 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuisi Zhang
Transformer-Based Local Feature Matching for Multimodal Image Registration
Apr 25, 2024
Ultrasound imaging is a cost-effective and radiation-free modality for visualizing anatomical structures in real-time, making it ideal for guiding surgical interventions. However, its limited field-of-view, speckle noise, and imaging artifacts make it difficult to interpret the images for inexperienced users. In this paper, we propose a new 2D ultrasound to 3D CT registration method to improve surgical guidance during ultrasound-guided interventions. Our approach adopts a dense feature matching method called LoFTR to our multimodal registration problem. We learn to predict dense coarse-to-fine correspondences using a Transformer-based architecture to estimate a robust rigid transformation between a 2D ultrasound frame and a CT scan. Additionally, a fully differentiable pose estimation method is introduced, optimizing LoFTR on pose estimation error during training. Experiments conducted on a multimodal dataset of ex vivo porcine kidneys demonstrate the method's promising results for intraoperative, trackerless ultrasound pose estimation. By mapping 2D ultrasound frames into the 3D CT volume space, the method provides intraoperative guidance, potentially improving surgical workflows and image interpretation.
Token-Specific Watermarking with Enhanced Detectability and Semantic Coherence for Large Language Models
Mar 07, 2024Large language models generate high-quality responses with potential misinformation, underscoring the need for regulation by distinguishing AI-generated and human-written texts. Watermarking is pivotal in this context, which involves embedding hidden markers in texts during the LLM inference phase, which is imperceptible to humans. Current watermarking algorithms, however, face the challenge of achieving both the detectability of inserted watermarks and the semantic integrity of generated texts, where enhancing one aspect often undermines the other. To overcome this, we introduce a novel multi-objective optimization (MOO) approach for watermarking that utilizes lightweight networks to generate token-specific watermarking logits and splitting ratios. By leveraging MOO to optimize for both detection and semantic objective functions, our method simultaneously achieves detectability and semantic integrity. Experimental results show that our method outperforms current watermarking techniques in enhancing the detectability of texts generated by LLMs while maintaining their semantic coherence. Our code is available at https://github.com/mignonjia/TS_watermark.
EmMark: Robust Watermarks for IP Protection of Embedded Quantized Large Language Models
Feb 27, 2024This paper introduces EmMark,a novel watermarking framework for protecting the intellectual property (IP) of embedded large language models deployed on resource-constrained edge devices. To address the IP theft risks posed by malicious end-users, EmMark enables proprietors to authenticate ownership by querying the watermarked model weights and matching the inserted signatures. EmMark's novelty lies in its strategic watermark weight parameters selection, nsuring robustness and maintaining model quality. Extensive proof-of-concept evaluations of models from OPT and LLaMA-2 families demonstrate EmMark's fidelity, achieving 100% success in watermark extraction with model performance preservation. EmMark also showcased its resilience against watermark removal and forging attacks.
REMARK-LLM: A Robust and Efficient Watermarking Framework for Generative Large Language Models
Oct 18, 2023We present REMARK-LLM, a novel efficient, and robust watermarking framework designed for texts generated by large language models (LLMs). Synthesizing human-like content using LLMs necessitates vast computational resources and extensive datasets, encapsulating critical intellectual property (IP). However, the generated content is prone to malicious exploitation, including spamming and plagiarism. To address the challenges, REMARK-LLM proposes three new components: (i) a learning-based message encoding module to infuse binary signatures into LLM-generated texts; (ii) a reparameterization module to transform the dense distributions from the message encoding to the sparse distribution of the watermarked textual tokens; (iii) a decoding module dedicated for signature extraction; Furthermore, we introduce an optimized beam search algorithm to guarantee the coherence and consistency of the generated content. REMARK-LLM is rigorously trained to encourage the preservation of semantic integrity in watermarked content, while ensuring effective watermark retrieval. Extensive evaluations on multiple unseen datasets highlight REMARK-LLM proficiency and transferability in inserting 2 times more signature bits into the same texts when compared to prior art, all while maintaining semantic integrity. Furthermore, REMARK-LLM exhibits better resilience against a spectrum of watermark detection and removal attacks.
XVTP3D: Cross-view Trajectory Prediction Using Shared 3D Queries for Autonomous Driving
Aug 17, 2023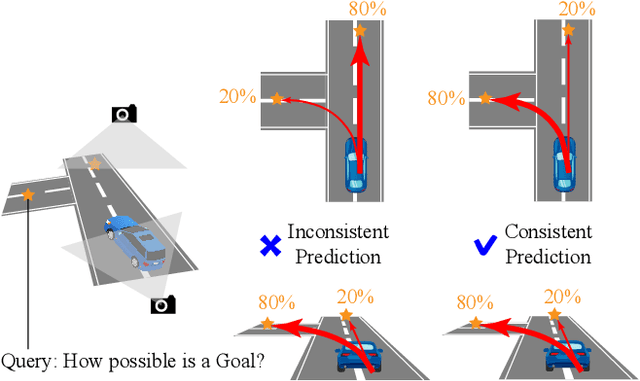

