 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRongfei Fan
Byzantine-resilient Federated Learning With Adaptivity to Data Heterogeneity
Mar 27, 2024
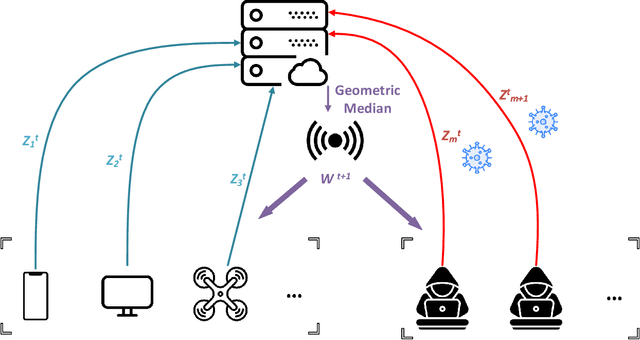
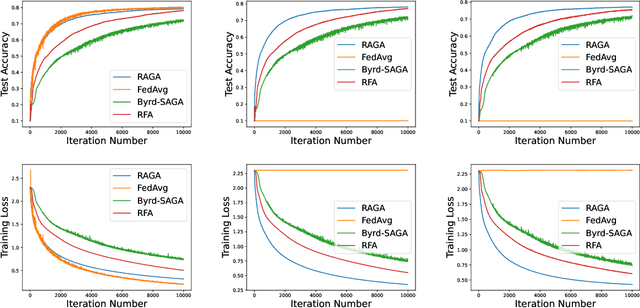
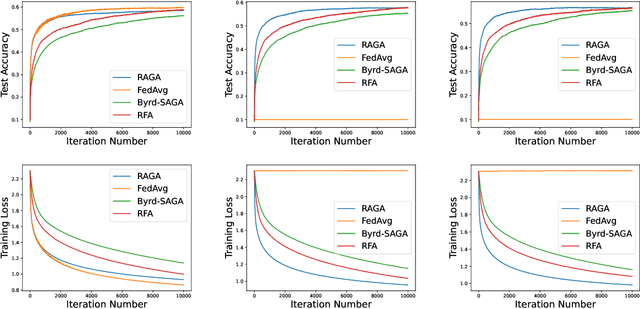
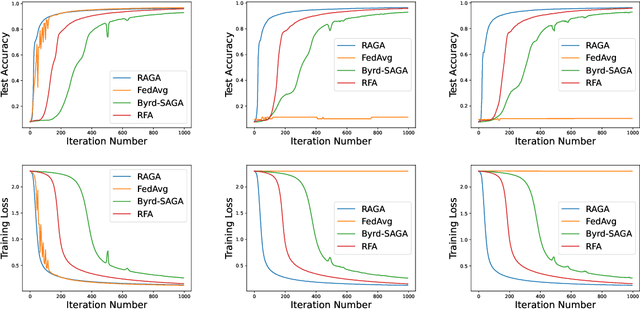
This paper deals with federated learning (FL) in the presence of malicious Byzantine attacks and data heterogeneity. A novel Robust Average Gradient Algorithm (RAGA) is proposed, which leverages the geometric median for aggregation and can freely select the round number for local updating. Different from most existing resilient approaches, which perform convergence analysis based on strongly-convex loss function or homogeneously distributed dataset, we conduct convergence analysis for not only strongly-convex but also non-convex loss function over heterogeneous dataset. According to our theoretical analysis, as long as the fraction of dataset from malicious users is less than half, RAGA can achieve convergence at rate $\mathcal{O}({1}/{T^{2/3- \delta}})$ where $T$ is the iteration number and $\delta \in (0, 2/3)$ for non-convex loss function, and at linear rate for strongly-convex loss function. Moreover, stationary point or global optimal solution is proved to obtainable as data heterogeneity vanishes. Experimental results corroborate the robustness of RAGA to Byzantine attacks and verifies the advantage of RAGA over baselines on convergence performance under various intensity of Byzantine attacks, for heterogeneous dataset.
