 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSangyoun Lee
SMURF: Continuous Dynamics for Motion-Deblurring Radiance Fields
Mar 12, 2024
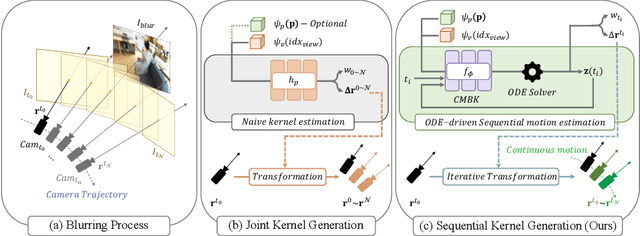

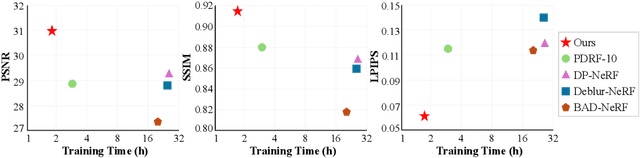
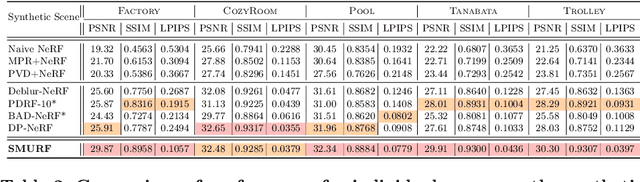
Neural radiance fields (NeRF) has attracted considerable attention for their exceptional ability in synthesizing novel views with high fidelity. However, the presence of motion blur, resulting from slight camera movements during extended shutter exposures, poses a significant challenge, potentially compromising the quality of the reconstructed 3D scenes. While recent studies have addressed this issue, they do not consider the continuous dynamics of camera movements during image acquisition, leading to inaccurate scene reconstruction. Additionally, these methods are plagued by slow training and rendering speed. To effectively handle these issues, we propose sequential motion understanding radiance fields (SMURF), a novel approach that employs neural ordinary differential equation (Neural-ODE) to model continuous camera motion and leverages the explicit volumetric representation method for faster training and robustness to motion-blurred input images. The core idea of the SMURF is continuous motion blurring kernel (CMBK), a unique module designed to model a continuous camera movements for processing blurry inputs. Our model, rigorously evaluated against benchmark datasets, demonstrates state-of-the-art performance both quantitatively and qualitatively.
FIMP: Future Interaction Modeling for Multi-Agent Motion Prediction
Jan 29, 2024Multi-agent motion prediction is a crucial concern in autonomous driving, yet it remains a challenge owing to the ambiguous intentions of dynamic agents and their intricate interactions. Existing studies have attempted to capture interactions between road entities by using the definite data in history timesteps, as future information is not available and involves high uncertainty. However, without sufficient guidance for capturing future states of interacting agents, they frequently produce unrealistic trajectory overlaps. In this work, we propose Future Interaction modeling for Motion Prediction (FIMP), which captures potential future interactions in an end-to-end manner. FIMP adopts a future decoder that implicitly extracts the potential future information in an intermediate feature-level, and identifies the interacting entity pairs through future affinity learning and top-k filtering strategy. Experiments show that our future interaction modeling improves the performance remarkably, leading to superior performance on the Argoverse motion forecasting benchmark.
Synchronizing Vision and Language: Bidirectional Token-Masking AutoEncoder for Referring Image Segmentation
Nov 29, 2023Referring Image Segmentation (RIS) aims to segment target objects expressed in natural language within a scene at the pixel level. Various recent RIS models have achieved state-of-the-art performance by generating contextual tokens to model multimodal features from pretrained encoders and effectively fusing them using transformer-based cross-modal attention. While these methods match language features with image features to effectively identify likely target objects, they often struggle to correctly understand contextual information in complex and ambiguous sentences and scenes. To address this issue, we propose a novel bidirectional token-masking autoencoder (BTMAE) inspired by the masked autoencoder (MAE). The proposed model learns the context of image-to-language and language-to-image by reconstructing missing features in both image and language features at the token level. In other words, this approach involves mutually complementing across the features of images and language, with a focus on enabling the network to understand interconnected deep contextual information between the two modalities. This learning method enhances the robustness of RIS performance in complex sentences and scenes. Our BTMAE achieves state-of-the-art performance on three popular datasets, and we demonstrate the effectiveness of the proposed method through various ablation studies.
