 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoi Reichart
The Colorful Future of LLMs: Evaluating and Improving LLMs as Emotional Supporters for Queer Youth
Feb 19, 2024
Queer youth face increased mental health risks, such as depression, anxiety, and suicidal ideation. Hindered by negative stigma, they often avoid seeking help and rely on online resources, which may provide incompatible information. Although access to a supportive environment and reliable information is invaluable, many queer youth worldwide have no access to such support. However, this could soon change due to the rapid adoption of Large Language Models (LLMs) such as ChatGPT. This paper aims to comprehensively explore the potential of LLMs to revolutionize emotional support for queers. To this end, we conduct a qualitative and quantitative analysis of LLM's interactions with queer-related content. To evaluate response quality, we develop a novel ten-question scale that is inspired by psychological standards and expert input. We apply this scale to score several LLMs and human comments to posts where queer youth seek advice and share experiences. We find that LLM responses are supportive and inclusive, outscoring humans. However, they tend to be generic, not empathetic enough, and lack personalization, resulting in nonreliable and potentially harmful advice. We discuss these challenges, demonstrate that a dedicated prompt can improve the performance, and propose a blueprint of an LLM-supporter that actively (but sensitively) seeks user context to provide personalized, empathetic, and reliable responses. Our annotated dataset is available for further research.
Systematic Biases in LLM Simulations of Debates
Feb 06, 2024Recent advancements in natural language processing, especially the emergence of Large Language Models (LLMs), have opened exciting possibilities for constructing computational simulations designed to replicate human behavior accurately. However, LLMs are complex statistical learners without straightforward deductive rules, making them prone to unexpected behaviors. In this study, we highlight the limitations of LLMs in simulating human interactions, particularly focusing on LLMs' ability to simulate political debates. Our findings indicate a tendency for LLM agents to conform to the model's inherent social biases despite being directed to debate from certain political perspectives. This tendency results in behavioral patterns that seem to deviate from well-established social dynamics among humans. We reinforce these observations using an automatic self-fine-tuning method, which enables us to manipulate the biases within the LLM and demonstrate that agents subsequently align with the altered biases. These results underscore the need for further research to develop methods that help agents overcome these biases, a critical step toward creating more realistic simulations.
Can Large Language Models Replace Economic Choice Prediction Labs?
Feb 01, 2024Economic choice prediction is an essential challenging task, often constrained by the difficulties in acquiring human choice data. Indeed, experimental economics studies had focused mostly on simple choice settings. The AI community has recently contributed to that effort in two ways: considering whether LLMs can substitute for humans in the above-mentioned simple choice prediction settings, and the study through ML lens of more elaborated but still rigorous experimental economics settings, employing incomplete information, repetitive play, and natural language communication, notably language-based persuasion games. This leaves us with a major inspiration: can LLMs be used to fully simulate the economic environment and generate data for efficient human choice prediction, substituting for the elaborated economic lab studies? We pioneer the study of this subject, demonstrating its feasibility. In particular, we show that a model trained solely on LLM-generated data can effectively predict human behavior in a language-based persuasion game, and can even outperform models trained on actual human data.
Decoding Stumpers: Large Language Models vs. Human Problem-Solvers
Oct 25, 2023This paper investigates the problem-solving capabilities of Large Language Models (LLMs) by evaluating their performance on stumpers, unique single-step intuition problems that pose challenges for human solvers but are easily verifiable. We compare the performance of four state-of-the-art LLMs (Davinci-2, Davinci-3, GPT-3.5-Turbo, GPT-4) to human participants. Our findings reveal that the new-generation LLMs excel in solving stumpers and surpass human performance. However, humans exhibit superior skills in verifying solutions to the same problems. This research enhances our understanding of LLMs' cognitive abilities and provides insights for enhancing their problem-solving potential across various domains.
The Temporal Structure of Language Processing in the Human Brain Corresponds to The Layered Hierarchy of Deep Language Models
Oct 11, 2023Deep Language Models (DLMs) provide a novel computational paradigm for understanding the mechanisms of natural language processing in the human brain. Unlike traditional psycholinguistic models, DLMs use layered sequences of continuous numerical vectors to represent words and context, allowing a plethora of emerging applications such as human-like text generation. In this paper we show evidence that the layered hierarchy of DLMs may be used to model the temporal dynamics of language comprehension in the brain by demonstrating a strong correlation between DLM layer depth and the time at which layers are most predictive of the human brain. Our ability to temporally resolve individual layers benefits from our use of electrocorticography (ECoG) data, which has a much higher temporal resolution than noninvasive methods like fMRI. Using ECoG, we record neural activity from participants listening to a 30-minute narrative while also feeding the same narrative to a high-performing DLM (GPT2-XL). We then extract contextual embeddings from the different layers of the DLM and use linear encoding models to predict neural activity. We first focus on the Inferior Frontal Gyrus (IFG, or Broca's area) and then extend our model to track the increasing temporal receptive window along the linguistic processing hierarchy from auditory to syntactic and semantic areas. Our results reveal a connection between human language processing and DLMs, with the DLM's layer-by-layer accumulation of contextual information mirroring the timing of neural activity in high-order language areas.
