 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobert P. Dick
How Capable Can a Transformer Become? A Study on Synthetic, Interpretable Tasks
Nov 21, 2023
Transformers trained on huge text corpora exhibit a remarkable set of capabilities, e.g., performing simple logical operations. Given the inherent compositional nature of language, one can expect the model to learn to compose these capabilities, potentially yielding a combinatorial explosion of what operations it can perform on an input. Motivated by the above, we aim to assess in this paper "how capable can a transformer become?". Specifically, we train autoregressive Transformer models on a data-generating process that involves compositions of a set of well-defined monolithic capabilities. Through a series of extensive and systematic experiments on this data-generating process, we show that: (1) autoregressive Transformers can learn compositional structures from the training data and generalize to exponentially or even combinatorially many functions; (2) composing functions by generating intermediate outputs is more effective at generalizing to unseen compositions, compared to generating no intermediate outputs; (3) the training data has a significant impact on the model's ability to compose unseen combinations of functions; and (4) the attention layers in the latter half of the model are critical to compositionality.
Mechanistically analyzing the effects of fine-tuning on procedurally defined tasks
Nov 21, 2023Fine-tuning large pre-trained models has become the de facto strategy for developing both task-specific and general-purpose machine learning systems, including developing models that are safe to deploy. Despite its clear importance, there has been minimal work that explains how fine-tuning alters the underlying capabilities learned by a model during pretraining: does fine-tuning yield entirely novel capabilities or does it just modulate existing ones? We address this question empirically in synthetic, controlled settings where we can use mechanistic interpretability tools (e.g., network pruning and probing) to understand how the model's underlying capabilities are changing. We perform an extensive analysis of the effects of fine-tuning in these settings, and show that: (i) fine-tuning rarely alters the underlying model capabilities; (ii) a minimal transformation, which we call a 'wrapper', is typically learned on top of the underlying model capabilities, creating the illusion that they have been modified; and (iii) further fine-tuning on a task where such hidden capabilities are relevant leads to sample-efficient 'revival' of the capability, i.e., the model begins reusing these capability after only a few gradient steps. This indicates that practitioners can unintentionally remove a model's safety wrapper merely by fine-tuning it on a, e.g., superficially unrelated, downstream task. We additionally perform analysis on language models trained on the TinyStories dataset to support our claims in a more realistic setup.
In-Context Learning Dynamics with Random Binary Sequences