Treating Motion as Option with Output Selection for Unsupervised Video Object Segmentation
Sep 26, 2023Unsupervised video object segmentation (VOS) is a task that aims to detect the most salient object in a video without external guidance about the object. To leverage the property that salient objects usually have distinctive movements compared to the background, recent methods collaboratively use motion cues extracted from optical flow maps with appearance cues extracted from RGB images. However, as optical flow maps are usually very relevant to segmentation masks, the network is easy to be learned overly dependent on the motion cues during network training. As a result, such two-stream approaches are vulnerable to confusing motion cues, making their prediction unstable. To relieve this issue, we design a novel motion-as-option network by treating motion cues as optional. During network training, RGB images are randomly provided to the motion encoder instead of optical flow maps, to implicitly reduce motion dependency of the network. As the learned motion encoder can deal with both RGB images and optical flow maps, two different predictions can be generated depending on which source information is used as motion input. In order to fully exploit this property, we also propose an adaptive output selection algorithm to adopt optimal prediction result at test time. Our proposed approach affords state-of-the-art performance on all public benchmark datasets, even maintaining real-time inference speed.
Adaptive Graph Convolution Module for Salient Object Detection
Mar 17, 2023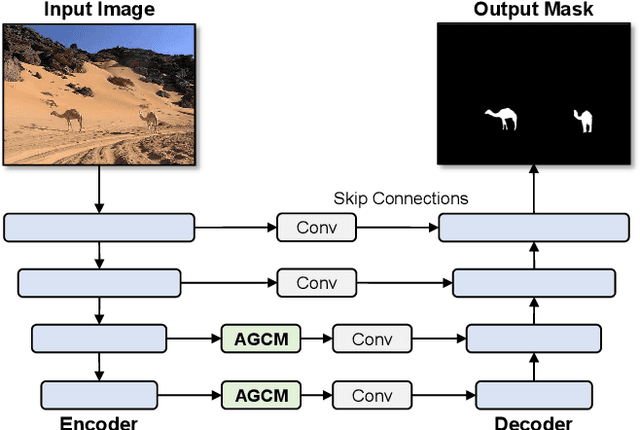
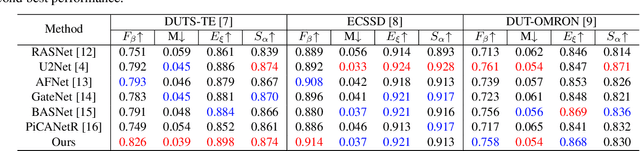
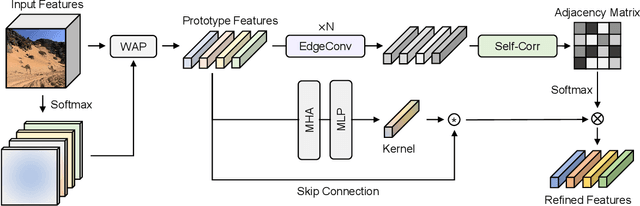
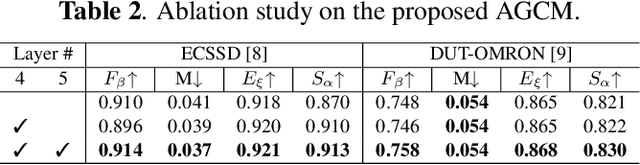
Salient object detection (SOD) is a task that involves identifying and segmenting the most visually prominent object in an image. Existing solutions can accomplish this use a multi-scale feature fusion mechanism to detect the global context of an image. However, as there is no consideration of the structures in the image nor the relations between distant pixels, conventional methods cannot deal with complex scenes effectively. In this paper, we propose an adaptive graph convolution module (AGCM) to overcome these limitations. Prototype features are initially extracted from the input image using a learnable region generation layer that spatially groups features in the image. The prototype features are then refined by propagating information between them based on a graph architecture, where each feature is regarded as a node. Experimental results show that the proposed AGCM dramatically improves the SOD performance both quantitatively and quantitatively.
