 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoss K. Maddox
Hierarchical Cross-Modal Talking Face Generationwith Dynamic Pixel-Wise Loss
May 09, 2019


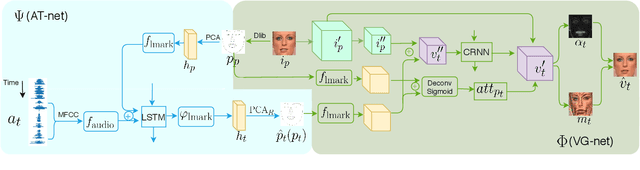
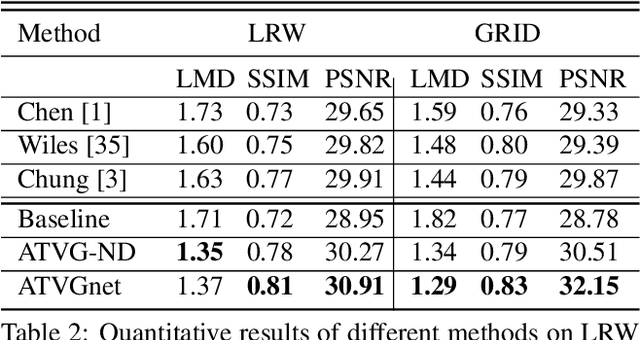
We devise a cascade GAN approach to generate talking face video, which is robust to different face shapes, view angles, facial characteristics, and noisy audio conditions. Instead of learning a direct mapping from audio to video frames, we propose first to transfer audio to high-level structure, i.e., the facial landmarks, and then to generate video frames conditioned on the landmarks. Compared to a direct audio-to-image approach, our cascade approach avoids fitting spurious correlations between audiovisual signals that are irrelevant to the speech content. We, humans, are sensitive to temporal discontinuities and subtle artifacts in video. To avoid those pixel jittering problems and to enforce the network to focus on audiovisual-correlated regions, we propose a novel dynamically adjustable pixel-wise loss with an attention mechanism. Furthermore, to generate a sharper image with well-synchronized facial movements, we propose a novel regression-based discriminator structure, which considers sequence-level information along with frame-level information. Thoughtful experiments on several datasets and real-world samples demonstrate significantly better results obtained by our method than the state-of-the-art methods in both quantitative and qualitative comparisons.
Lip Movements Generation at a Glance
May 21, 2018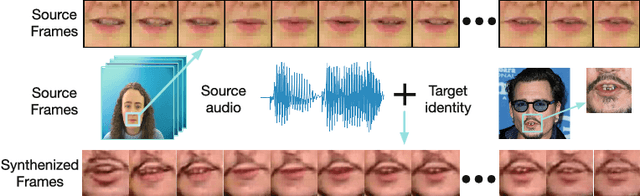
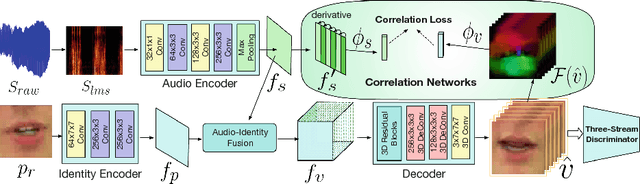
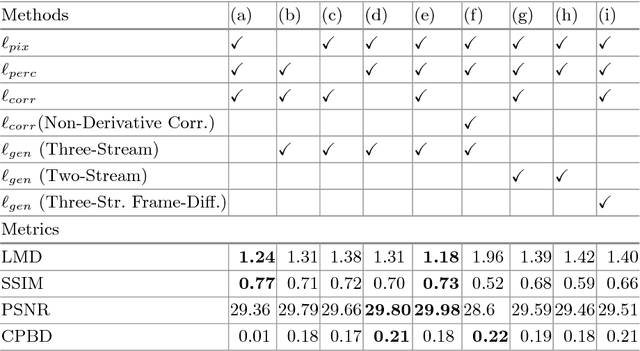
Cross-modality generation is an emerging topic that aims to synthesize data in one modality based on information in a different modality. In this paper, we consider a task of such: given an arbitrary audio speech and one lip image of arbitrary target identity, generate synthesized lip movements of the target identity saying the speech. To perform well in this task, it inevitably requires a model to not only consider the retention of target identity, photo-realistic of synthesized images, consistency and smoothness of lip images in a sequence, but more importantly, learn the correlations between audio speech and lip movements. To solve the collective problems, we explore the best modeling of the audio-visual correlations in building and training a lip-movement generator network. Specifically, we devise a method to fuse audio and image embeddings to generate multiple lip images at once and propose a novel correlation loss to synchronize lip changes and speech changes. Our final model utilizes a combination of four losses for a comprehensive consideration in generating lip movements; it is trained in an end-to-end fashion and is robust to lip shapes, view angles and different facial characteristics. Thoughtful experiments on three datasets ranging from lab-recorded to lips in-the-wild show that our model significantly outperforms other state-of-the-art methods extended to this task.