 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoberto Molinaro
Are Neural Operators Really Neural Operators? Frame Theory Meets Operator Learning
May 31, 2023
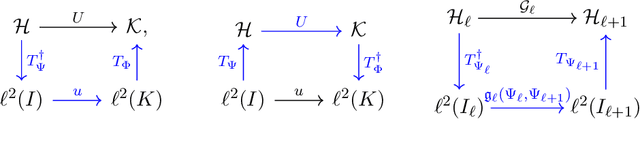
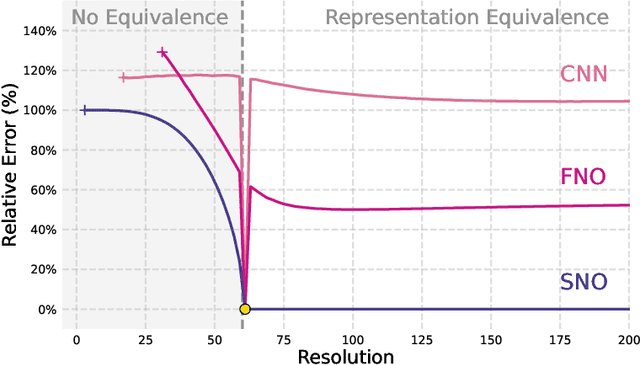
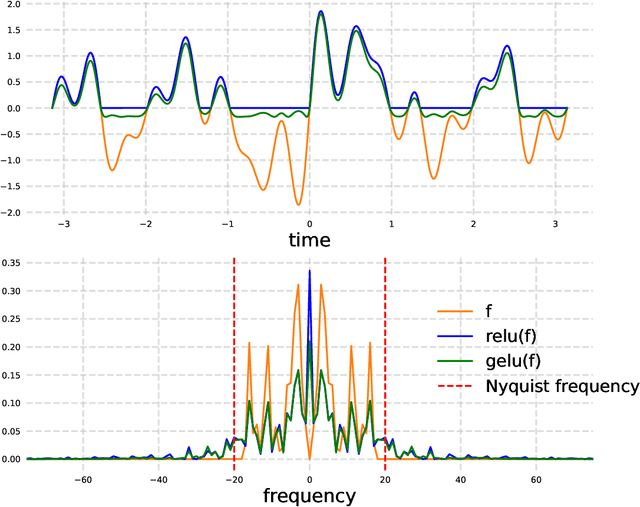
Recently, there has been significant interest in operator learning, i.e. learning mappings between infinite-dimensional function spaces. This has been particularly relevant in the context of learning partial differential equations from data. However, it has been observed that proposed models may not behave as operators when implemented on a computer, questioning the very essence of what operator learning should be. We contend that in addition to defining the operator at the continuous level, some form of continuous-discrete equivalence is necessary for an architecture to genuinely learn the underlying operator, rather than just discretizations of it. To this end, we propose to employ frames, a concept in applied harmonic analysis and signal processing that gives rise to exact and stable discrete representations of continuous signals. Extending these concepts to operators, we introduce a unifying mathematical framework of Representation equivalent Neural Operator (ReNO) to ensure operations at the continuous and discrete level are equivalent. Lack of this equivalence is quantified in terms of aliasing errors. We analyze various existing operator learning architectures to determine whether they fall within this framework, and highlight implications when they fail to do so.
Convolutional Neural Operators
Feb 02, 2023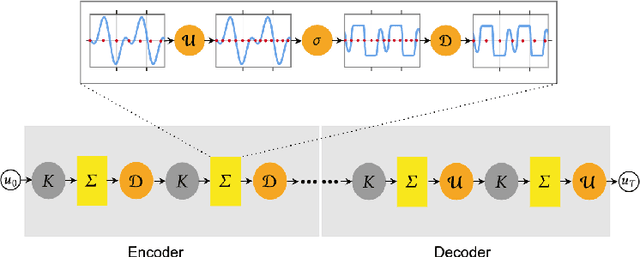
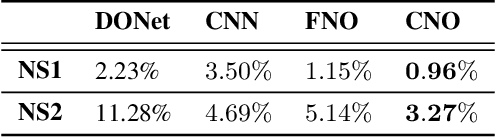
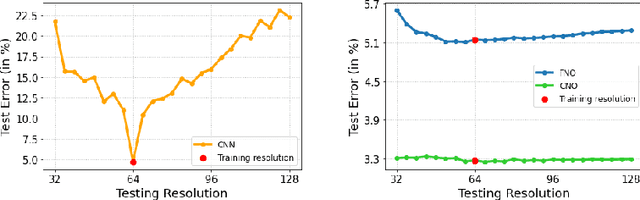