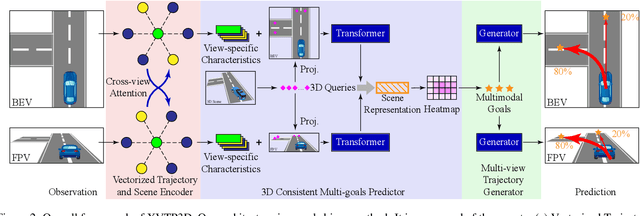

Trajectory prediction with uncertainty is a critical and challenging task for autonomous driving. Nowadays, we can easily access sensor data represented in multiple views. However, cross-view consistency has not been evaluated by the existing models, which might lead to divergences between the multimodal predictions from different views. It is not practical and effective when the network does not comprehend the 3D scene, which could cause the downstream module in a dilemma. Instead, we predicts multimodal trajectories while maintaining cross-view consistency. We presented a cross-view trajectory prediction method using shared 3D Queries (XVTP3D). We employ a set of 3D queries shared across views to generate multi-goals that are cross-view consistent. We also proposed a random mask method and coarse-to-fine cross-attention to capture robust cross-view features. As far as we know, this is the first work that introduces the outstanding top-down paradigm in BEV detection field to a trajectory prediction problem. The results of experiments on two publicly available datasets show that XVTP3D achieved state-of-the-art performance with consistent cross-view predictions.
SABRE: Robust Bayesian Peer-to-Peer Federated Learning
Aug 04, 2023We introduce SABRE, a novel framework for robust variational Bayesian peer-to-peer federated learning. We analyze the robustness of the known variational Bayesian peer-to-peer federated learning framework (BayP2PFL) against poisoning attacks and subsequently show that BayP2PFL is not robust against those attacks. The new SABRE aggregation methodology is then devised to overcome the limitations of the existing frameworks. SABRE works well in non-IID settings, does not require the majority of the benign nodes over the compromised ones, and even outperforms the baseline algorithm in benign settings. We theoretically prove the robustness of our algorithm against data / model poisoning attacks in a decentralized linear regression setting. Proof-of-Concept evaluations on benchmark data from image classification demonstrate the superiority of SABRE over the existing frameworks under various poisoning attacks.
Text Revealer: Private Text Reconstruction via Model Inversion Attacks against Transformers
Sep 21, 2022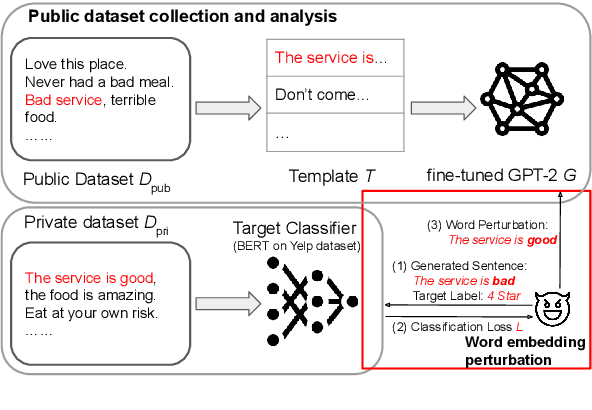

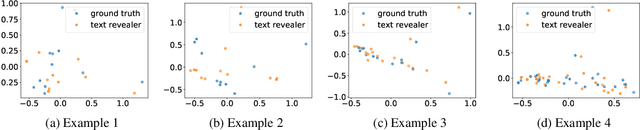
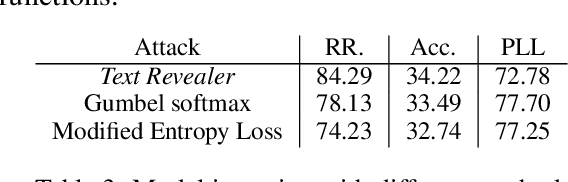
Text classification has become widely used in various natural language processing applications like sentiment analysis. Current applications often use large transformer-based language models to classify input texts. However, there is a lack of systematic study on how much private information can be inverted when publishing models. In this paper, we formulate \emph{Text Revealer} -- the first model inversion attack for text reconstruction against text classification with transformers. Our attacks faithfully reconstruct private texts included in training data with access to the target model. We leverage an external dataset and GPT-2 to generate the target domain-like fluent text, and then perturb its hidden state optimally with the feedback from the target model. Our extensive experiments demonstrate that our attacks are effective for datasets with different text lengths and can reconstruct private texts with accuracy.
Emergency-braking Distance Prediction using Deep Learning
Dec 03, 2021


