 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoss Greer
Driver Activity Classification Using Generalizable Representations from Vision-Language Models
Apr 23, 2024
Driver activity classification is crucial for ensuring road safety, with applications ranging from driver assistance systems to autonomous vehicle control transitions. In this paper, we present a novel approach leveraging generalizable representations from vision-language models for driver activity classification. Our method employs a Semantic Representation Late Fusion Neural Network (SRLF-Net) to process synchronized video frames from multiple perspectives. Each frame is encoded using a pretrained vision-language encoder, and the resulting embeddings are fused to generate class probability predictions. By leveraging contrastively-learned vision-language representations, our approach achieves robust performance across diverse driver activities. We evaluate our method on the Naturalistic Driving Action Recognition Dataset, demonstrating strong accuracy across many classes. Our results suggest that vision-language representations offer a promising avenue for driver monitoring systems, providing both accuracy and interpretability through natural language descriptors.
Language-Driven Active Learning for Diverse Open-Set 3D Object Detection
Apr 19, 2024Object detection is crucial for ensuring safe autonomous driving. However, data-driven approaches face challenges when encountering minority or novel objects in the 3D driving scene. In this paper, we propose VisLED, a language-driven active learning framework for diverse open-set 3D Object Detection. Our method leverages active learning techniques to query diverse and informative data samples from an unlabeled pool, enhancing the model's ability to detect underrepresented or novel objects. Specifically, we introduce the Vision-Language Embedding Diversity Querying (VisLED-Querying) algorithm, which operates in both open-world exploring and closed-world mining settings. In open-world exploring, VisLED-Querying selects data points most novel relative to existing data, while in closed-world mining, it mines new instances of known classes. We evaluate our approach on the nuScenes dataset and demonstrate its effectiveness compared to random sampling and entropy-querying methods. Our results show that VisLED-Querying consistently outperforms random sampling and offers competitive performance compared to entropy-querying despite the latter's model-optimality, highlighting the potential of VisLED for improving object detection in autonomous driving scenarios.
Multi-Frame, Lightweight & Efficient Vision-Language Models for Question Answering in Autonomous Driving
Mar 28, 2024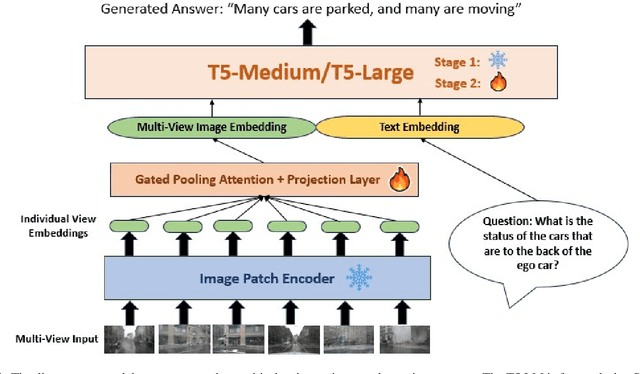


Vision-Language Models (VLMs) and Multi-Modal Language models (MMLMs) have become prominent in autonomous driving research, as these models can provide interpretable textual reasoning and responses for end-to-end autonomous driving safety tasks using traffic scene images and other data modalities. However, current approaches to these systems use expensive large language model (LLM) backbones and image encoders, making such systems unsuitable for real-time autonomous driving systems where tight memory constraints exist and fast inference time is necessary. To address these previous issues, we develop EM-VLM4AD, an efficient, lightweight, multi-frame vision language model which performs Visual Question Answering for autonomous driving. In comparison to previous approaches, EM-VLM4AD requires at least 10 times less memory and floating point operations, while also achieving higher BLEU-4, METEOR, CIDEr, and ROGUE scores than the existing baseline on the DriveLM dataset. EM-VLM4AD also exhibits the ability to extract relevant information from traffic views related to prompts and can answer questions for various autonomous driving subtasks. We release our code to train and evaluate our model at https://github.com/akshaygopalkr/EM-VLM4AD.