Oct 26, 2023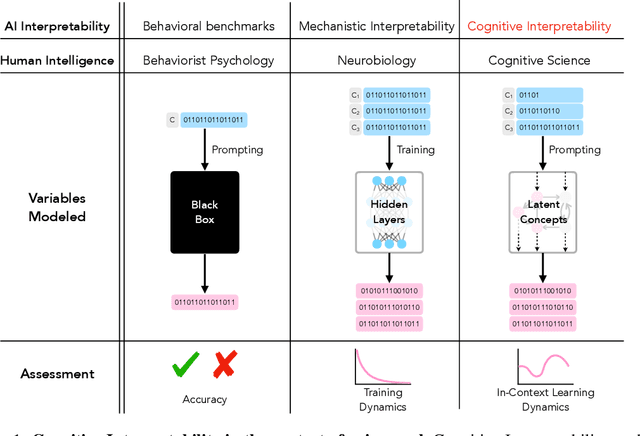
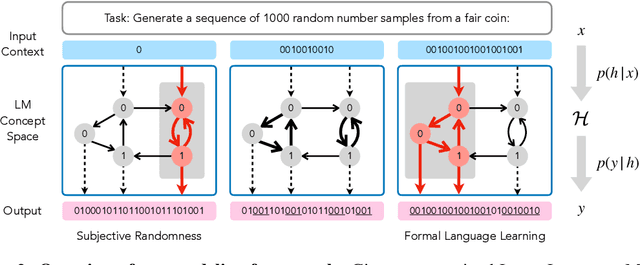
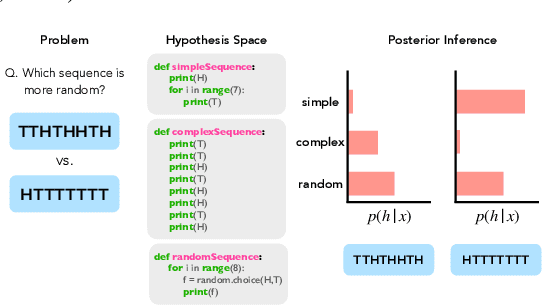
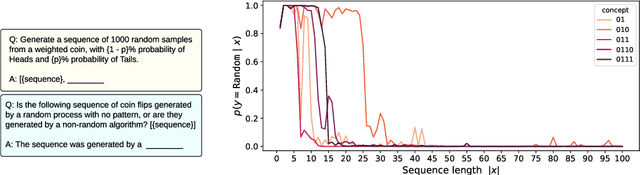
Large language models (LLMs) trained on huge corpora of text datasets demonstrate complex, emergent capabilities, achieving state-of-the-art performance on tasks they were not explicitly trained for. The precise nature of LLM capabilities is often mysterious, and different prompts can elicit different capabilities through in-context learning. We propose a Cognitive Interpretability framework that enables us to analyze in-context learning dynamics to understand latent concepts in LLMs underlying behavioral patterns. This provides a more nuanced understanding than success-or-failure evaluation benchmarks, but does not require observing internal activations as a mechanistic interpretation of circuits would. Inspired by the cognitive science of human randomness perception, we use random binary sequences as context and study dynamics of in-context learning by manipulating properties of context data, such as sequence length. In the latest GPT-3.5+ models, we find emergent abilities to generate pseudo-random numbers and learn basic formal languages, with striking in-context learning dynamics where model outputs transition sharply from pseudo-random behaviors to deterministic repetition.
Compositional Abilities Emerge Multiplicatively: Exploring Diffusion Models on a Synthetic Task
Oct 13, 2023
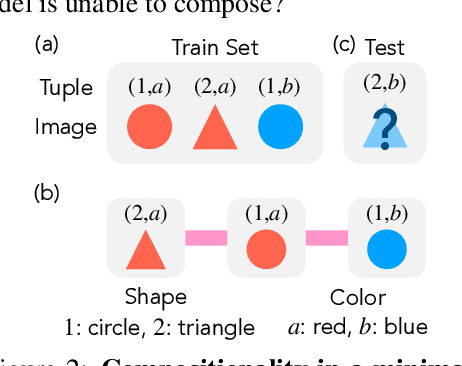


Modern generative models exhibit unprecedented capabilities to generate extremely realistic data. However, given the inherent compositionality of the real world, reliable use of these models in practical applications requires that they exhibit the capability to compose a novel set of concepts to generate outputs not seen in the training data set. Prior work demonstrates that recent diffusion models do exhibit intriguing compositional generalization abilities, but also fail unpredictably. Motivated by this, we perform a controlled study for understanding compositional generalization in conditional diffusion models in a synthetic setting, varying different attributes of the training data and measuring the model's ability to generate samples out-of-distribution. Our results show: (i) the order in which the ability to generate samples from a concept and compose them emerges is governed by the structure of the underlying data-generating process; (ii) performance on compositional tasks exhibits a sudden ``emergence'' due to multiplicative reliance on the performance of constituent tasks, partially explaining emergent phenomena seen in generative models; and (iii) composing concepts with lower frequency in the training data to generate out-of-distribution samples requires considerably more optimization steps compared to generating in-distribution samples. Overall, our study lays a foundation for understanding capabilities and compositionality in generative models from a data-centric perspective.
