 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSanja Fidler
RefFusion: Reference Adapted Diffusion Models for 3D Scene Inpainting
Apr 16, 2024
Neural reconstruction approaches are rapidly emerging as the preferred representation for 3D scenes, but their limited editability is still posing a challenge. In this work, we propose an approach for 3D scene inpainting -- the task of coherently replacing parts of the reconstructed scene with desired content. Scene inpainting is an inherently ill-posed task as there exist many solutions that plausibly replace the missing content. A good inpainting method should therefore not only enable high-quality synthesis but also a high degree of control. Based on this observation, we focus on enabling explicit control over the inpainted content and leverage a reference image as an efficient means to achieve this goal. Specifically, we introduce RefFusion, a novel 3D inpainting method based on a multi-scale personalization of an image inpainting diffusion model to the given reference view. The personalization effectively adapts the prior distribution to the target scene, resulting in a lower variance of score distillation objective and hence significantly sharper details. Our framework achieves state-of-the-art results for object removal while maintaining high controllability. We further demonstrate the generality of our formulation on other downstream tasks such as object insertion, scene outpainting, and sparse view reconstruction.
Can Feedback Enhance Semantic Grounding in Large Vision-Language Models?
Apr 09, 2024Enhancing semantic grounding abilities in Vision-Language Models (VLMs) often involves collecting domain-specific training data, refining the network architectures, or modifying the training recipes. In this work, we venture into an orthogonal direction and explore whether VLMs can improve their semantic grounding by "receiving" feedback, without requiring in-domain data, fine-tuning, or modifications to the network architectures. We systematically analyze this hypothesis using a feedback mechanism composed of a binary signal. We find that if prompted appropriately, VLMs can utilize feedback both in a single step and iteratively, showcasing the potential of feedback as an alternative technique to improve grounding in internet-scale VLMs. Furthermore, VLMs, like LLMs, struggle to self-correct errors out-of-the-box. However, we find that this issue can be mitigated via a binary verification mechanism. Finally, we explore the potential and limitations of amalgamating these findings and applying them iteratively to automatically enhance VLMs' grounding performance, showing grounding accuracy consistently improves using automated feedback across all models in all settings investigated. Overall, our iterative framework improves semantic grounding in VLMs by more than 15 accuracy points under noise-free feedback and up to 5 accuracy points under a simple automated binary verification mechanism. The project website is hosted at https://andrewliao11.github.io/vlms_feedback
LATTE3D: Large-scale Amortized Text-To-Enhanced3D Synthesis
Mar 22, 2024Recent text-to-3D generation approaches produce impressive 3D results but require time-consuming optimization that can take up to an hour per prompt. Amortized methods like ATT3D optimize multiple prompts simultaneously to improve efficiency, enabling fast text-to-3D synthesis. However, they cannot capture high-frequency geometry and texture details and struggle to scale to large prompt sets, so they generalize poorly. We introduce LATTE3D, addressing these limitations to achieve fast, high-quality generation on a significantly larger prompt set. Key to our method is 1) building a scalable architecture and 2) leveraging 3D data during optimization through 3D-aware diffusion priors, shape regularization, and model initialization to achieve robustness to diverse and complex training prompts. LATTE3D amortizes both neural field and textured surface generation to produce highly detailed textured meshes in a single forward pass. LATTE3D generates 3D objects in 400ms, and can be further enhanced with fast test-time optimization.