Navigating Cultural Chasms: Exploring and Unlocking the Cultural POV of Text-To-Image Models
Oct 03, 2023Text-To-Image (TTI) models, exemplified by DALL-E and StableDiffusion, have recently gained prominence for their remarkable zero-shot capabilities in generating images guided by textual prompts. Language, as a conduit of culture, plays a pivotal role in these models' multilingual capabilities, which in turn shape their cultural agency. In this study, we explore the cultural perception embedded in TTI models by characterizing culture across three hierarchical tiers: cultural dimensions, cultural domains, and cultural concepts. We propose a comprehensive suite of evaluation techniques, including intrinsic evaluations using the CLIP space, extrinsic evaluations with a Visual-Question-Answer (VQA) model, and human assessments, to discern TTI cultural perceptions. To facilitate our research, we introduce the CulText2I dataset, derived from four diverse TTI models and spanning ten languages. Our experiments reveal insights into these models' cultural awareness, cultural distinctions, and the unlocking of cultural features, releasing the potential for cross-cultural applications.
Faithful Explanations of Black-box NLP Models Using LLM-generated Counterfactuals
Oct 01, 2023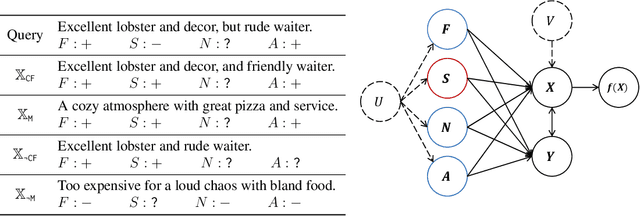
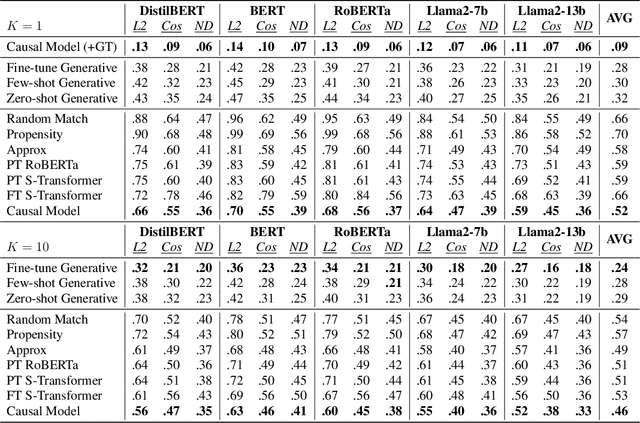
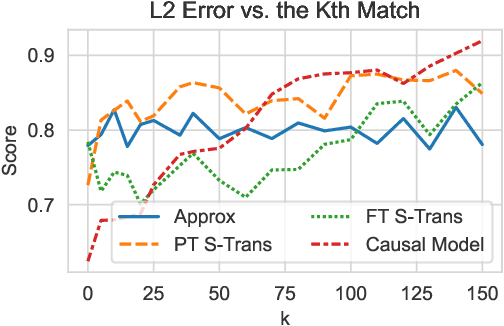
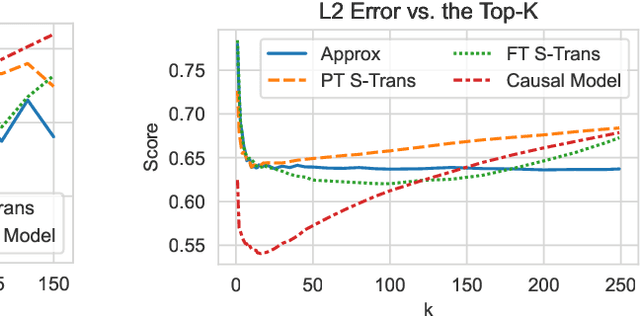
Causal explanations of the predictions of NLP systems are essential to ensure safety and establish trust. Yet, existing methods often fall short of explaining model predictions effectively or efficiently and are often model-specific. In this paper, we address model-agnostic explanations, proposing two approaches for counterfactual (CF) approximation. The first approach is CF generation, where a large language model (LLM) is prompted to change a specific text concept while keeping confounding concepts unchanged. While this approach is demonstrated to be very effective, applying LLM at inference-time is costly. We hence present a second approach based on matching, and propose a method that is guided by an LLM at training-time and learns a dedicated embedding space. This space is faithful to a given causal graph and effectively serves to identify matches that approximate CFs. After showing theoretically that approximating CFs is required in order to construct faithful explanations, we benchmark our approaches and explain several models, including LLMs with billions of parameters. Our empirical results demonstrate the excellent performance of CF generation models as model-agnostic explainers. Moreover, our matching approach, which requires far less test-time resources, also provides effective explanations, surpassing many baselines. We also find that Top-K techniques universally improve every tested method. Finally, we showcase the potential of LLMs in constructing new benchmarks for model explanation and subsequently validate our conclusions. Our work illuminates new pathways for efficient and accurate approaches to interpreting NLP systems.
