 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSören Pirk
LAESI: Leaf Area Estimation with Synthetic Imagery
Mar 31, 2024
We introduce LAESI, a Synthetic Leaf Dataset of 100,000 synthetic leaf images on millimeter paper, each with semantic masks and surface area labels. This dataset provides a resource for leaf morphology analysis primarily aimed at beech and oak leaves. We evaluate the applicability of the dataset by training machine learning models for leaf surface area prediction and semantic segmentation, using real images for validation. Our validation shows that these models can be trained to predict leaf surface area with a relative error not greater than an average human annotator. LAESI also provides an efficient framework based on 3D procedural models and generative AI for the large-scale, controllable generation of data with potential further applications in agriculture and biology. We evaluate the inclusion of generative AI in our procedural data generation pipeline and show how data filtering based on annotation consistency results in datasets which allow training the highest performing vision models.
Generating Diverse Agricultural Data for Vision-Based Farming Applications
Mar 27, 2024



We present a specialized procedural model for generating synthetic agricultural scenes, focusing on soybean crops, along with various weeds. This model is capable of simulating distinct growth stages of these plants, diverse soil conditions, and randomized field arrangements under varying lighting conditions. The integration of real-world textures and environmental factors into the procedural generation process enhances the photorealism and applicability of the synthetic data. Our dataset includes 12,000 images with semantic labels, offering a comprehensive resource for computer vision tasks in precision agriculture, such as semantic segmentation for autonomous weed control. We validate our model's effectiveness by comparing the synthetic data against real agricultural images, demonstrating its potential to significantly augment training data for machine learning models in agriculture. This approach not only provides a cost-effective solution for generating high-quality, diverse data but also addresses specific needs in agricultural vision tasks that are not fully covered by general-purpose models.
A Lennard-Jones Layer for Distribution Normalization
Feb 05, 2024We introduce the Lennard-Jones layer (LJL) for the equalization of the density of 2D and 3D point clouds through systematically rearranging points without destroying their overall structure (distribution normalization). LJL simulates a dissipative process of repulsive and weakly attractive interactions between individual points by considering the nearest neighbor of each point at a given moment in time. This pushes the particles into a potential valley, reaching a well-defined stable configuration that approximates an equidistant sampling after the stabilization process. We apply LJLs to redistribute randomly generated point clouds into a randomized uniform distribution. Moreover, LJLs are embedded in the generation process of point cloud networks by adding them at later stages of the inference process. The improvements in 3D point cloud generation utilizing LJLs are evaluated qualitatively and quantitatively. Finally, we apply LJLs to improve the point distribution of a score-based 3D point cloud denoising network. In general, we demonstrate that LJLs are effective for distribution normalization which can be applied at negligible cost without retraining the given neural network.
Gazebo Plants: Simulating Plant-Robot Interaction with Cosserat Rods
Feb 04, 2024Robotic harvesting has the potential to positively impact agricultural productivity, reduce costs, improve food quality, enhance sustainability, and to address labor shortage. In the rapidly advancing field of agricultural robotics, the necessity of training robots in a virtual environment has become essential. Generating training data to automatize the underlying computer vision tasks such as image segmentation, object detection and classification, also heavily relies on such virtual environments as synthetic data is often required to overcome the shortage and lack of variety of real data sets. However, physics engines commonly employed within the robotics community, such as ODE, Simbody, Bullet, and DART, primarily support motion and collision interaction of rigid bodies. This inherent limitation hinders experimentation and progress in handling non-rigid objects such as plants and crops. In this contribution, we present a plugin for the Gazebo simulation platform based on Cosserat rods to model plant motion. It enables the simulation of plants and their interaction with the environment. We demonstrate that, using our plugin, users can conduct harvesting simulations in Gazebo by simulating a robotic arm picking fruits and achieve results comparable to real-world experiments.
Carve3D: Improving Multi-view Reconstruction Consistency for Diffusion Models with RL Finetuning
Dec 21, 2023Recent advancements in the text-to-3D task leverage finetuned text-to-image diffusion models to generate multi-view images, followed by NeRF reconstruction. Yet, existing supervised finetuned (SFT) diffusion models still suffer from multi-view inconsistency and the resulting NeRF artifacts. Although training longer with SFT improves consistency, it also causes distribution shift, which reduces diversity and realistic details. We argue that the SFT of multi-view diffusion models resembles the instruction finetuning stage of the LLM alignment pipeline and can benefit from RL finetuning (RLFT) methods. Essentially, RLFT methods optimize models beyond their SFT data distribution by using their own outputs, effectively mitigating distribution shift. To this end, we introduce Carve3D, a RLFT method coupled with the Multi-view Reconstruction Consistency (MRC) metric, to improve the consistency of multi-view diffusion models. To compute MRC on a set of multi-view images, we compare them with their corresponding renderings of the reconstructed NeRF at the same viewpoints. We validate the robustness of MRC with extensive experiments conducted under controlled inconsistency levels. We enhance the base RLFT algorithm to stabilize the training process, reduce distribution shift, and identify scaling laws. Through qualitative and quantitative experiments, along with a user study, we demonstrate Carve3D's improved multi-view consistency, the resulting superior NeRF reconstruction quality, and minimal distribution shift compared to longer SFT. Project webpage: https://desaixie.github.io/carve-3d.
DeepTree: Modeling Trees with Situated Latents
May 09, 2023