Learning to Find Missing Video Frames with Synthetic Data Augmentation: A General Framework and Application in Generating Thermal Images Using RGB Cameras
Feb 29, 2024
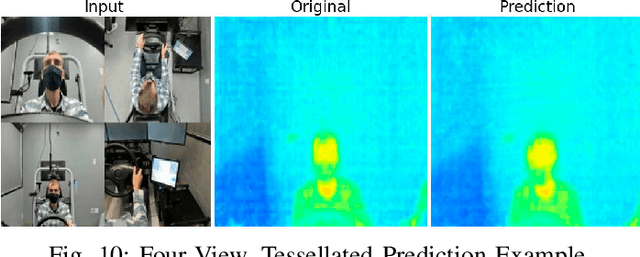
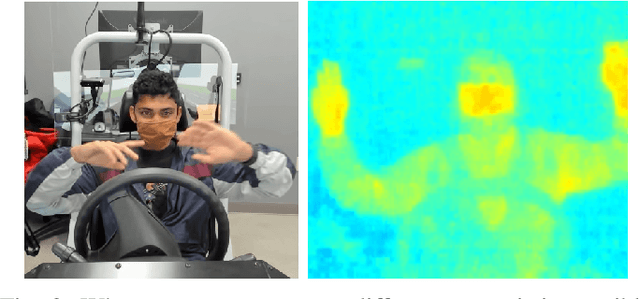
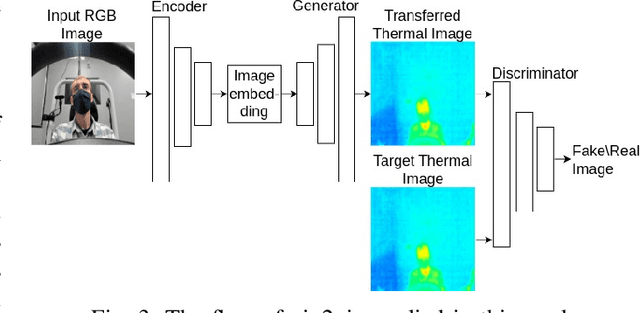
Advanced Driver Assistance Systems (ADAS) in intelligent vehicles rely on accurate driver perception within the vehicle cabin, often leveraging a combination of sensing modalities. However, these modalities operate at varying rates, posing challenges for real-time, comprehensive driver state monitoring. This paper addresses the issue of missing data due to sensor frame rate mismatches, introducing a generative model approach to create synthetic yet realistic thermal imagery. We propose using conditional generative adversarial networks (cGANs), specifically comparing the pix2pix and CycleGAN architectures. Experimental results demonstrate that pix2pix outperforms CycleGAN, and utilizing multi-view input styles, especially stacked views, enhances the accuracy of thermal image generation. Moreover, the study evaluates the model's generalizability across different subjects, revealing the importance of individualized training for optimal performance. The findings suggest the potential of generative models in addressing missing frames, advancing driver state monitoring for intelligent vehicles, and underscoring the need for continued research in model generalization and customization.
Towards Explainable, Safe Autonomous Driving with Language Embeddings for Novelty Identification and Active Learning: Framework and Experimental Analysis with Real-World Data Sets
Feb 11, 2024This research explores the integration of language embeddings for active learning in autonomous driving datasets, with a focus on novelty detection. Novelty arises from unexpected scenarios that autonomous vehicles struggle to navigate, necessitating higher-level reasoning abilities. Our proposed method employs language-based representations to identify novel scenes, emphasizing the dual purpose of safety takeover responses and active learning. The research presents a clustering experiment using Contrastive Language-Image Pretrained (CLIP) embeddings to organize datasets and detect novelties. We find that the proposed algorithm effectively isolates novel scenes from a collection of subsets derived from two real-world driving datasets, one vehicle-mounted and one infrastructure-mounted. From the generated clusters, we further present methods for generating textual explanations of elements which differentiate scenes classified as novel from other scenes in the data pool, presenting qualitative examples from the clustered results. Our results demonstrate the effectiveness of language-driven embeddings in identifying novel elements and generating explanations of data, and we further discuss potential applications in safe takeovers, data curation, and multi-task active learning.
ActiveAnno3D -- An Active Learning Framework for Multi-Modal 3D Object Detection
Feb 05, 2024The curation of large-scale datasets is still costly and requires much time and resources. Data is often manually labeled, and the challenge of creating high-quality datasets remains. In this work, we fill the research gap using active learning for multi-modal 3D object detection. We propose ActiveAnno3D, an active learning framework to select data samples for labeling that are of maximum informativeness for training. We explore various continuous training methods and integrate the most efficient method regarding computational demand and detection performance. Furthermore, we perform extensive experiments and ablation studies with BEVFusion and PV-RCNN on the nuScenes and TUM Traffic Intersection dataset. We show that we can achieve almost the same performance with PV-RCNN and the entropy-based query strategy when using only half of the training data (77.25 mAP compared to 83.50 mAP) of the TUM Traffic Intersection dataset. BEVFusion achieved an mAP of 64.31 when using half of the training data and 75.0 mAP when using the complete nuScenes dataset. We integrate our active learning framework into the proAnno labeling tool to enable AI-assisted data selection and labeling and minimize the labeling costs. Finally, we provide code, weights, and visualization results on our website: https://active3d-framework.github.io/active3d-framework.