Guided Slot Attention for Unsupervised Video Object Segmentation
Mar 15, 2023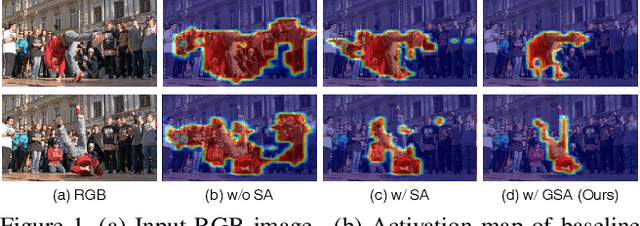
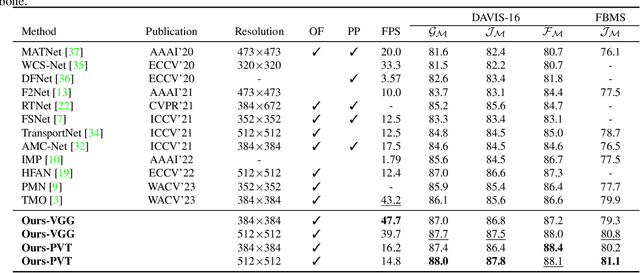
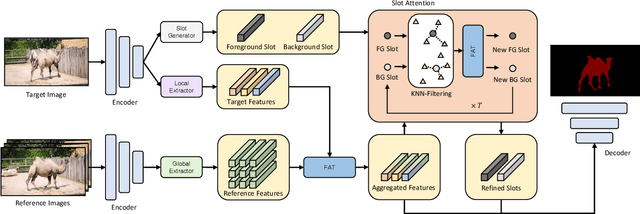
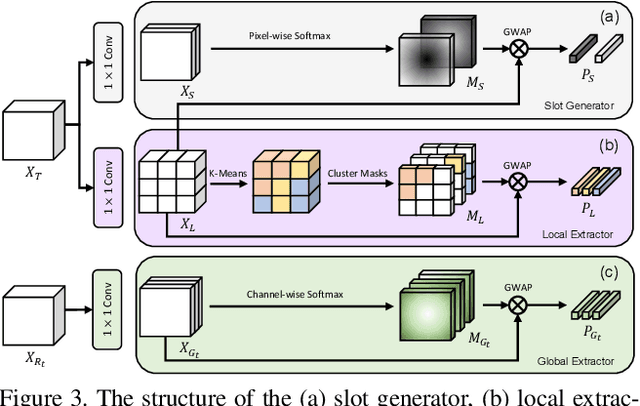
Unsupervised video object segmentation aims to segment the most prominent object in a video sequence. However, the existence of complex backgrounds and multiple foreground objects make this task challenging. To address this issue, we propose a guided slot attention network to reinforce spatial structural information and obtain better foreground--background separation. The foreground and background slots, which are initialized with query guidance, are iteratively refined based on interactions with template information. Furthermore, to improve slot--template interaction and effectively fuse global and local features in the target and reference frames, K-nearest neighbors filtering and a feature aggregation transformer are introduced. The proposed model achieves state-of-the-art performance on two popular datasets. Additionally, we demonstrate the robustness of the proposed model in challenging scenes through various comparative experiments.
