 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS Sakshi
Do Vision-Language Models Understand Compound Nouns?
Mar 30, 2024
Open-vocabulary vision-language models (VLMs) like CLIP, trained using contrastive loss, have emerged as a promising new paradigm for text-to-image retrieval. However, do VLMs understand compound nouns (CNs) (e.g., lab coat) as well as they understand nouns (e.g., lab)? We curate Compun, a novel benchmark with 400 unique and commonly used CNs, to evaluate the effectiveness of VLMs in interpreting CNs. The Compun benchmark challenges a VLM for text-to-image retrieval where, given a text prompt with a CN, the task is to select the correct image that shows the CN among a pair of distractor images that show the constituent nouns that make up the CN. Next, we perform an in-depth analysis to highlight CLIPs' limited understanding of certain types of CNs. Finally, we present an alternative framework that moves beyond hand-written templates for text prompts widely used by CLIP-like models. We employ a Large Language Model to generate multiple diverse captions that include the CN as an object in the scene described by the caption. Our proposed method improves CN understanding of CLIP by 8.25% on Compun. Code and benchmark are available at: https://github.com/sonalkum/Compun
DALE: Generative Data Augmentation for Low-Resource Legal NLP
Oct 24, 2023We present DALE, a novel and effective generative Data Augmentation framework for low-resource LEgal NLP. DALE addresses the challenges existing frameworks pose in generating effective data augmentations of legal documents - legal language, with its specialized vocabulary and complex semantics, morphology, and syntax, does not benefit from data augmentations that merely rephrase the source sentence. To address this, DALE, built on an Encoder-Decoder Language Model, is pre-trained on a novel unsupervised text denoising objective based on selective masking - our masking strategy exploits the domain-specific language characteristics of templatized legal documents to mask collocated spans of text. Denoising these spans helps DALE acquire knowledge about legal concepts, principles, and language usage. Consequently, it develops the ability to generate coherent and diverse augmentations with novel contexts. Finally, DALE performs conditional generation to generate synthetic augmentations for low-resource Legal NLP tasks. We demonstrate the effectiveness of DALE on 13 datasets spanning 6 tasks and 4 low-resource settings. DALE outperforms all our baselines, including LLMs, qualitatively and quantitatively, with improvements of 1%-50%.
Speech Toxicity Analysis: A New Spoken Language Processing Task
Nov 06, 2021

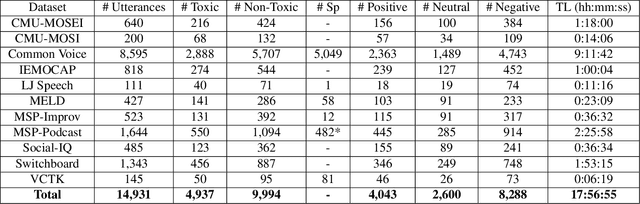
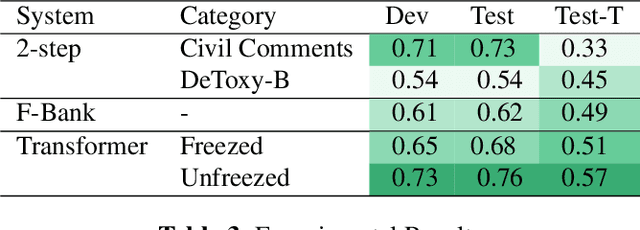
Toxic speech, also known as hate speech, is regarded as one of the crucial issues plaguing online social media today. Most recent work on toxic speech detection is constrained to the modality of text with no existing work on toxicity detection from spoken utterances. In this paper, we propose a new Spoken Language Processing task of detecting toxicity from spoken speech. We introduce DeToxy, the first publicly available toxicity annotated dataset for English speech, sourced from various openly available speech databases, consisting of over 2 million utterances. Finally, we also provide analysis on how a spoken speech corpus annotated for toxicity can help facilitate the development of E2E models which better capture various prosodic cues in speech, thereby boosting toxicity classification on spoken utterances.