The Why, When, and How to Use Active Learning in Large-Data-Driven 3D Object Detection for Safe Autonomous Driving: An Empirical Exploration
Jan 30, 2024Active learning strategies for 3D object detection in autonomous driving datasets may help to address challenges of data imbalance, redundancy, and high-dimensional data. We demonstrate the effectiveness of entropy querying to select informative samples, aiming to reduce annotation costs and improve model performance. We experiment using the BEVFusion model for 3D object detection on the nuScenes dataset, comparing active learning to random sampling and demonstrating that entropy querying outperforms in most cases. The method is particularly effective in reducing the performance gap between majority and minority classes. Class-specific analysis reveals efficient allocation of annotated resources for limited data budgets, emphasizing the importance of selecting diverse and informative data for model training. Our findings suggest that entropy querying is a promising strategy for selecting data that enhances model learning in resource-constrained environments.
Comparative Assessment of Markov Models and Recurrent Neural Networks for Jazz Music Generation
Sep 14, 2023
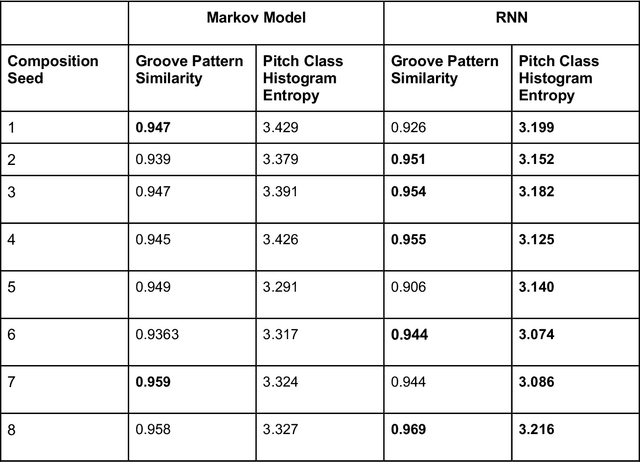


As generative models have risen in popularity, a domain that has risen alongside is generative models for music. Our study aims to compare the performance of a simple Markov chain model and a recurrent neural network (RNN) model, two popular models for sequence generating tasks, in jazz music improvisation. While music, especially jazz, remains subjective in telling whether a composition is "good" or "bad", we aim to quantify our results using metrics of groove pattern similarity and pitch class histogram entropy. We trained both models using transcriptions of jazz blues choruses from professional jazz players, and also fed musical jazz seeds to help give our model some context in beginning the generation. Our results show that the RNN outperforms the Markov model on both of our metrics, indicating better rhythmic consistency and tonal stability in the generated music. Through the use of music21 library, we tokenized our jazz dataset into pitches and durations that our model could interpret and train on. Our findings contribute to the growing field of AI-generated music, highlighting the important use of metrics to assess generation quality. Future work includes expanding the dataset of MIDI files to a larger scale, conducting human surveys for subjective evaluations, and incorporating additional metrics to address the challenge of subjectivity in music evaluation. Our study provides valuable insight into the use of recurrent neural networks for sequential based tasks like generating music.
Vision-based Analysis of Driver Activity and Driving Performance Under the Influence of Alcohol
Sep 14, 2023About 30% of all traffic crash fatalities in the United States involve drunk drivers, making the prevention of drunk driving paramount to vehicle safety in the US and other locations which have a high prevalence of driving while under the influence of alcohol. Driving impairment can be monitored through active use of sensors (when drivers are asked to engage in providing breath samples to a vehicle instrument or when pulled over by a police officer), but a more passive and robust mechanism of sensing may allow for wider adoption and benefit of intelligent systems that reduce drunk driving accidents. This could assist in identifying impaired drivers before they drive, or early in the driving process (before a crash or detection by law enforcement). In this research, we introduce a study which adopts a multi-modal ensemble of visual, thermal, audio, and chemical sensors to (1) examine the impact of acute alcohol administration on driving performance in a driving simulator, and (2) identify data-driven methods for detecting driving under the influence of alcohol. We describe computer vision and machine learning models for analyzing the driver's face in thermal imagery, and introduce a pipeline for training models on data collected from drivers with a range of breath-alcohol content levels, including discussion of relevant machine learning phenomena which can help in future experiment design for related studies.