Although very successfully used in machine learning, convolution based neural network architectures -- believed to be inconsistent in function space -- have been largely ignored in the context of learning solution operators of PDEs. Here, we adapt convolutional neural networks to demonstrate that they are indeed able to process functions as inputs and outputs. The resulting architecture, termed as convolutional neural operators (CNOs), is shown to significantly outperform competing models on benchmark experiments, paving the way for the design of an alternative robust and accurate framework for learning operators.
Neural Inverse Operators for Solving PDE Inverse Problems
Jan 26, 2023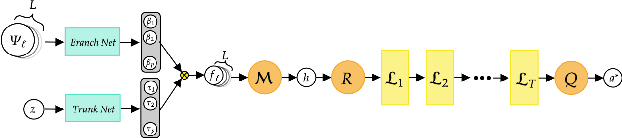
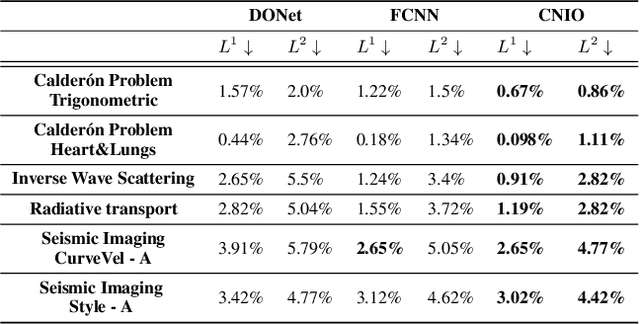

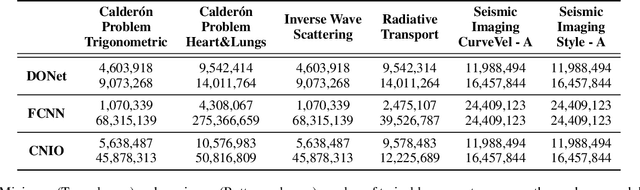
A large class of inverse problems for PDEs are only well-defined as mappings from operators to functions. Existing operator learning frameworks map functions to functions and need to be modified to learn inverse maps from data. We propose a novel architecture termed Neural Inverse Operators (NIOs) to solve these PDE inverse problems. Motivated by the underlying mathematical structure, NIO is based on a suitable composition of DeepONets and FNOs to approximate mappings from operators to functions. A variety of experiments are presented to demonstrate that NIOs significantly outperform baselines and solve PDE inverse problems robustly, accurately and are several orders of magnitude faster than existing direct and PDE-constrained optimization methods.
Nonlinear Reconstruction for Operator Learning of PDEs with Discontinuities
Oct 03, 2022



A large class of hyperbolic and advection-dominated PDEs can have solutions with discontinuities. This paper investigates, both theoretically and empirically, the operator learning of PDEs with discontinuous solutions. We rigorously prove, in terms of lower approximation bounds, that methods which entail a linear reconstruction step (e.g. DeepONet or PCA-Net) fail to efficiently approximate the solution operator of such PDEs. In contrast, we show that certain methods employing a non-linear reconstruction mechanism can overcome these fundamental lower bounds and approximate the underlying operator efficiently. The latter class includes Fourier Neural Operators and a novel extension of DeepONet termed shift-DeepONet. Our theoretical findings are confirmed by empirical results for advection equation, inviscid Burgers' equation and compressible Euler equations of aerodynamics.
wPINNs: Weak Physics informed neural networks for approximating entropy solutions of hyperbolic conservation laws
Jul 18, 2022