In this paper, we propose DeepTree, a novel method for modeling trees based on learning developmental rules for branching structures instead of manually defining them. We call our deep neural model situated latent because its behavior is determined by the intrinsic state -- encoded as a latent space of a deep neural model -- and by the extrinsic (environmental) data that is situated as the location in the 3D space and on the tree structure. We use a neural network pipeline to train a situated latent space that allows us to locally predict branch growth only based on a single node in the branch graph of a tree model. We use this representation to progressively develop new branch nodes, thereby mimicking the growth process of trees. Starting from a root node, a tree is generated by iteratively querying the neural network on the newly added nodes resulting in the branching structure of the whole tree. Our method enables generating a wide variety of tree shapes without the need to define intricate parameters that control their growth and behavior. Furthermore, we show that the situated latents can also be used to encode the environmental response of tree models, e.g., when trees grow next to obstacles. We validate the effectiveness of our method by measuring the similarity of our tree models and by procedurally generated ones based on a number of established metrics for tree form.
Instance Segmentation with Cross-Modal Consistency
Oct 14, 2022
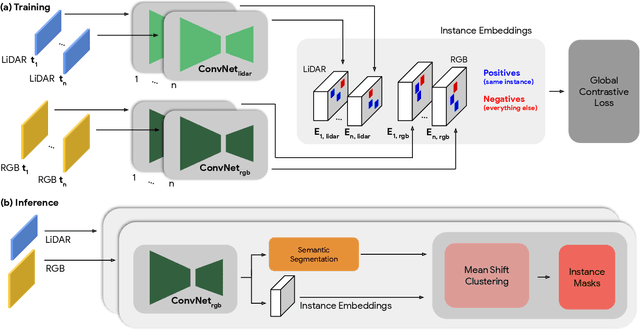

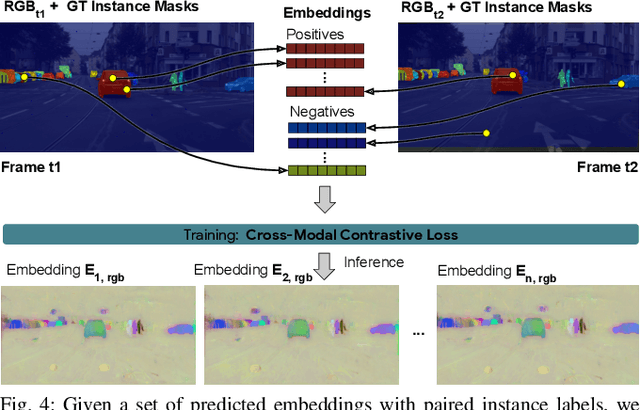
Segmenting object instances is a key task in machine perception, with safety-critical applications in robotics and autonomous driving. We introduce a novel approach to instance segmentation that jointly leverages measurements from multiple sensor modalities, such as cameras and LiDAR. Our method learns to predict embeddings for each pixel or point that give rise to a dense segmentation of the scene. Specifically, our technique applies contrastive learning to points in the scene both across sensor modalities and the temporal domain. We demonstrate that this formulation encourages the models to learn embeddings that are invariant to viewpoint variations and consistent across sensor modalities. We further demonstrate that the embeddings are stable over time as objects move around the scene. This not only provides stable instance masks, but can also provide valuable signals to downstream tasks, such as object tracking. We evaluate our method on the Cityscapes and KITTI-360 datasets. We further conduct a number of ablation studies, demonstrating benefits when applying additional inputs for the contrastive loss.
Gesture2Path: Imitation Learning for Gesture-aware Navigation
Sep 19, 2022