Mechanistic Mode Connectivity
Nov 15, 2022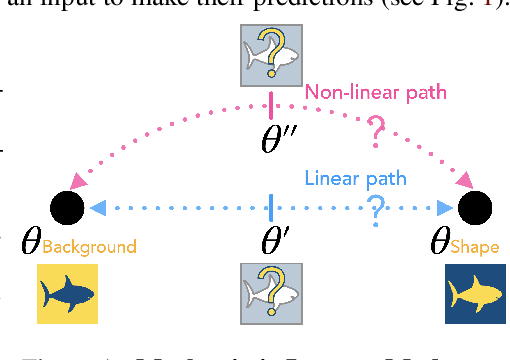


Neural networks are known to be biased towards learning mechanisms that help identify $spurious\, attributes$, yielding features that do not generalize well under distribution shifts. To understand and address this limitation, we study the geometry of neural network loss landscapes through the lens of $mode\, connectivity$, the observation that minimizers of neural networks are connected via simple paths of low loss. Our work addresses two questions: (i) do minimizers that encode dissimilar mechanisms connect via simple paths of low loss? (ii) can fine-tuning a pretrained model help switch between such minimizers? We define a notion of $\textit{mechanistic similarity}$ and demonstrate that lack of linear connectivity between two minimizers implies the corresponding models use dissimilar mechanisms for making their predictions. This property helps us demonstrate that na$\"{i}$ve fine-tuning can fail to eliminate a model's reliance on spurious attributes. We thus propose a method for altering a model's mechanisms, named $connectivity$-$based$ $fine$-$tuning$, and validate its usefulness by inducing models invariant to spurious attributes.
Orchestra: Unsupervised Federated Learning via Globally Consistent Clustering
May 23, 2022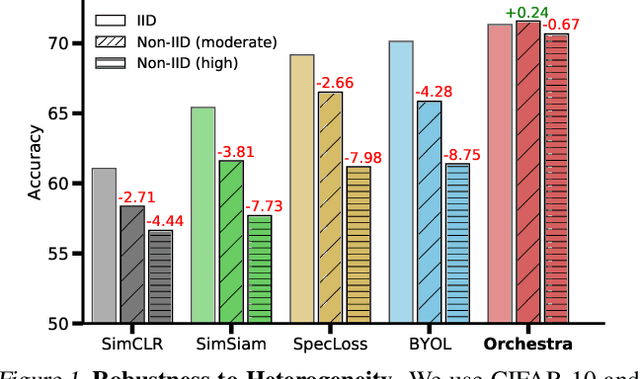

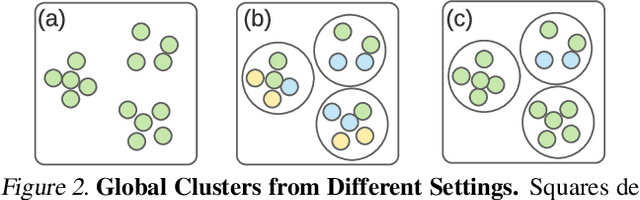

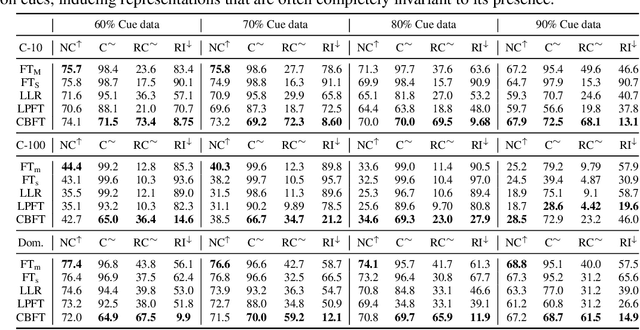
Federated learning is generally used in tasks where labels are readily available (e.g., next word prediction). Relaxing this constraint requires design of unsupervised learning techniques that can support desirable properties for federated training: robustness to statistical/systems heterogeneity, scalability with number of participants, and communication efficiency. Prior work on this topic has focused on directly extending centralized self-supervised learning techniques, which are not designed to have the properties listed above. To address this situation, we propose Orchestra, a novel unsupervised federated learning technique that exploits the federation's hierarchy to orchestrate a distributed clustering task and enforce a globally consistent partitioning of clients' data into discriminable clusters. We show the algorithmic pipeline in Orchestra guarantees good generalization performance under a linear probe, allowing it to outperform alternative techniques in a broad range of conditions, including variation in heterogeneity, number of clients, participation ratio, and local epochs.
