 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRui Ma
Anywhere: A Multi-Agent Framework for Reliable and Diverse Foreground-Conditioned Image Inpainting
Apr 29, 2024
Recent advancements in image inpainting, particularly through diffusion modeling, have yielded promising outcomes. However, when tested in scenarios involving the completion of images based on the foreground objects, current methods that aim to inpaint an image in an end-to-end manner encounter challenges such as "over-imagination", inconsistency between foreground and background, and limited diversity. In response, we introduce Anywhere, a pioneering multi-agent framework designed to address these issues. Anywhere utilizes a sophisticated pipeline framework comprising various agents such as Visual Language Model (VLM), Large Language Model (LLM), and image generation models. This framework consists of three principal components: the prompt generation module, the image generation module, and the outcome analyzer. The prompt generation module conducts a semantic analysis of the input foreground image, leveraging VLM to predict relevant language descriptions and LLM to recommend optimal language prompts. In the image generation module, we employ a text-guided canny-to-image generation model to create a template image based on the edge map of the foreground image and language prompts, and an image refiner to produce the outcome by blending the input foreground and the template image. The outcome analyzer employs VLM to evaluate image content rationality, aesthetic score, and foreground-background relevance, triggering prompt and image regeneration as needed. Extensive experiments demonstrate that our Anywhere framework excels in foreground-conditioned image inpainting, mitigating "over-imagination", resolving foreground-background discrepancies, and enhancing diversity. It successfully elevates foreground-conditioned image inpainting to produce more reliable and diverse results.
PGAHum: Prior-Guided Geometry and Appearance Learning for High-Fidelity Animatable Human Reconstruction
Apr 22, 2024Recent techniques on implicit geometry representation learning and neural rendering have shown promising results for 3D clothed human reconstruction from sparse video inputs. However, it is still challenging to reconstruct detailed surface geometry and even more difficult to synthesize photorealistic novel views with animated human poses. In this work, we introduce PGAHum, a prior-guided geometry and appearance learning framework for high-fidelity animatable human reconstruction. We thoroughly exploit 3D human priors in three key modules of PGAHum to achieve high-quality geometry reconstruction with intricate details and photorealistic view synthesis on unseen poses. First, a prior-based implicit geometry representation of 3D human, which contains a delta SDF predicted by a tri-plane network and a base SDF derived from the prior SMPL model, is proposed to model the surface details and the body shape in a disentangled manner. Second, we introduce a novel prior-guided sampling strategy that fully leverages the prior information of the human pose and body to sample the query points within or near the body surface. By avoiding unnecessary learning in the empty 3D space, the neural rendering can recover more appearance details. Last, we propose a novel iterative backward deformation strategy to progressively find the correspondence for the query point in observation space. A skinning weights prediction model is learned based on the prior provided by the SMPL model to achieve the iterative backward LBS deformation. Extensive quantitative and qualitative comparisons on various datasets are conducted and the results demonstrate the superiority of our framework. Ablation studies also verify the effectiveness of each scheme for geometry and appearance learning.
D-Aug: Enhancing Data Augmentation for Dynamic LiDAR Scenes
Apr 17, 2024Creating large LiDAR datasets with pixel-level labeling poses significant challenges. While numerous data augmentation methods have been developed to reduce the reliance on manual labeling, these methods predominantly focus on static scenes and they overlook the importance of data augmentation for dynamic scenes, which is critical for autonomous driving. To address this issue, we propose D-Aug, a LiDAR data augmentation method tailored for augmenting dynamic scenes. D-Aug extracts objects and inserts them into dynamic scenes, considering the continuity of these objects across consecutive frames. For seamless insertion into dynamic scenes, we propose a reference-guided method that involves dynamic collision detection and rotation alignment. Additionally, we present a pixel-level road identification strategy to efficiently determine suitable insertion positions. We validated our method using the nuScenes dataset with various 3D detection and tracking methods. Comparative experiments demonstrate the superiority of D-Aug.