Physics informed neural networks (PINNs) require regularity of solutions of the underlying PDE to guarantee accurate approximation. Consequently, they may fail at approximating discontinuous solutions of PDEs such as nonlinear hyperbolic equations. To ameliorate this, we propose a novel variant of PINNs, termed as weak PINNs (wPINNs) for accurate approximation of entropy solutions of scalar conservation laws. wPINNs are based on approximating the solution of a min-max optimization problem for a residual, defined in terms of Kruzkhov entropies, to determine parameters for the neural networks approximating the entropy solution as well as test functions. We prove rigorous bounds on the error incurred by wPINNs and illustrate their performance through numerical experiments to demonstrate that wPINNs can approximate entropy solutions accurately.
Physics Informed Neural Networks for Simulating Radiative Transfer
Sep 25, 2020



We propose a novel machine learning algorithm for simulating radiative transfer. Our algorithm is based on physics informed neural networks (PINNs), which are trained by minimizing the residual of the underlying radiative tranfer equations. We present extensive experiments and theoretical error estimates to demonstrate that PINNs provide a very easy to implement, fast, robust and accurate method for simulating radiative transfer. We also present a PINN based algorithm for simulating inverse problems for radiative transfer efficiently.
Estimates on the generalization error of Physics Informed Neural Networks (PINNs) for approximating PDEs II: A class of inverse problems
Jun 29, 2020



Physics informed neural networks (PINNs) have recently been very successfully applied for efficiently approximating inverse problems for PDEs. We focus on a particular class of inverse problems, the so-called data assimilation or unique continuation problems, and prove rigorous estimates on the generalization error of PINNs approximating them. An abstract framework is presented and conditional stability estimates for the underlying inverse problem are employed to derive the estimate on the PINN generalization error, providing rigorous justification for the use of PINNs in this context. The abstract framework is illustrated with examples of four prototypical linear PDEs. Numerical experiments, validating the proposed theory, are also presented.
Estimates on the generalization error of Physics Informed Neural Networks (PINNs) for approximating PDEs
Jun 29, 2020Physics informed neural networks (PINNs) have recently been widely used for robust and accurate approximation of PDEs. We provide rigorous upper bounds on the generalization error of PINNs approximating solutions of the forward problem for PDEs. An abstract formalism is introduced and stability properties of the underlying PDE are leveraged to derive an estimate for the generalization error in terms of the training error and number of training samples. This abstract framework is illustrated with several examples of nonlinear PDEs. Numerical experiments, validating the proposed theory, are also presented.
A Multi-level procedure for enhancing accuracy of machine learning algorithms
Sep 20, 2019
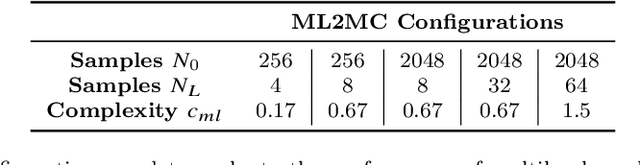


We propose a multi-level method to increase the accuracy of machine learning algorithms for approximating observables in scientific computing, particularly those that arise in systems modeled by differential equations. The algorithm relies on judiciously combining a large number of computationally cheap training data on coarse resolutions with a few expensive training samples on fine grid resolutions. Theoretical arguments for lowering the generalization error, based on reducing the variance of the underlying maps, are provided and numerical evidence, indicating significant gains over underlying single-level machine learning algorithms, are presented. Moreover, we also apply the multi-level algorithm in the context of forward uncertainty quantification and observe a considerable speed-up over competing algorithms.