Augmented Reality based Simulated Data (ARSim) with multi-view consistency for AV perception networks
Mar 22, 2024Detecting a diverse range of objects under various driving scenarios is essential for the effectiveness of autonomous driving systems. However, the real-world data collected often lacks the necessary diversity presenting a long-tail distribution. Although synthetic data has been utilized to overcome this issue by generating virtual scenes, it faces hurdles such as a significant domain gap and the substantial efforts required from 3D artists to create realistic environments. To overcome these challenges, we present ARSim, a fully automated, comprehensive, modular framework designed to enhance real multi-view image data with 3D synthetic objects of interest. The proposed method integrates domain adaptation and randomization strategies to address covariate shift between real and simulated data by inferring essential domain attributes from real data and employing simulation-based randomization for other attributes. We construct a simplified virtual scene using real data and strategically place 3D synthetic assets within it. Illumination is achieved by estimating light distribution from multiple images capturing the surroundings of the vehicle. Camera parameters from real data are employed to render synthetic assets in each frame. The resulting augmented multi-view consistent dataset is used to train a multi-camera perception network for autonomous vehicles. Experimental results on various AV perception tasks demonstrate the superior performance of networks trained on the augmented dataset.
EmerDiff: Emerging Pixel-level Semantic Knowledge in Diffusion Models
Jan 22, 2024Diffusion models have recently received increasing research attention for their remarkable transfer abilities in semantic segmentation tasks. However, generating fine-grained segmentation masks with diffusion models often requires additional training on annotated datasets, leaving it unclear to what extent pre-trained diffusion models alone understand the semantic relations of their generated images. To address this question, we leverage the semantic knowledge extracted from Stable Diffusion (SD) and aim to develop an image segmentor capable of generating fine-grained segmentation maps without any additional training. The primary difficulty stems from the fact that semantically meaningful feature maps typically exist only in the spatially lower-dimensional layers, which poses a challenge in directly extracting pixel-level semantic relations from these feature maps. To overcome this issue, our framework identifies semantic correspondences between image pixels and spatial locations of low-dimensional feature maps by exploiting SD's generation process and utilizes them for constructing image-resolution segmentation maps. In extensive experiments, the produced segmentation maps are demonstrated to be well delineated and capture detailed parts of the images, indicating the existence of highly accurate pixel-level semantic knowledge in diffusion models.
Align Your Gaussians: Text-to-4D with Dynamic 3D Gaussians and Composed Diffusion Models
Jan 03, 2024Text-guided diffusion models have revolutionized image and video generation and have also been successfully used for optimization-based 3D object synthesis. Here, we instead focus on the underexplored text-to-4D setting and synthesize dynamic, animated 3D objects using score distillation methods with an additional temporal dimension. Compared to previous work, we pursue a novel compositional generation-based approach, and combine text-to-image, text-to-video, and 3D-aware multiview diffusion models to provide feedback during 4D object optimization, thereby simultaneously enforcing temporal consistency, high-quality visual appearance and realistic geometry. Our method, called Align Your Gaussians (AYG), leverages dynamic 3D Gaussian Splatting with deformation fields as 4D representation. Crucial to AYG is a novel method to regularize the distribution of the moving 3D Gaussians and thereby stabilize the optimization and induce motion. We also propose a motion amplification mechanism as well as a new autoregressive synthesis scheme to generate and combine multiple 4D sequences for longer generation. These techniques allow us to synthesize vivid dynamic scenes, outperform previous work qualitatively and quantitatively and achieve state-of-the-art text-to-4D performance. Due to the Gaussian 4D representation, different 4D animations can be seamlessly combined, as we demonstrate. AYG opens up promising avenues for animation, simulation and digital content creation as well as synthetic data generation.
Compact Neural Graphics Primitives with Learned Hash Probing
Dec 28, 2023Neural graphics primitives are faster and achieve higher quality when their neural networks are augmented by spatial data structures that hold trainable features arranged in a grid. However, existing feature grids either come with a large memory footprint (dense or factorized grids, trees, and hash tables) or slow performance (index learning and vector quantization). In this paper, we show that a hash table with learned probes has neither disadvantage, resulting in a favorable combination of size and speed. Inference is faster than unprobed hash tables at equal quality while training is only 1.2-2.6x slower, significantly outperforming prior index learning approaches. We arrive at this formulation by casting all feature grids into a common framework: they each correspond to a lookup function that indexes into a table of feature vectors. In this framework, the lookup functions of existing data structures can be combined by simple arithmetic combinations of their indices, resulting in Pareto optimal compression and speed.