TSANET: Temporal and Scale Alignment for Unsupervised Video Object Segmentation
Mar 08, 2023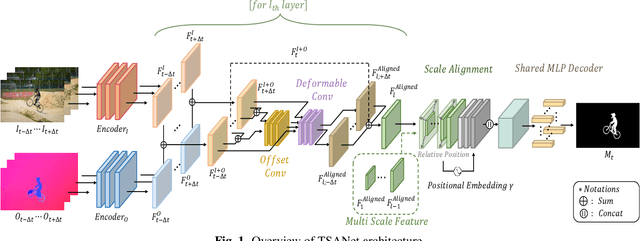
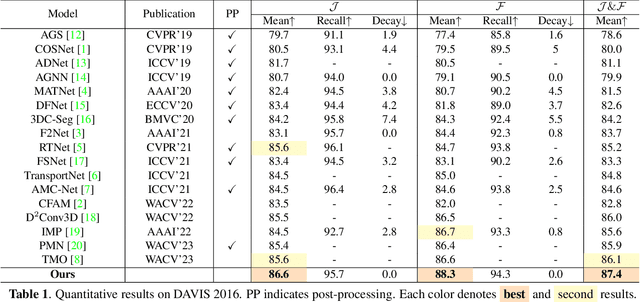

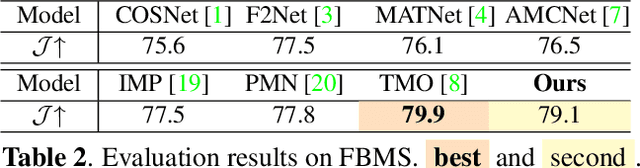
Unsupervised Video Object Segmentation (UVOS) refers to the challenging task of segmenting the prominent object in videos without manual guidance. In other words, the network detects the accurate region of the target object in a sequence of RGB frames without prior knowledge. In recent works, two approaches for UVOS have been discussed that can be divided into: appearance and appearance-motion based methods. Appearance based methods utilize the correlation information of inter-frames to capture target object that commonly appears in a sequence. However, these methods does not consider the motion of target object due to exploit the correlation information between randomly paired frames. Appearance-motion based methods, on the other hand, fuse the appearance features from RGB frames with the motion features from optical flow. Motion cue provides useful information since salient objects typically show distinctive motion in a sequence. However, these approaches have the limitation that the dependency on optical flow is dominant. In this paper, we propose a novel framework for UVOS that can address aforementioned limitations of two approaches in terms of both time and scale. Temporal Alignment Fusion aligns the saliency information of adjacent frames with the target frame to leverage the information of adjacent frames. Scale Alignment Decoder predicts the target object mask precisely by aggregating differently scaled feature maps via continuous mapping with implicit neural representation. We present experimental results on public benchmark datasets, DAVIS 2016 and FBMS, which demonstrate the effectiveness of our method. Furthermore, we outperform the state-of-the-art methods on DAVIS 2016.