OSTAF: A One-Shot Tuning Method for Improved Attribute-Focused T2I Personalization
Mar 17, 2024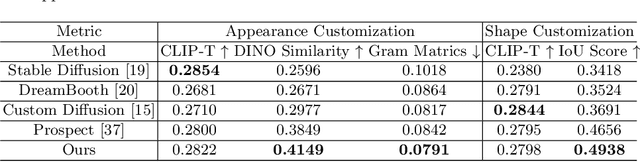
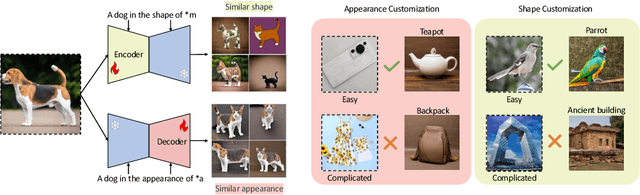
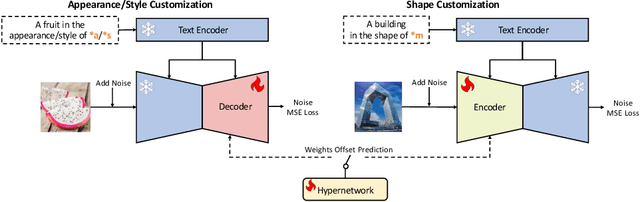
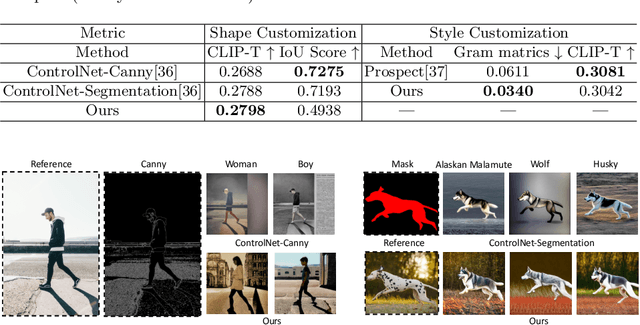
Personalized text-to-image (T2I) models not only produce lifelike and varied visuals but also allow users to tailor the images to fit their personal taste. These personalization techniques can grasp the essence of a concept through a collection of images, or adjust a pre-trained text-to-image model with a specific image input for subject-driven or attribute-aware guidance. Yet, accurately capturing the distinct visual attributes of an individual image poses a challenge for these methods. To address this issue, we introduce OSTAF, a novel parameter-efficient one-shot fine-tuning method which only utilizes one reference image for T2I personalization. A novel hypernetwork-powered attribute-focused fine-tuning mechanism is employed to achieve the precise learning of various attribute features (e.g., appearance, shape or drawing style) from the reference image. Comparing to existing image customization methods, our method shows significant superiority in attribute identification and application, as well as achieves a good balance between efficiency and output quality.
SemanticHuman-HD: High-Resolution Semantic Disentangled 3D Human Generation
Mar 15, 2024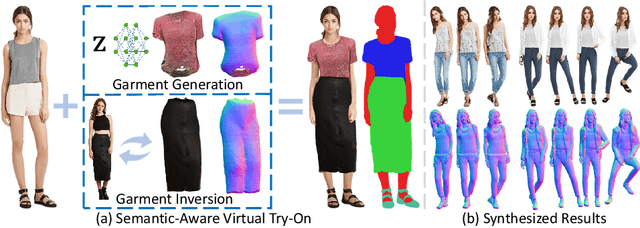
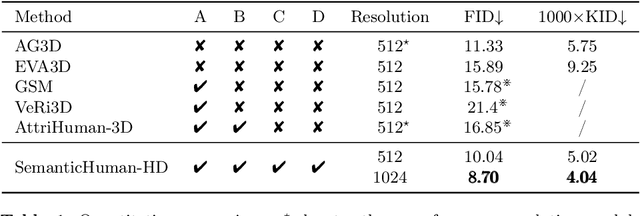
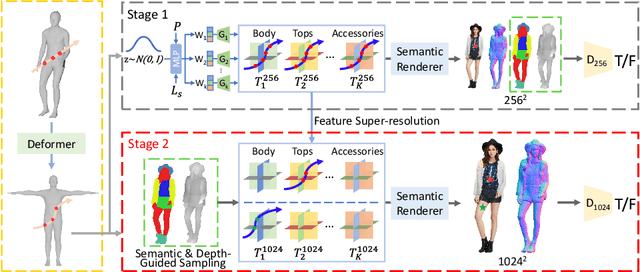

With the development of neural radiance fields and generative models, numerous methods have been proposed for learning 3D human generation from 2D images. These methods allow control over the pose of the generated 3D human and enable rendering from different viewpoints. However, none of these methods explore semantic disentanglement in human image synthesis, i.e., they can not disentangle the generation of different semantic parts, such as the body, tops, and bottoms. Furthermore, existing methods are limited to synthesize images at $512^2$ resolution due to the high computational cost of neural radiance fields. To address these limitations, we introduce SemanticHuman-HD, the first method to achieve semantic disentangled human image synthesis. Notably, SemanticHuman-HD is also the first method to achieve 3D-aware image synthesis at $1024^2$ resolution, benefiting from our proposed 3D-aware super-resolution module. By leveraging the depth maps and semantic masks as guidance for the 3D-aware super-resolution, we significantly reduce the number of sampling points during volume rendering, thereby reducing the computational cost. Our comparative experiments demonstrate the superiority of our method. The effectiveness of each proposed component is also verified through ablation studies. Moreover, our method opens up exciting possibilities for various applications, including 3D garment generation, semantic-aware image synthesis, controllable image synthesis, and out-of-domain image synthesis.