Trajeglish: Learning the Language of Driving Scenarios
Dec 07, 2023A longstanding challenge for self-driving development is simulating dynamic driving scenarios seeded from recorded driving logs. In pursuit of this functionality, we apply tools from discrete sequence modeling to model how vehicles, pedestrians and cyclists interact in driving scenarios. Using a simple data-driven tokenization scheme, we discretize trajectories to centimeter-level resolution using a small vocabulary. We then model the multi-agent sequence of motion tokens with a GPT-like encoder-decoder that is autoregressive in time and takes into account intra-timestep interaction between agents. Scenarios sampled from our model exhibit state-of-the-art realism; our model tops the Waymo Sim Agents Benchmark, surpassing prior work along the realism meta metric by 3.3% and along the interaction metric by 9.9%. We ablate our modeling choices in full autonomy and partial autonomy settings, and show that the representations learned by our model can quickly be adapted to improve performance on nuScenes. We additionally evaluate the scalability of our model with respect to parameter count and dataset size, and use density estimates from our model to quantify the saliency of context length and intra-timestep interaction for the traffic modeling task.
XCube ($\mathcal{X}^3$): Large-Scale 3D Generative Modeling using Sparse Voxel Hierarchies
Dec 06, 2023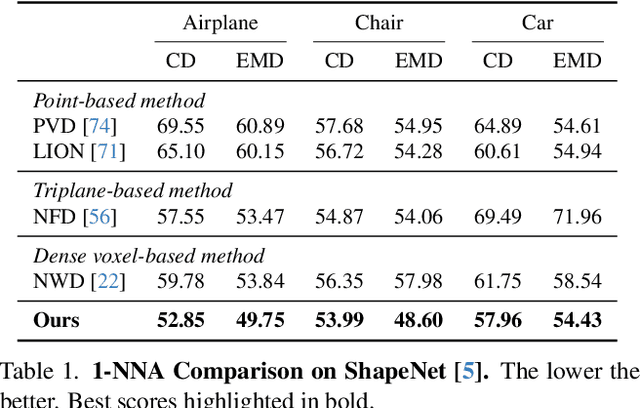
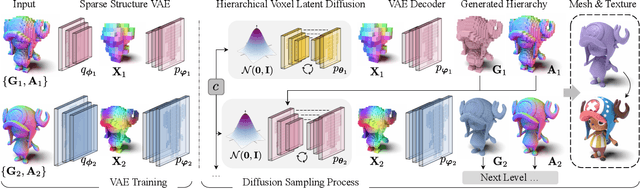

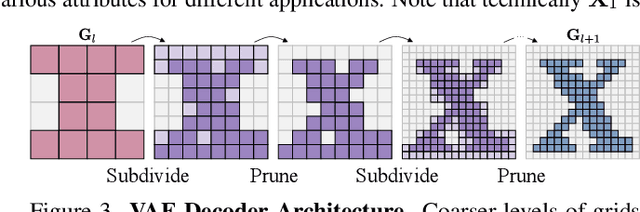
We present $\mathcal{X}^3$ (pronounced XCube), a novel generative model for high-resolution sparse 3D voxel grids with arbitrary attributes. Our model can generate millions of voxels with a finest effective resolution of up to $1024^3$ in a feed-forward fashion without time-consuming test-time optimization. To achieve this, we employ a hierarchical voxel latent diffusion model which generates progressively higher resolution grids in a coarse-to-fine manner using a custom framework built on the highly efficient VDB data structure. Apart from generating high-resolution objects, we demonstrate the effectiveness of XCube on large outdoor scenes at scales of 100m$\times$100m with a voxel size as small as 10cm. We observe clear qualitative and quantitative improvements over past approaches. In addition to unconditional generation, we show that our model can be used to solve a variety of tasks such as user-guided editing, scene completion from a single scan, and text-to-3D. More results and details can be found at https://research.nvidia.com/labs/toronto-ai/xcube/.