Do Smart Glasses Dream of Sentimental Visions? Deep Emotionship Analysis for Eyewear Devices
Jan 24, 2022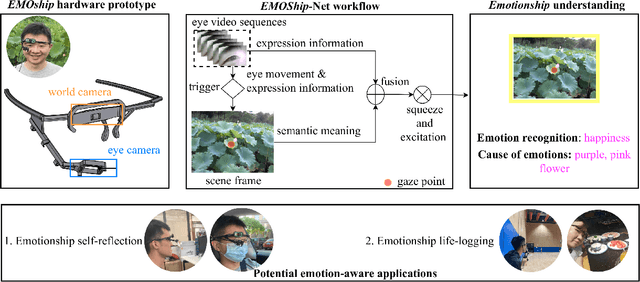

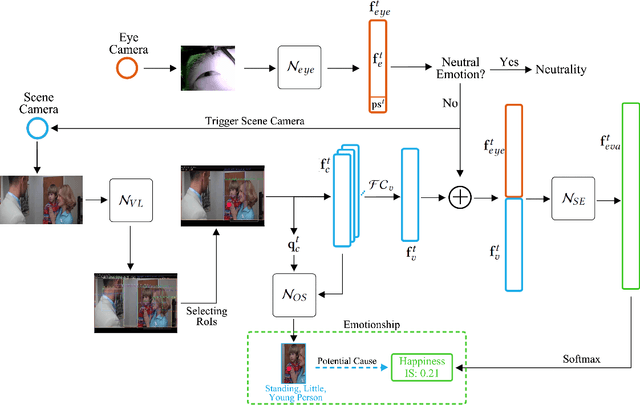
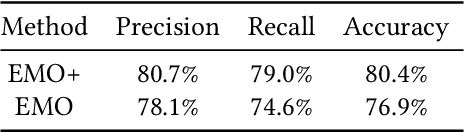
Emotion recognition in smart eyewear devices is highly valuable but challenging. One key limitation of previous works is that the expression-related information like facial or eye images is considered as the only emotional evidence. However, emotional status is not isolated; it is tightly associated with people's visual perceptions, especially those sentimental ones. However, little work has examined such associations to better illustrate the cause of different emotions. In this paper, we study the emotionship analysis problem in eyewear systems, an ambitious task that requires not only classifying the user's emotions but also semantically understanding the potential cause of such emotions. To this end, we devise EMOShip, a deep-learning-based eyewear system that can automatically detect the wearer's emotional status and simultaneously analyze its associations with semantic-level visual perceptions. Experimental studies with 20 participants demonstrate that, thanks to the emotionship awareness, EMOShip not only achieves superior emotion recognition accuracy over existing methods (80.2% vs. 69.4%), but also provides a valuable understanding of the cause of emotions. Pilot studies with 20 participants further motivate the potential use of EMOShip to empower emotion-aware applications, such as emotionship self-reflection and emotionship life-logging.
Beyond BatchNorm: Towards a General Understanding of Normalization in Deep Learning
Jul 08, 2021

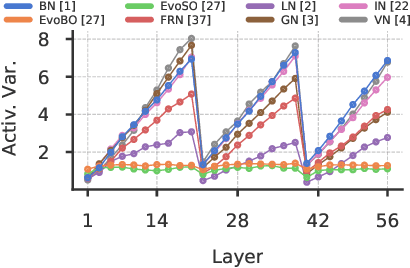
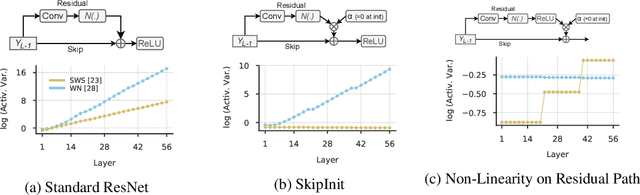
Inspired by BatchNorm, there has been an explosion of normalization layers for deep neural networks (DNNs). However, these alternative normalization layers have seen minimal use, partially due to a lack of guiding principles that can help identify when these layers can serve as a replacement for BatchNorm. To address this problem, we take a theoretical approach, generalizing the known beneficial mechanisms of BatchNorm to several recently proposed normalization techniques. Our generalized theory leads to the following set of principles: (i) similar to BatchNorm, activations-based normalization layers can prevent exponential growth of activations in ResNets, but parametric layers require explicit remedies; (ii) use of GroupNorm can ensure informative forward propagation, with different samples being assigned dissimilar activations, but increasing group size results in increasingly indistinguishable activations for different samples, explaining slow convergence speed in models with LayerNorm; (iii) small group sizes result in large gradient norm in earlier layers, hence explaining training instability issues in Instance Normalization and illustrating a speed-stability tradeoff in GroupNorm. Overall, our analysis reveals a unified set of mechanisms that underpin the success of normalization methods in deep learning, providing us with a compass to systematically explore the vast design space of DNN normalization layers.