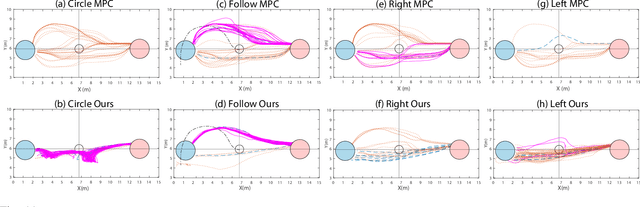

As robots increasingly enter human-centered environments, they must not only be able to navigate safely around humans, but also adhere to complex social norms. Humans often rely on non-verbal communication through gestures and facial expressions when navigating around other people, especially in densely occupied spaces. Consequently, robots also need to be able to interpret gestures as part of solving social navigation tasks. To this end, we present Gesture2Path, a novel social navigation approach that combines image-based imitation learning with model-predictive control. Gestures are interpreted based on a neural network that operates on streams of images, while we use a state-of-the-art model predictive control algorithm to solve point-to-point navigation tasks. We deploy our method on real robots and showcase the effectiveness of our approach for the four gestures-navigation scenarios: left/right, follow me, and make a circle. Our experiments indicate that our method is able to successfully interpret complex human gestures and to use them as a signal to generate socially compliant trajectories for navigation tasks. We validated our method based on in-situ ratings of participants interacting with the robots.
A Protocol for Validating Social Navigation Policies
Apr 11, 2022
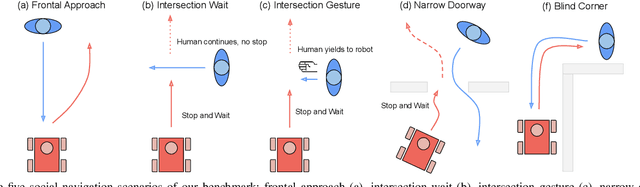


Enabling socially acceptable behavior for situated agents is a major goal of recent robotics research. Robots should not only operate safely around humans, but also abide by complex social norms. A key challenge for developing socially-compliant policies is measuring the quality of their behavior. Social behavior is enormously complex, making it difficult to create reliable metrics to gauge the performance of algorithms. In this paper, we propose a protocol for social navigation benchmarking that defines a set of canonical social navigation scenarios and an in-situ metric for evaluating performance on these scenarios using questionnaires. Our experiments show this protocol is realistic, scalable, and repeatable across runs and physical spaces. Our protocol can be replicated verbatim or it can be used to define a social navigation benchmark for novel scenarios. Our goal is to introduce a protocol for benchmarking social scenarios that is homogeneous and comparable.
Procedural Urban Forestry
Aug 14, 2020



The placement of vegetation plays a central role in the realism of virtual scenes. We introduce procedural placement models (PPMs) for vegetation in urban layouts. PPMs are environmentally sensitive to city geometry and allow identifying plausible plant positions based on structural and functional zones in an urban layout. PPMs can either be directly used by defining their parameters or can be learned from satellite images and land register data. Together with approaches for generating buildings and trees, this allows us to populate urban landscapes with complex 3D vegetation. The effectiveness of our framework is shown through examples of large-scale city scenes and close-ups of individually grown tree models; we also validate it by a perceptual user study.