One-Shot Video Inpainting
Feb 28, 2023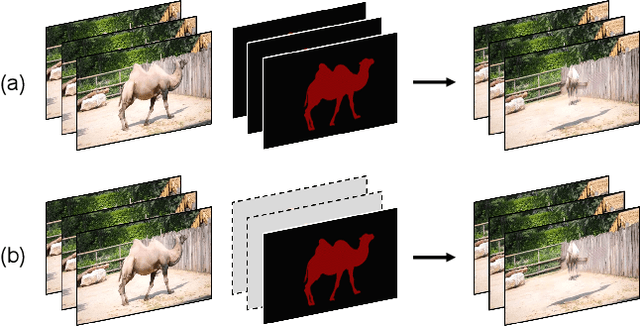

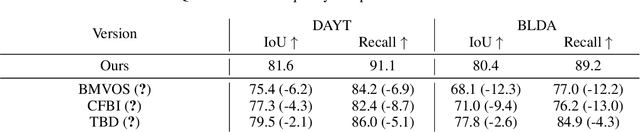

Recently, removing objects from videos and filling in the erased regions using deep video inpainting (VI) algorithms has attracted considerable attention. Usually, a video sequence and object segmentation masks for all frames are required as the input for this task. However, in real-world applications, providing segmentation masks for all frames is quite difficult and inefficient. Therefore, we deal with VI in a one-shot manner, which only takes the initial frame's object mask as its input. Although we can achieve that using naive combinations of video object segmentation (VOS) and VI methods, they are sub-optimal and generally cause critical errors. To address that, we propose a unified pipeline for one-shot video inpainting (OSVI). By jointly learning mask prediction and video completion in an end-to-end manner, the results can be optimal for the entire task instead of each separate module. Additionally, unlike the two stage methods that use the predicted masks as ground truth cues, our method is more reliable because the predicted masks can be used as the network's internal guidance. On the synthesized datasets for OSVI, our proposed method outperforms all others both quantitatively and qualitatively.
Two-stream Decoder Feature Normality Estimating Network for Industrial Anomaly Detection
Feb 20, 2023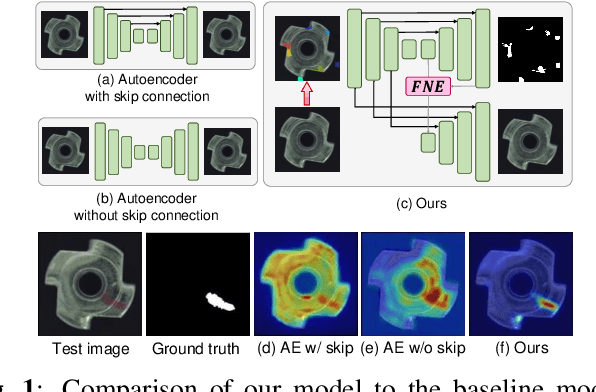

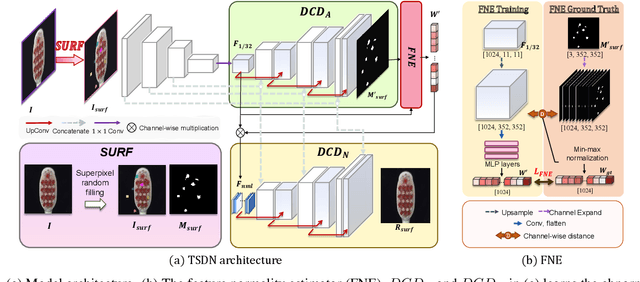
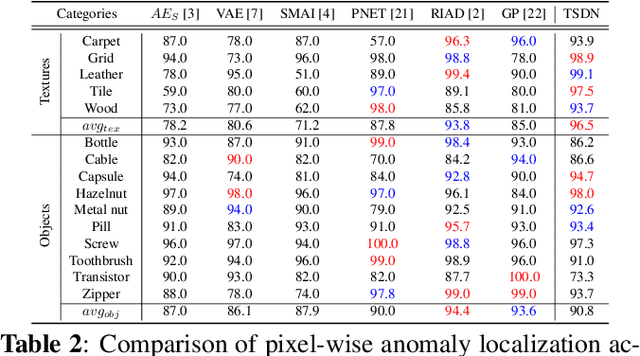
Image reconstruction-based anomaly detection has recently been in the spotlight because of the difficulty of constructing anomaly datasets. These approaches work by learning to model normal features without seeing abnormal samples during training and then discriminating anomalies at test time based on the reconstructive errors. However, these models have limitations in reconstructing the abnormal samples due to their indiscriminate conveyance of features. Moreover, these approaches are not explicitly optimized for distinguishable anomalies. To address these problems, we propose a two-stream decoder network (TSDN), designed to learn both normal and abnormal features. Additionally, we propose a feature normality estimator (FNE) to eliminate abnormal features and prevent high-quality reconstruction of abnormal regions. Evaluation on a standard benchmark demonstrated performance better than state-of-the-art models.