Measuring the Robustness of Natural Language Processing Models to Domain Shifts
May 31, 2023
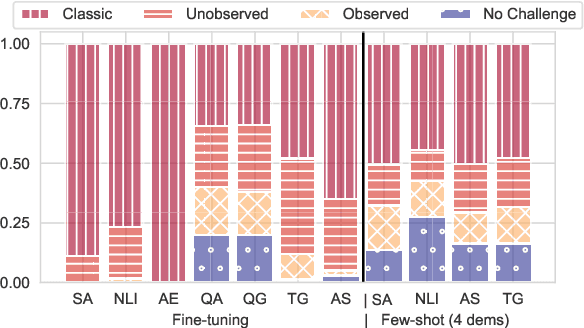
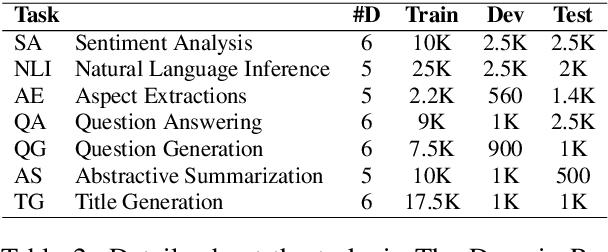
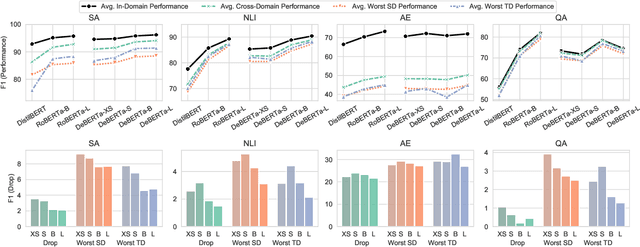
Large Language Models have shown promising performance on various tasks, including fine-tuning, few-shot learning, and zero-shot learning. However, their performance on domains without labeled data still lags behind those with labeled data, which we refer as the Domain Robustness (DR) challenge. Existing research on DR suffers from disparate setups, lack of evaluation task variety, and reliance on challenge sets. In this paper, we explore the DR challenge of both fine-tuned and few-shot learning models in natural domain shift settings. We introduce a DR benchmark comprising diverse NLP tasks, including sentence and token-level classification, QA, and generation, each task consists of several domains. We propose two views of the DR challenge: Source Drop (SD) and Target Drop (TD), which alternate between the source and target in-domain performance as reference points. We find that in significant proportions of domain shifts, either SD or TD is positive, but not both, emphasizing the importance of considering both measures as diagnostic tools. Our experimental results demonstrate the persistent existence of the DR challenge in both fine-tuning and few-shot learning models, though it is less pronounced in the latter. We also find that increasing the fine-tuned model size improves performance, particularly in classification.