3D-SceneDreamer: Text-Driven 3D-Consistent Scene Generation
Mar 14, 2024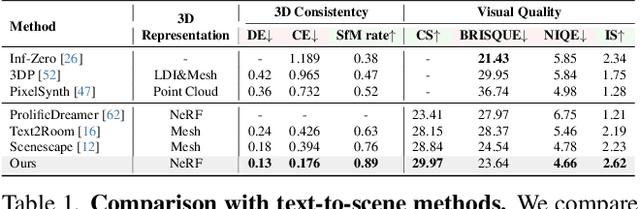
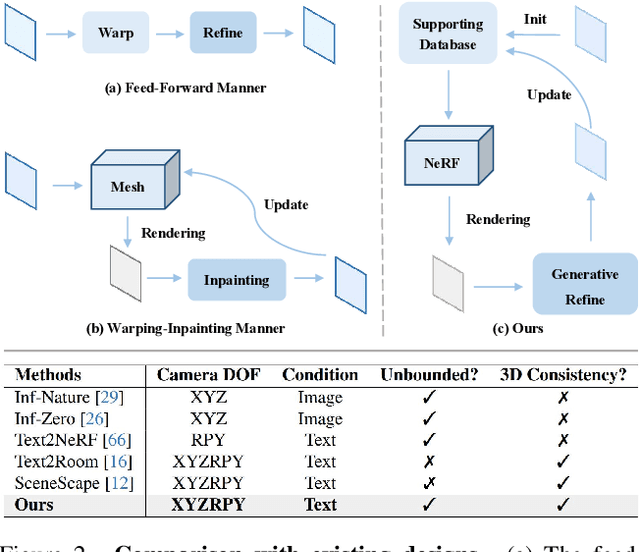
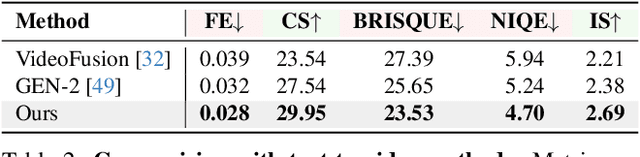
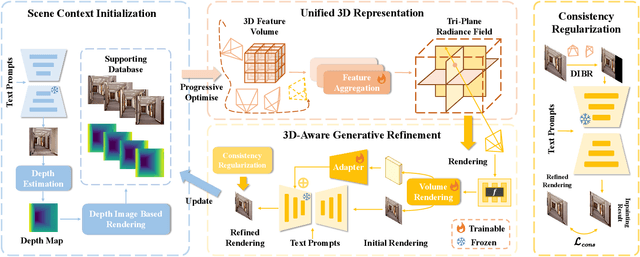
Text-driven 3D scene generation techniques have made rapid progress in recent years. Their success is mainly attributed to using existing generative models to iteratively perform image warping and inpainting to generate 3D scenes. However, these methods heavily rely on the outputs of existing models, leading to error accumulation in geometry and appearance that prevent the models from being used in various scenarios (e.g., outdoor and unreal scenarios). To address this limitation, we generatively refine the newly generated local views by querying and aggregating global 3D information, and then progressively generate the 3D scene. Specifically, we employ a tri-plane features-based NeRF as a unified representation of the 3D scene to constrain global 3D consistency, and propose a generative refinement network to synthesize new contents with higher quality by exploiting the natural image prior from 2D diffusion model as well as the global 3D information of the current scene. Our extensive experiments demonstrate that, in comparison to previous methods, our approach supports wide variety of scene generation and arbitrary camera trajectories with improved visual quality and 3D consistency.
