 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamuel Tan
Re-embedding data to strengthen recovery guarantees of clustering
Jan 26, 2023
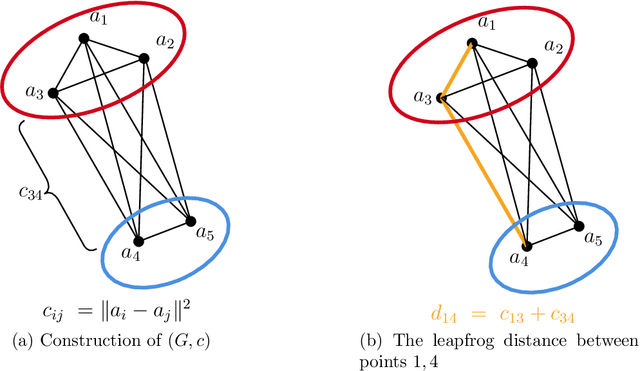

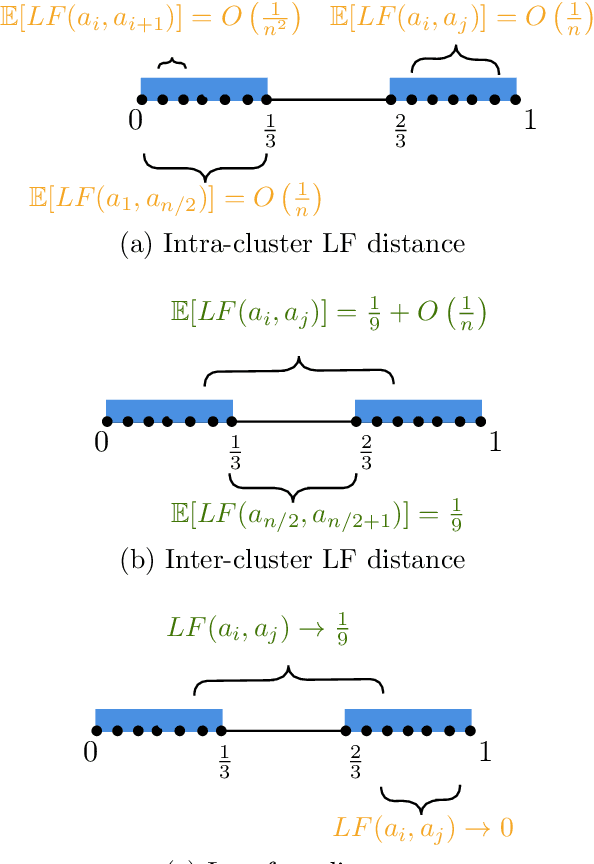
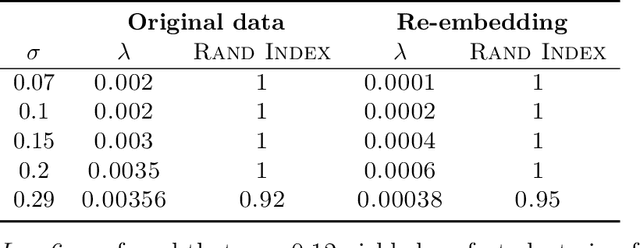
We propose a clustering method that involves chaining four known techniques into a pipeline yielding an algorithm with stronger recovery guarantees than any of the four components separately. Given $n$ points in $\mathbb R^d$, the first component of our pipeline, which we call leapfrog distances, is reminiscent of density-based clustering, yielding an $n\times n$ distance matrix. The leapfrog distances are then translated to new embeddings using multidimensional scaling and spectral methods, two other known techniques, yielding new embeddings of the $n$ points in $\mathbb R^{d'}$, where $d'$ satisfies $d'\ll d$ in general. Finally, sum-of-norms (SON) clustering is applied to the re-embedded points. Although the fourth step (SON clustering) can in principle be replaced by any other clustering method, our focus is on provable guarantees of recovery of underlying structure. Therefore, we establish that the re-embedding improves recovery SON clustering, since SON clustering is a well-studied method that already has provable guarantees.
Regret Bounds and Experimental Design for Estimate-then-Optimize
Oct 27, 2022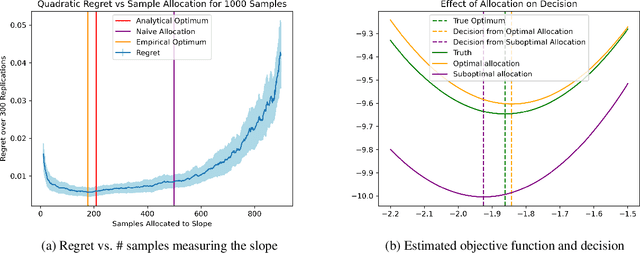

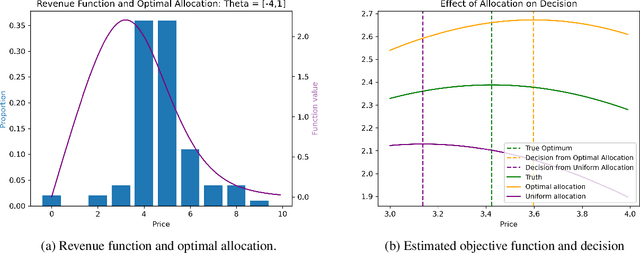
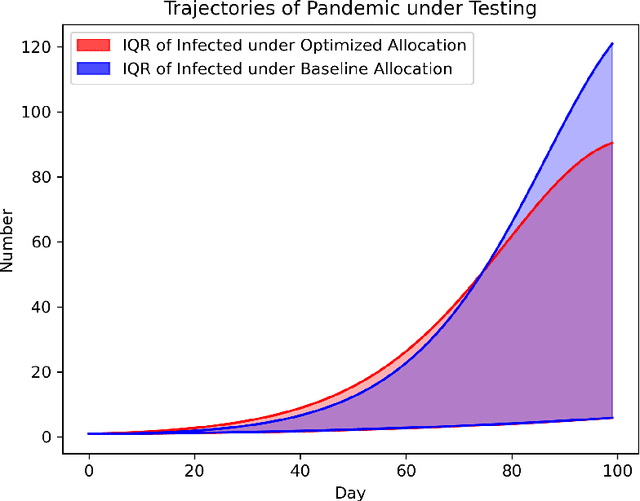
In practical applications, data is used to make decisions in two steps: estimation and optimization. First, a machine learning model estimates parameters for a structural model relating decisions to outcomes. Second, a decision is chosen to optimize the structural model's predicted outcome as if its parameters were correctly estimated. Due to its flexibility and simple implementation, this ``estimate-then-optimize'' approach is often used for data-driven decision-making. Errors in the estimation step can lead estimate-then-optimize to sub-optimal decisions that result in regret, i.e., a difference in value between the decision made and the best decision available with knowledge of the structural model's parameters. We provide a novel bound on this regret for smooth and unconstrained optimization problems. Using this bound, in settings where estimated parameters are linear transformations of sub-Gaussian random vectors, we provide a general procedure for experimental design to minimize the regret resulting from estimate-then-optimize. We demonstrate our approach on simple examples and a pandemic control application.