Robust Detection, Assocation, and Localization of Vehicle Lights: A Context-Based Cascaded CNN Approach and Evaluations
Jul 27, 2023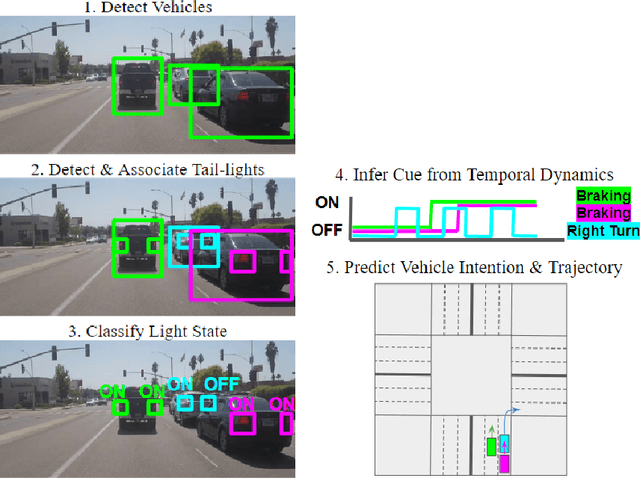
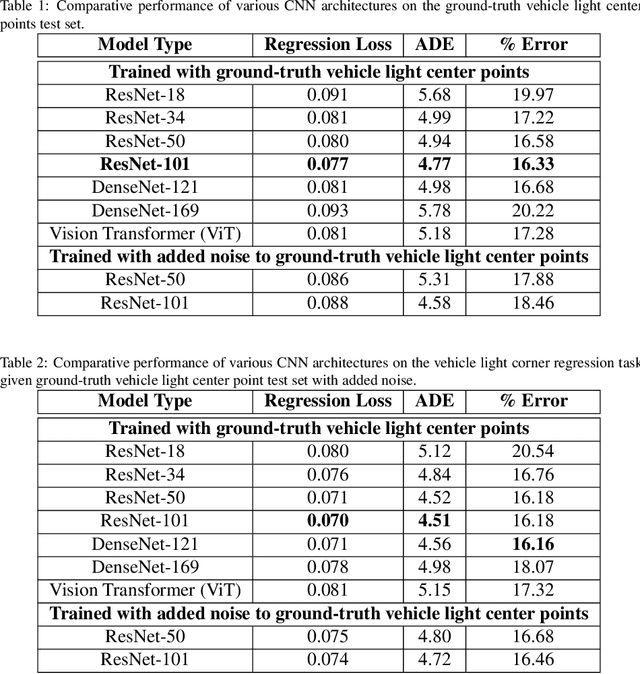

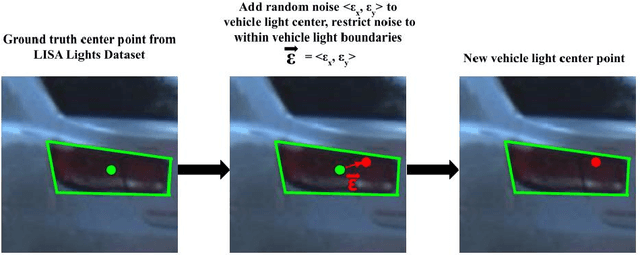
Vehicle light detection is required for important downstream safe autonomous driving tasks, such as predicting a vehicle's light state to determine if the vehicle is making a lane change or turning. Currently, many vehicle light detectors use single-stage detectors which predict bounding boxes to identify a vehicle light, in a manner decoupled from vehicle instances. In this paper, we present a method for detecting a vehicle light given an upstream vehicle detection and approximation of a visible light's center. Our method predicts four approximate corners associated with each vehicle light. We experiment with CNN architectures, data augmentation, and contextual preprocessing methods designed to reduce surrounding-vehicle confusion. We achieve an average distance error from the ground truth corner of 5.09 pixels, about 17.24% of the size of the vehicle light on average. We train and evaluate our model on the LISA Lights dataset, allowing us to thoroughly evaluate our vehicle light corner detection model on a large variety of vehicle light shapes and lighting conditions. We propose that this model can be integrated into a pipeline with vehicle detection and vehicle light center detection to make a fully-formed vehicle light detection network, valuable to identifying trajectory-informative signals in driving scenes.