Feature Disentanglement Learning with Switching and Aggregation for Video-based Person Re-Identification
Dec 16, 2022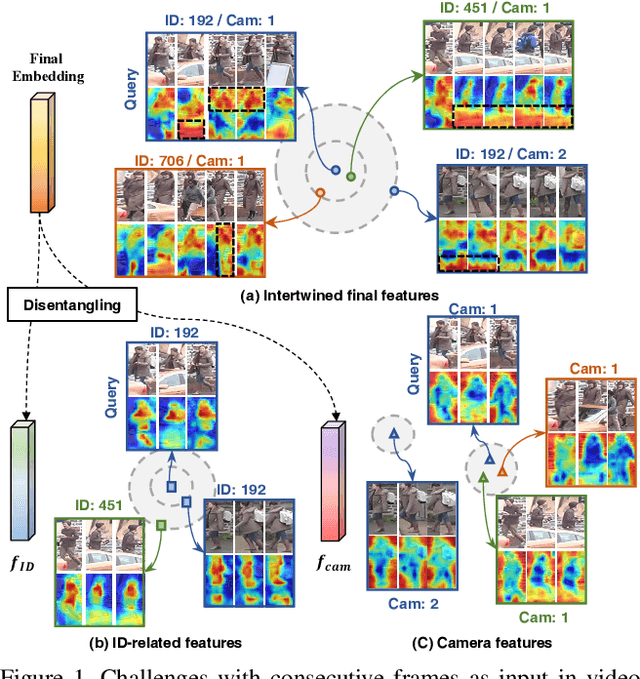
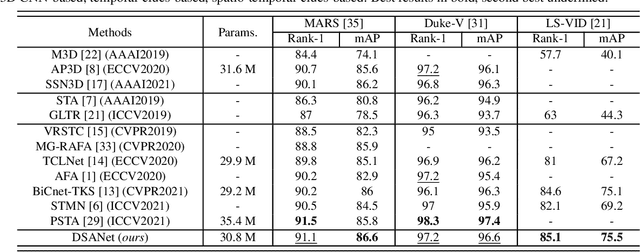
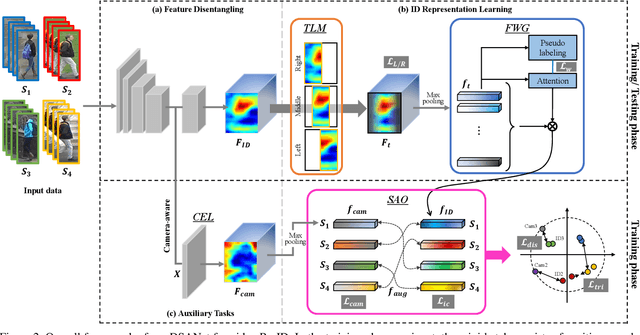

In video person re-identification (Re-ID), the network must consistently extract features of the target person from successive frames. Existing methods tend to focus only on how to use temporal information, which often leads to networks being fooled by similar appearances and same backgrounds. In this paper, we propose a Disentanglement and Switching and Aggregation Network (DSANet), which segregates the features representing identity and features based on camera characteristics, and pays more attention to ID information. We also introduce an auxiliary task that utilizes a new pair of features created through switching and aggregation to increase the network's capability for various camera scenarios. Furthermore, we devise a Target Localization Module (TLM) that extracts robust features against a change in the position of the target according to the frame flow and a Frame Weight Generation (FWG) that reflects temporal information in the final representation. Various loss functions for disentanglement learning are designed so that each component of the network can cooperate while satisfactorily performing its own role. Quantitative and qualitative results from extensive experiments demonstrate the superiority of DSANet over state-of-the-art methods on three benchmark datasets.