MemX: An Attention-Aware Smart Eyewear System for Personalized Moment Auto-capture
May 03, 2021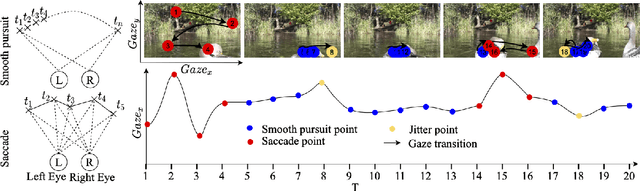

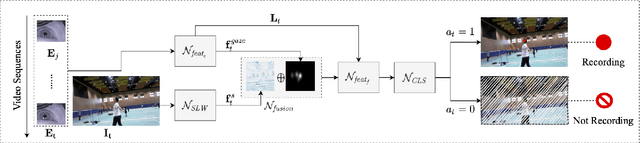
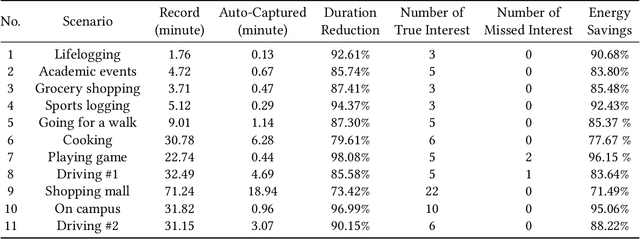
This work presents MemX: a biologically-inspired attention-aware eyewear system developed with the goal of pursuing the long-awaited vision of a personalized visual Memex. MemX captures human visual attention on the fly, analyzes the salient visual content, and records moments of personal interest in the form of compact video snippets. Accurate attentive scene detection and analysis on resource-constrained platforms is challenging because these tasks are computation and energy intensive. We propose a new temporal visual attention network that unifies human visual attention tracking and salient visual content analysis. Attention tracking focuses computation-intensive video analysis on salient regions, while video analysis makes human attention detection and tracking more accurate. Using the YouTube-VIS dataset and 30 participants, we experimentally show that MemX significantly improves the attention tracking accuracy over the eye-tracking-alone method, while maintaining high system energy efficiency. We have also conducted 11 in-field pilot studies across a range of daily usage scenarios, which demonstrate the feasibility and potential benefits of MemX.