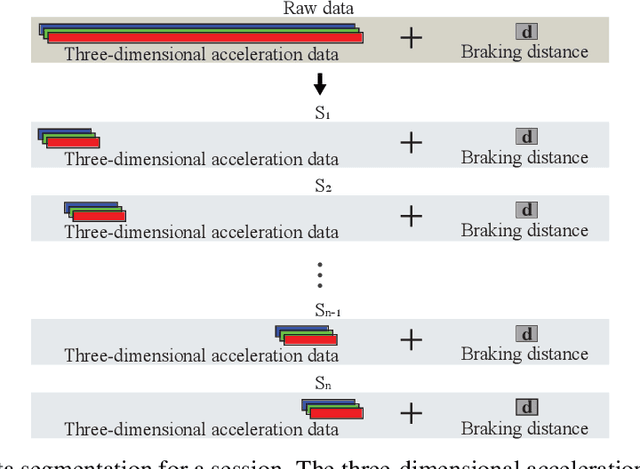
Predicting emergency-braking distance is important for the collision avoidance related features, which are the most essential and popular safety features for vehicles. In this study, we first gathered a large data set including a three-dimensional acceleration data and the corresponding emergency-braking distance. Using this data set, we propose a deep-learning model to predict emergency-braking distance, which only requires 0.25 seconds three-dimensional vehicle acceleration data before the break as input. We consider two road surfaces, our deep learning approach is robust to both road surfaces and have accuracy within 3 feet.
Improving Differentiable Architecture Search with a Generative Model
Nov 30, 2021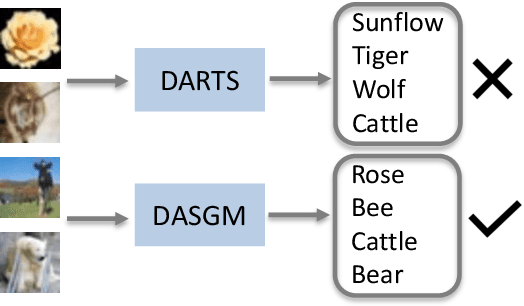



In differentiable neural architecture search (NAS) algorithms like DARTS, the training set used to update model weight and the validation set used to update model architectures are sampled from the same data distribution. Thus, the uncommon features in the dataset fail to receive enough attention during training. In this paper, instead of introducing more complex NAS algorithms, we explore the idea that adding quality synthesized datasets into training can help the classification model identify its weakness and improve recognition accuracy. We introduce a training strategy called ``Differentiable Architecture Search with a Generative Model(DASGM)." In DASGM, the training set is used to update the classification model weight, while a synthesized dataset is used to train its architecture. The generated images have different distributions from the training set, which can help the classification model learn better features to identify its weakness. We formulate DASGM into a multi-level optimization framework and develop an effective algorithm to solve it. Experiments on CIFAR-10, CIFAR-100, and ImageNet have demonstrated the effectiveness of DASGM. Code will be made available.
TreeGAN: Incorporating Class Hierarchy into Image Generation
Sep 16, 2020
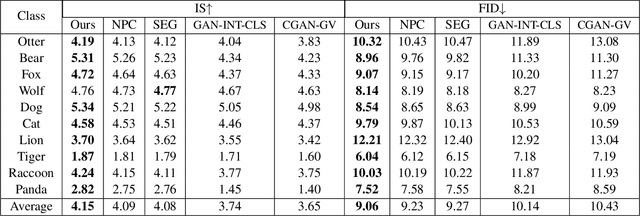
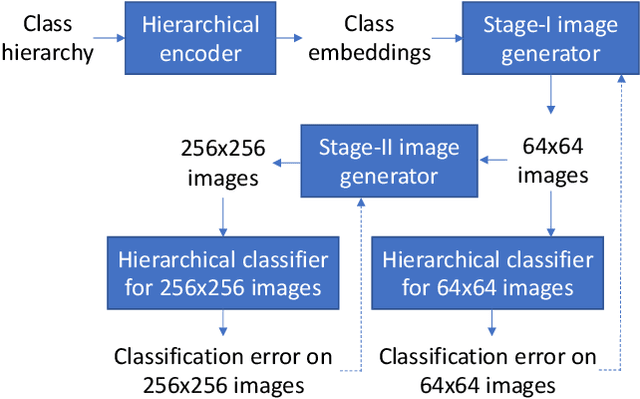

Conditional image generation (CIG) is a widely studied problem in computer vision and machine learning. Given a class, CIG takes the name of this class as input and generates a set of images that belong to this class. In existing CIG works, for different classes, their corresponding images are generated independently, without considering the relationship among classes. In real-world applications, the classes are organized into a hierarchy and their hierarchical relationships are informative for generating high-fidelity images. In this paper, we aim to leverage the class hierarchy for conditional image generation. We propose two ways of incorporating class hierarchy: prior control and post constraint. In prior control, we first encode the class hierarchy, then feed it as a prior into the conditional generator to generate images. In post constraint, after the images are generated, we measure their consistency with the class hierarchy and use the consistency score to guide the training of the generator. Based on these two ideas, we propose a TreeGAN model which consists of three modules: (1) a class hierarchy encoder (CHE) which takes the hierarchical structure of classes and their textual names as inputs and learns an embedding for each class; the embedding captures the hierarchical relationship among classes; (2) a conditional image generator (CIG) which takes the CHE-generated embedding of a class as input and generates a set of images belonging to this class; (3) a consistency checker which performs hierarchical classification on the generated images and checks whether the generated images are compatible with the class hierarchy; the consistency score is used to guide the CIG to generate hierarchy-compatible images. Experiments on various datasets demonstrate the effectiveness of our method.