Human Choice Prediction in Language-based Non-Cooperative Games: Simulation-based Off-Policy Evaluation
May 23, 2023
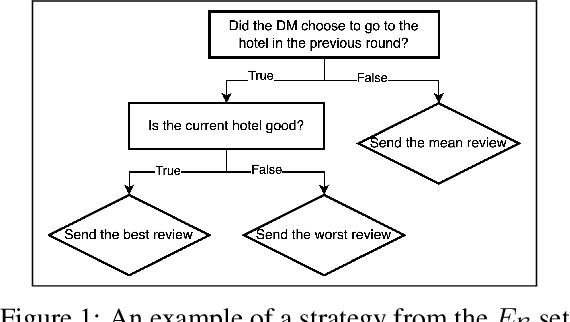

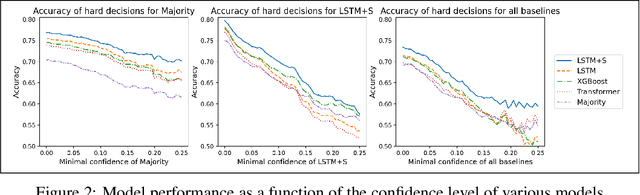
Persuasion games have been fundamental in economics and AI research, and have significant practical applications. Recent works in this area have started to incorporate natural language, moving beyond the traditional stylized message setting. However, previous research has focused on on-policy prediction, where the train and test data have the same distribution, which is not representative of real-life scenarios. In this paper, we tackle the challenging problem of off-policy evaluation (OPE) in language-based persuasion games. To address the inherent difficulty of human data collection in this setup, we propose a novel approach which combines real and simulated human-bot interaction data. Our simulated data is created by an exogenous model assuming decision makers (DMs) start with a mixture of random and decision-theoretic based behaviors and improve over time. We present a deep learning training algorithm that effectively integrates real interaction and simulated data, substantially improving over models that train only with interaction data. Our results demonstrate the potential of real interaction and simulation mixtures as a cost-effective and scalable solution for OPE in language-based persuasion games.\footnote{Our code and the large dataset we collected and generated are submitted as supplementary material and will be made publicly available upon acceptance.
A Systematic Study of Knowledge Distillation for Natural Language Generation with Pseudo-Target Training
May 03, 2023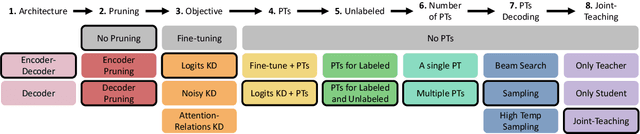
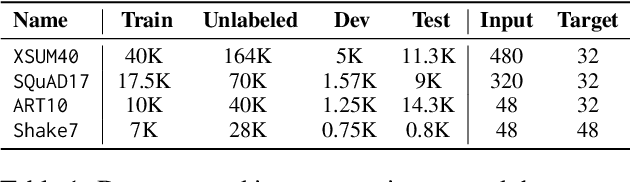
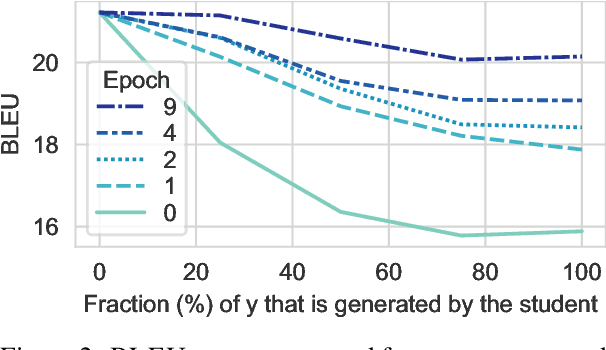
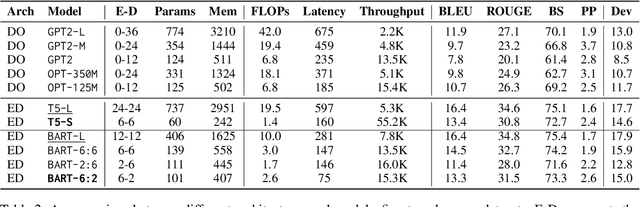
Modern Natural Language Generation (NLG) models come with massive computational and storage requirements. In this work, we study the potential of compressing them, which is crucial for real-world applications serving millions of users. We focus on Knowledge Distillation (KD) techniques, in which a small student model learns to imitate a large teacher model, allowing to transfer knowledge from the teacher to the student. In contrast to much of the previous work, our goal is to optimize the model for a specific NLG task and a specific dataset. Typically, in real-world applications, in addition to labeled data there is abundant unlabeled task-specific data, which is crucial for attaining high compression rates via KD. In this work, we conduct a systematic study of task-specific KD techniques for various NLG tasks under realistic assumptions. We discuss the special characteristics of NLG distillation and particularly the exposure bias problem. Following, we derive a family of Pseudo-Target (PT) augmentation methods, substantially extending prior work on sequence-level KD. We propose the Joint-Teaching method for NLG distillation, which applies word-level KD to multiple PTs generated by both the teacher and the student. Our study provides practical model design observations and demonstrates the effectiveness of PT training for task-specific KD in NLG.