A Reinforcement-Learning-Based Energy-Efficient Framework for Multi-Task Video Analytics Pipeline
May 02, 2021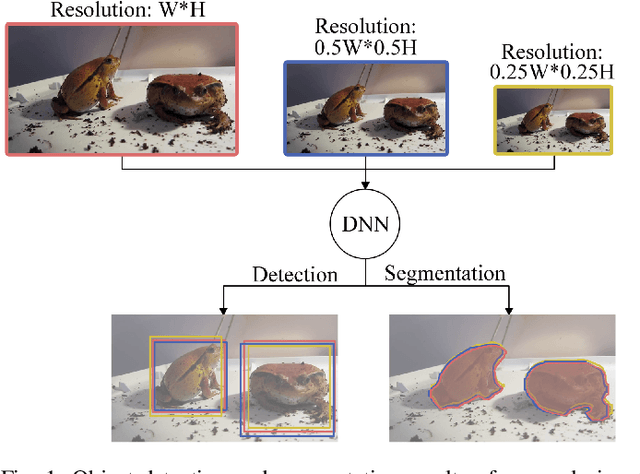
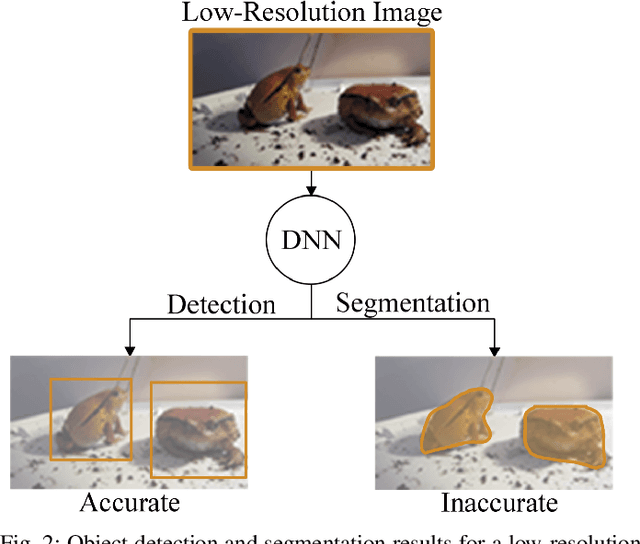
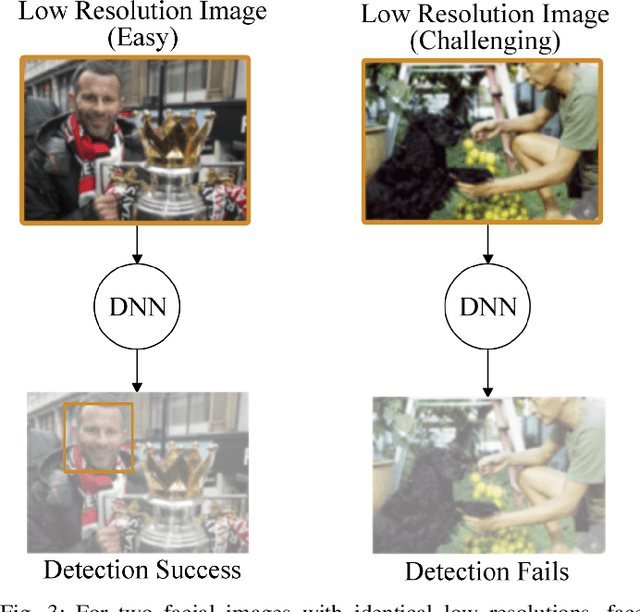
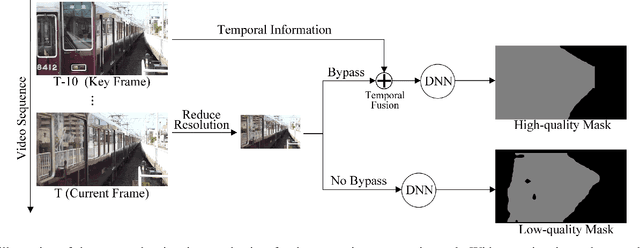
Deep-learning-based video processing has yielded transformative results in recent years. However, the video analytics pipeline is energy-intensive due to high data rates and reliance on complex inference algorithms, which limits its adoption in energy-constrained applications. Motivated by the observation of high and variable spatial redundancy and temporal dynamics in video data streams, we design and evaluate an adaptive-resolution optimization framework to minimize the energy use of multi-task video analytics pipelines. Instead of heuristically tuning the input data resolution of individual tasks, our framework utilizes deep reinforcement learning to dynamically govern the input resolution and computation of the entire video analytics pipeline. By monitoring the impact of varying resolution on the quality of high-dimensional video analytics features, hence the accuracy of video analytics results, the proposed end-to-end optimization framework learns the best non-myopic policy for dynamically controlling the resolution of input video streams to globally optimize energy efficiency. Governed by reinforcement learning, optical flow is incorporated into the framework to minimize unnecessary spatio-temporal redundancy that leads to re-computation, while preserving accuracy. The proposed framework is applied to video instance segmentation which is one of the most challenging computer vision tasks, and achieves better energy efficiency than all baseline methods of similar accuracy on the YouTube-VIS dataset.