TaylorGrid: Towards Fast and High-Quality Implicit Field Learning via Direct Taylor-based Grid Optimization
Feb 22, 2024Coordinate-based neural implicit representation or implicit fields have been widely studied for 3D geometry representation or novel view synthesis. Recently, a series of efforts have been devoted to accelerating the speed and improving the quality of the coordinate-based implicit field learning. Instead of learning heavy MLPs to predict the neural implicit values for the query coordinates, neural voxels or grids combined with shallow MLPs have been proposed to achieve high-quality implicit field learning with reduced optimization time. On the other hand, lightweight field representations such as linear grid have been proposed to further improve the learning speed. In this paper, we aim for both fast and high-quality implicit field learning, and propose TaylorGrid, a novel implicit field representation which can be efficiently computed via direct Taylor expansion optimization on 2D or 3D grids. As a general representation, TaylorGrid can be adapted to different implicit fields learning tasks such as SDF learning or NeRF. From extensive quantitative and qualitative comparisons, TaylorGrid achieves a balance between the linear grid and neural voxels, showing its superiority in fast and high-quality implicit field learning.
EPSD: Early Pruning with Self-Distillation for Efficient Model Compression
Jan 31, 2024Neural network compression techniques, such as knowledge distillation (KD) and network pruning, have received increasing attention. Recent work `Prune, then Distill' reveals that a pruned student-friendly teacher network can benefit the performance of KD. However, the conventional teacher-student pipeline, which entails cumbersome pre-training of the teacher and complicated compression steps, makes pruning with KD less efficient. In addition to compressing models, recent compression techniques also emphasize the aspect of efficiency. Early pruning demands significantly less computational cost in comparison to the conventional pruning methods as it does not require a large pre-trained model. Likewise, a special case of KD, known as self-distillation (SD), is more efficient since it requires no pre-training or student-teacher pair selection. This inspires us to collaborate early pruning with SD for efficient model compression. In this work, we propose the framework named Early Pruning with Self-Distillation (EPSD), which identifies and preserves distillable weights in early pruning for a given SD task. EPSD efficiently combines early pruning and self-distillation in a two-step process, maintaining the pruned network's trainability for compression. Instead of a simple combination of pruning and SD, EPSD enables the pruned network to favor SD by keeping more distillable weights before training to ensure better distillation of the pruned network. We demonstrated that EPSD improves the training of pruned networks, supported by visual and quantitative analyses. Our evaluation covered diverse benchmarks (CIFAR-10/100, Tiny-ImageNet, full ImageNet, CUB-200-2011, and Pascal VOC), with EPSD outperforming advanced pruning and SD techniques.
3D-SSGAN: Lifting 2D Semantics for 3D-Aware Compositional Portrait Synthesis
Jan 08, 2024Existing 3D-aware portrait synthesis methods can generate impressive high-quality images while preserving strong 3D consistency. However, most of them cannot support the fine-grained part-level control over synthesized images. Conversely, some GAN-based 2D portrait synthesis methods can achieve clear disentanglement of facial regions, but they cannot preserve view consistency due to a lack of 3D modeling abilities. To address these issues, we propose 3D-SSGAN, a novel framework for 3D-aware compositional portrait image synthesis. First, a simple yet effective depth-guided 2D-to-3D lifting module maps the generated 2D part features and semantics to 3D. Then, a volume renderer with a novel 3D-aware semantic mask renderer is utilized to produce the composed face features and corresponding masks. The whole framework is trained end-to-end by discriminating between real and synthesized 2D images and their semantic masks. Quantitative and qualitative evaluations demonstrate the superiority of 3D-SSGAN in controllable part-level synthesis while preserving 3D view consistency.
P2M2-Net: Part-Aware Prompt-Guided Multimodal Point Cloud Completion
Dec 29, 2023Inferring missing regions from severely occluded point clouds is highly challenging. Especially for 3D shapes with rich geometry and structure details, inherent ambiguities of the unknown parts are existing. Existing approaches either learn a one-to-one mapping in a supervised manner or train a generative model to synthesize the missing points for the completion of 3D point cloud shapes. These methods, however, lack the controllability for the completion process and the results are either deterministic or exhibiting uncontrolled diversity. Inspired by the prompt-driven data generation and editing, we propose a novel prompt-guided point cloud completion framework, coined P2M2-Net, to enable more controllable and more diverse shape completion. Given an input partial point cloud and a text prompt describing the part-aware information such as semantics and structure of the missing region, our Transformer-based completion network can efficiently fuse the multimodal features and generate diverse results following the prompt guidance. We train the P2M2-Net on a new large-scale PartNet-Prompt dataset and conduct extensive experiments on two challenging shape completion benchmarks. Quantitative and qualitative results show the efficacy of incorporating prompts for more controllable part-aware point cloud completion and generation. Code and data are available at https://github.com/JLU-ICL/P2M2-Net.