Over-the-Air Computation Aided Federated Learning with the Aggregation of Normalized Gradient
Sep 03, 2023Over-the-air computation is a communication-efficient solution for federated learning (FL). In such a system, iterative procedure is performed: Local gradient of private loss function is updated, amplified and then transmitted by every mobile device; the server receives the aggregated gradient all-at-once, generates and then broadcasts updated model parameters to every mobile device. In terms of amplification factor selection, most related works suppose the local gradient's maximal norm always happens although it actually fluctuates over iterations, which may degrade convergence performance. To circumvent this problem, we propose to turn local gradient to be normalized one before amplifying it. Under our proposed method, when the loss function is smooth, we prove our proposed method can converge to stationary point at sub-linear rate. In case of smooth and strongly convex loss function, we prove our proposed method can achieve minimal training loss at linear rate with any small positive tolerance. Moreover, a tradeoff between convergence rate and the tolerance is discovered. To speedup convergence, problems optimizing system parameters are also formulated for above two cases. Although being non-convex, optimal solution with polynomial complexity of the formulated problems are derived. Experimental results show our proposed method can outperform benchmark methods on convergence performance.
Federated Learning Robust to Byzantine Attacks: Achieving Zero Optimality Gap
Aug 21, 2023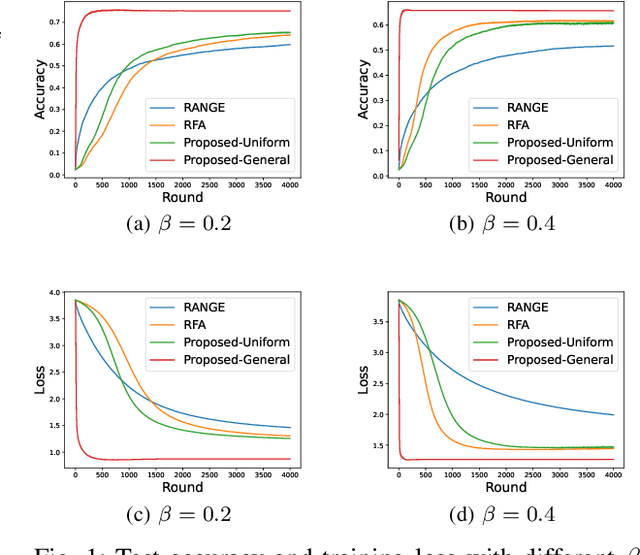
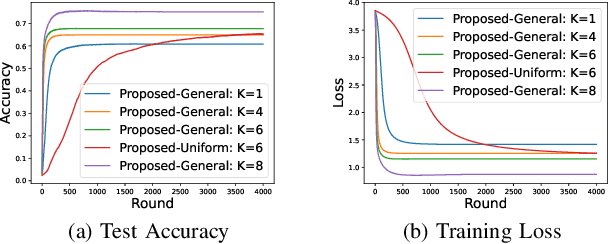
In this paper, we propose a robust aggregation method for federated learning (FL) that can effectively tackle malicious Byzantine attacks. At each user, model parameter is firstly updated by multiple steps, which is adjustable over iterations, and then pushed to the aggregation center directly. This decreases the number of interactions between the aggregation center and users, allows each user to set training parameter in a flexible way, and reduces computation burden compared with existing works that need to combine multiple historical model parameters. At the aggregation center, geometric median is leveraged to combine the received model parameters from each user. Rigorous proof shows that zero optimality gap is achieved by our proposed method with linear convergence, as long as the fraction of Byzantine attackers is below half. Numerical results verify the effectiveness of our proposed method.
Joint Power Control and Data Size Selection for Over-the-Air Computation Aided Federated Learning
Aug 17, 2023



Federated learning (FL) has emerged as an appealing machine learning approach to deal with massive raw data generated at multiple mobile devices, {which needs to aggregate the training model parameter of every mobile device at one base station (BS) iteratively}. For parameter aggregating in FL, over-the-air computation is a spectrum-efficient solution, which allows all mobile devices to transmit their parameter-mapped signals concurrently to a BS. Due to heterogeneous channel fading and noise, there exists difference between the BS's received signal and its desired signal, measured as the mean-squared error (MSE). To minimize the MSE, we propose to jointly optimize the signal amplification factors at the BS and the mobile devices as well as the data size (the number of data samples involved in local training) at every mobile device. The formulated problem is challenging to solve due to its non-convexity. To find the optimal solution, with some simplification on cost function and variable replacement, which still preserves equivalence, we transform the changed problem to be a bi-level problem equivalently. For the lower-level problem, optimal solution is found by enumerating every candidate solution from the Karush-Kuhn-Tucker (KKT) condition. For the upper-level problem, the optimal solution is found by exploring its piecewise convexity. Numerical results show that our proposed method can greatly reduce the MSE and can help to improve the training performance of FL compared with benchmark methods.