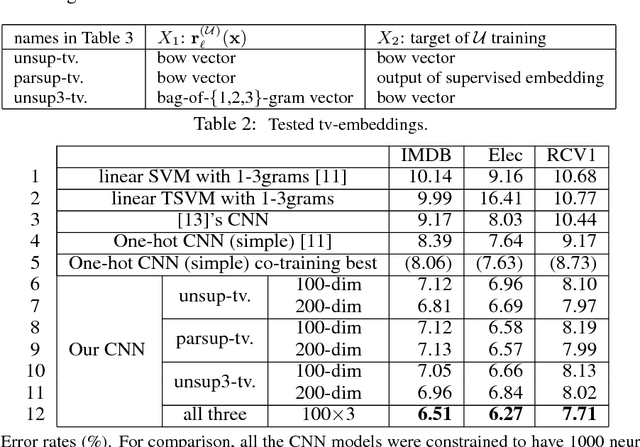
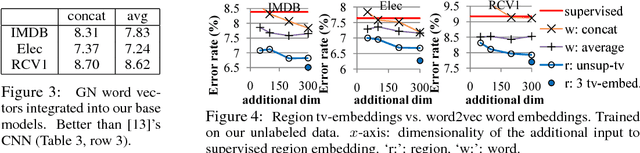
This paper presents a new semi-supervised framework with convolutional neural networks (CNNs) for text categorization. Unlike the previous approaches that rely on word embeddings, our method learns embeddings of small text regions from unlabeled data for integration into a supervised CNN. The proposed scheme for embedding learning is based on the idea of two-view semi-supervised learning, which is intended to be useful for the task of interest even though the training is done on unlabeled data. Our models achieve better results than previous approaches on sentiment classification and topic classification tasks.
Effective Use of Word Order for Text Categorization with Convolutional Neural Networks
Mar 26, 2015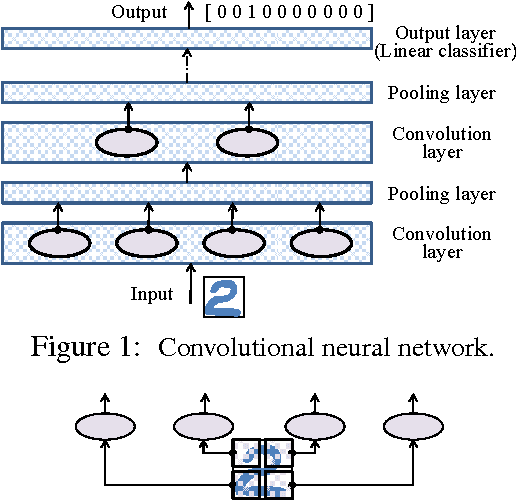
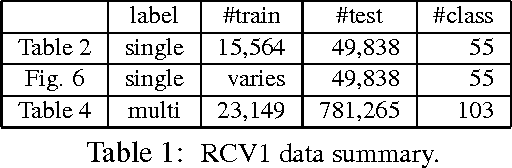
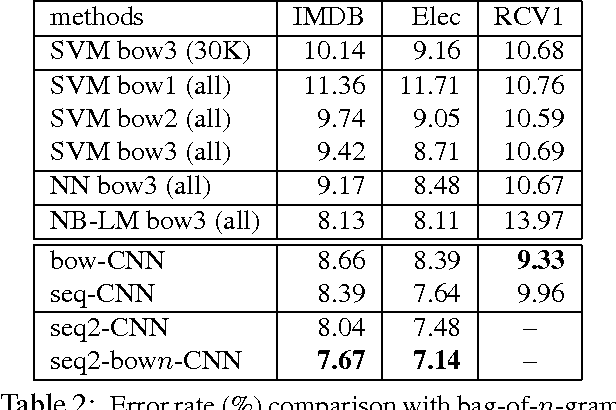
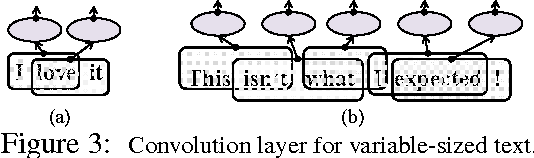
Convolutional neural network (CNN) is a neural network that can make use of the internal structure of data such as the 2D structure of image data. This paper studies CNN on text categorization to exploit the 1D structure (namely, word order) of text data for accurate prediction. Instead of using low-dimensional word vectors as input as is often done, we directly apply CNN to high-dimensional text data, which leads to directly learning embedding of small text regions for use in classification. In addition to a straightforward adaptation of CNN from image to text, a simple but new variation which employs bag-of-word conversion in the convolution layer is proposed. An extension to combine multiple convolution layers is also explored for higher accuracy. The experiments demonstrate the effectiveness of our approach in comparison with state-of-the-art methods.
Learning Nonlinear Functions Using Regularized Greedy Forest
Jun 28, 2014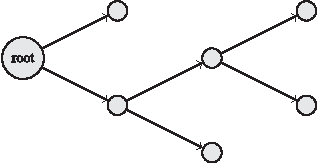
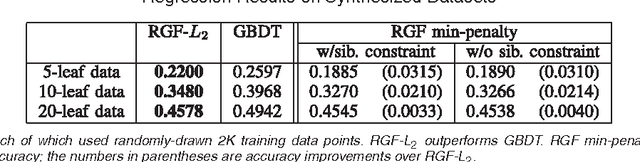
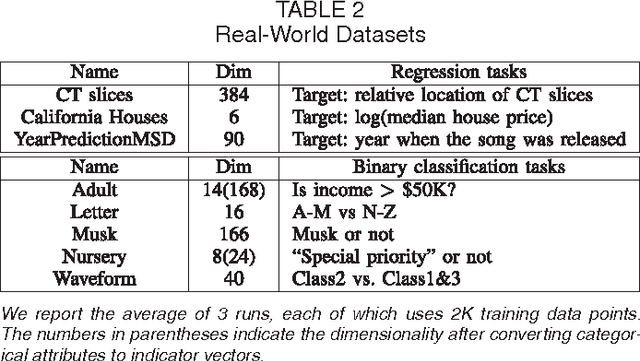
We consider the problem of learning a forest of nonlinear decision rules with general loss functions. The standard methods employ boosted decision trees such as Adaboost for exponential loss and Friedman's gradient boosting for general loss. In contrast to these traditional boosting algorithms that treat a tree learner as a black box, the method we propose directly learns decision forests via fully-corrective regularized greedy search using the underlying forest structure. Our method achieves higher accuracy and smaller models than gradient boosting (and Adaboost with exponential loss) on many datasets.